Transformers库(4)—— Model
- 首发链接:Transformers库(4)—— Model
- Hugging Face 是一家在 AI 领域具有重要影响力的科技公司,他们的开源工具和社区建设为NLP研究和开发提供了强大的支持。它们拥有当前最活跃、最受关注、影响力最大的 NLP 社区,最新最强的 NLP 模型大多在这里发布和开源。该社区也提供了丰富的教程、文档和示例代码,帮助用户快速上手并深入理解各类 Transformer 模型和 NLP 技术
- Transformers 库是 Hugging Face 最著名的贡献之一,它最初是 Transformer 模型的 pytorch 复现库,随着不断建设,至今已经成为 NLP 领域最重要,影响最大的基础设施之一。该库提供了大量预训练的模型,涵盖了多种语言和任务,成为当今大模型工程实现的主流标准,换句话说,如果你正在开发一个大模型,那么按 Transformer 库的代码格式进行工程实现、将 check point 打包成 hugging face 格式开源到社区,对于推广你的工作有很大的助力作用。本系列文章将介绍 Transformers 库的基本使用方法
- 参考:
1. Transformer Model
1.1 基本架构
- Transformer model 代表了以 Transformer 为基础的一系列模型
-
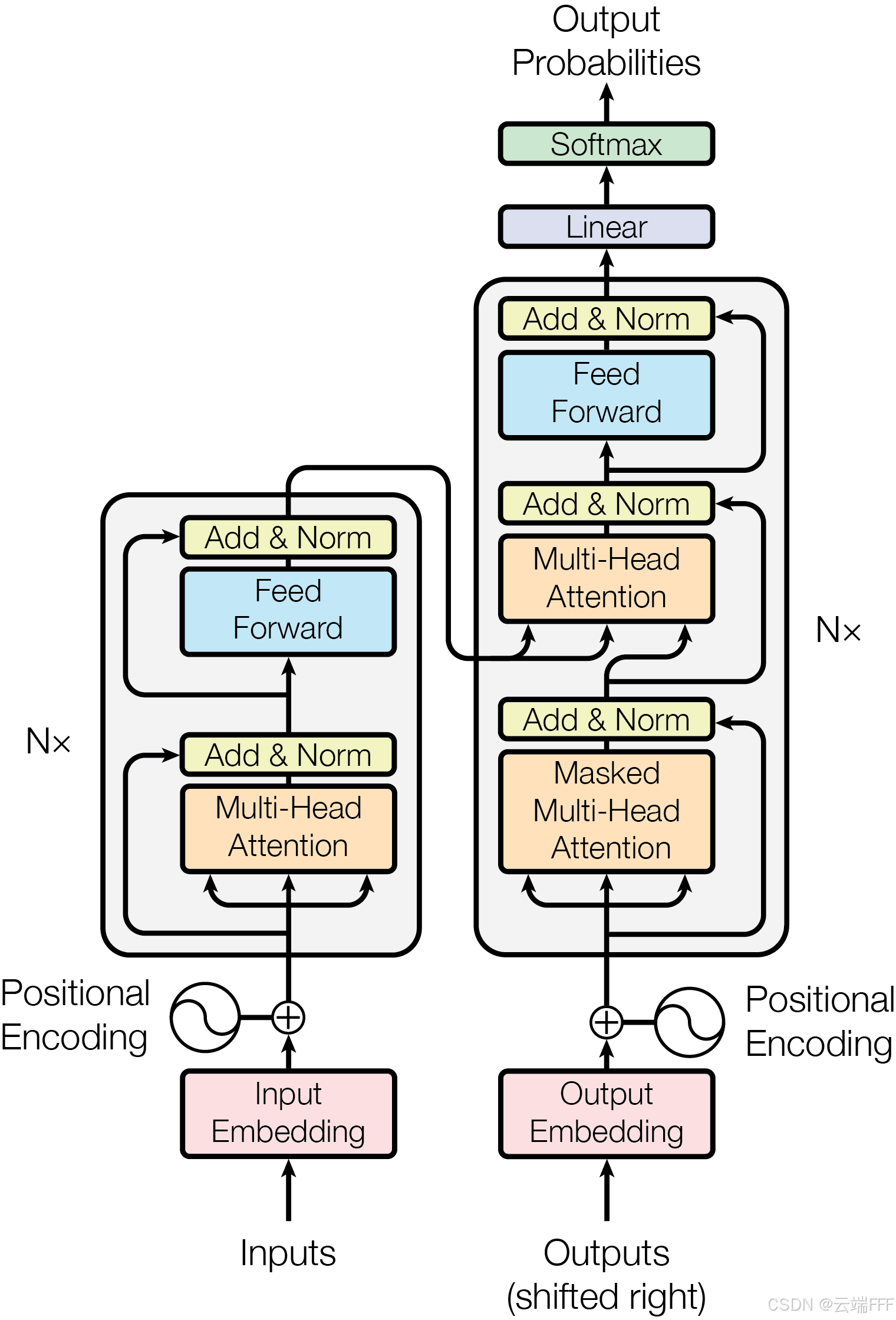
原始的 Transformer 是 Encoder-Decoder 模型,用于自然语言翻译任务。其 Encoder 部分接受原始序列输入并构建其完整的特征表示,Decoder 部分基于 Encoder 提供的特征和当前已经翻译的部分结果,自回归地生成目标序列(翻译结果)。 无论 Encoder 还是 Decoder,均由多个 Transformer Block 堆叠而成,每个 Transformer Block 由 Attention Layer 和 FFD Layer 组成
-
由于 Transformer Encoder 具有序列特征提取能力,Transformer Decoder 具有自回归序列生成能力,两者之后都被独立使用,Encoder-Only 衍生出属于自编码器的 BERT 类模型,Decoder-Only 衍生出属于自回归生成模型的 GPT 类模型
-
- Attention 机制
- Attention 机制是 Transformer 类模型的一个核心特征,在计算当前 token 的特征表示时,可以通过注意力机制有选择性地告诉模型应该使用哪部分上下文
- Encoder-Decoder / Encoder-Only / Decoder-Only 三类模型,可以归结为 attention mask 设置的不同,详见 1.2 节
1.2 模型类型
-
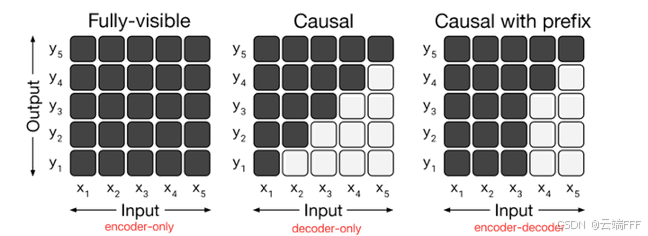
目前主流的 Transformer 类模型可分为以下四类
- 自编码模型:
Encoder-Only结构,拥有双向的注意力机制,即计算每一个词的特征时都看到完整上下文 - 自回归模型:
Decoder-Only / Causal Decoder结构,拥有单向的注意力机制,即计算每一个词的特征时都只能看到上文,无法看到下文: - 序列到序列模型:
Encoder-Decoder结构,Encoder部分使用双向的注意力,Decoder部分使用单向注意力 - 前缀模型:
Prefix-Decoder结构,它对输入序列的前缀部分使用双向注意力机制,后半部分使用单向注意力机制,前缀片段内部的所有 token 都能看到完整上下文,其他部分只能看到前文。这可以看作是 Encoder-Decoder 的一个变体
- 自编码模型:
-
以上 3 的结构示意图已经在 1.1 节给出,它的 Encoder-Decoder 使用两个独立的 Transformer 结构,其中通过 cross attention 机制连接,1/2/4 都只使用一个 Transformer 结构,区别仅在于 attention mask 施加不同,使得序列中各个 token 能观测到的上下文区域有所区别,如下所示
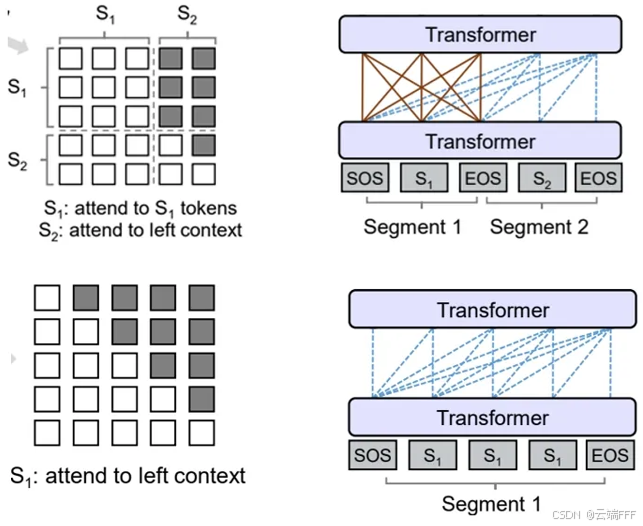
- Prefix Decoder 和 Encoder-Decoder 的主要区别在于:前者对编码部分的 attention 是在每一层 Transformer Block 内部施加的,即第任意一层 Block 中的解码部分片段可以关注到该层的前缀片段;后者则是 Decoder 中每层 Block 都能只能关注到 Encoder 最后一层的编码片段结果
- Prefix Decoder 和 Decoder-Only 非常类似,它们能执行的任务类型也差不多,下图更清晰地指示了二者的不同
-
不同的模型结构适用不同的预训练方法,主要有以下几种

FLM (full language modeling):就是训练标准的语言模型,完整一段话从头到尾基于上文预测下一个token。适用于 Decoder-Only 模型PLM (prefix language modeling):一段话分成两截,前一截作为输入,预测后一截。适用于 Encoder-Decoder 模型和 Prefix Decoder 模型MLM (masked language modeling):遮盖住文本中的一部分token,让模型通过上下文猜测遮盖部分的token。适用于 Encoder-Only 模型- 将任务改造成 text-to-text 形式(即 input 和 target 都是一段文本),可以适配 Encoder-Decoder 和 Prefix Decoder
- 将 input 和 target 拼接起来,可以适配 Decoder-Only
-
总结一下各类结构的经典模型和主要适用任务
模型类型 预训练目标 常用预训练模型 主要适用任务 Encoder-only MLM ALBERT,BERT,DistilBERT,RoBERTa 文本分类、命名实体识别、阅读理解 Decoder-only FLM GPT,GPT-2,Bloom,LLaMA 文本生成 Encoder-Decoder PLM BART,T5,Marian,mBART 文本摘要、机器翻译 Prefix-Decoder PLM ChatGLM、ChatGLM2、U-PaLM 文本摘要、机器翻译、文本生成 注意这里的适用任务并不绝对,比如 Decoder-only 配合指令微调,在参数规模大了之后其实什么都能做;用 MLM 目标预训练的模型,经过 PLM 或 FLM 继续训练后,也能做翻译和生成等任务,反之亦然。可以参考论文 What Language Model Architecture and Pretraining Objective Works Best for Zero-Shot Generalization?
-
额外提一句,当前最流行的模型结构是 Decoder-only,其中可能包含多方面原因,可以参考 【大模型慢学】GPT起源以及GPT系列采用Decoder-only架构的原因探讨
1.3 Model Head
- 和 CV 任务很多都使用 ResNet Backbone 一样,同一个 Transformer backbone 可以通过连接不同的 head 完成很多 NLP 任务。在 Transformers 库的设计上,一个相同的模型骨干可以对应多个不同的任务,它们的区别仅在于最后的 model head 有所不同
-
Model Head 是连接在模型后的层,通常为1个或多个全连接层
-
Model Head 将模型的编码的表示结果进行映射,以解决不同类型的任务
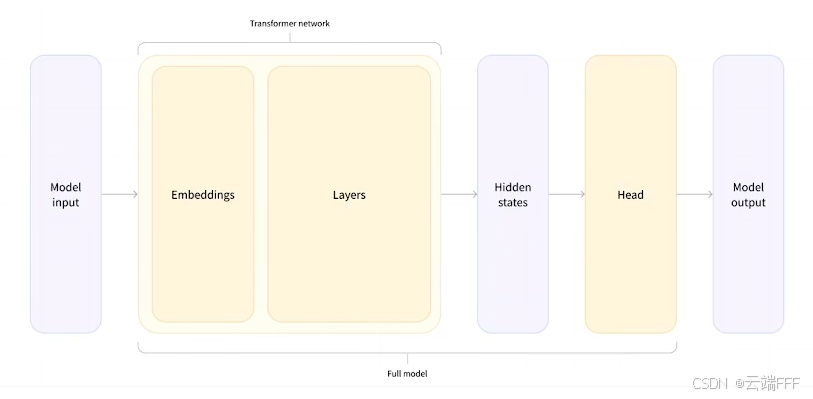
以 BERT 模型情感二分类任务为例,设模型输入长度 128,嵌入维度 768,则 Hidden states 尺寸 1x128x768。这时 Head 可能是一个输入尺寸为 768,输出尺寸为 2 的 MLP,最后一层 Hidden states 中 [CLS] 特殊 token 位置的 768 维向量将会输入 Head,对 Head 输出计算交叉熵损失来训练模型
-
- Transformer 库中,模型类对象使用的 Model Head 可以从其类名后缀中观察出来
- *Model(模型本身,只返回编码结果)
- *ForCausalLM
- *ForMaskedLM
- *ForSeq2SeqLM
- *ForMultipleChoice
- *ForQuestionAnswering
- *ForSequenceClassification
- *ForTokenClassification
- ...
2. Transformer 库 Model 组件的基本使用
2.1 创建模型
2.1.1 显式设置模型
- 如果知道要使用模型的类型,可以直接使用其架构相对应的模型类,以加载 Bert 模型为例,首先创建其 config 对象
1
2
3
4
5from transformers import BertConfig, BertModel
# 初始化 Config 类
config = BertConfig(hidden_size=768) # 以下 config 参数可传参设置
config1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20BertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.40.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
} - 然后就可以基于 config 对象构造模型,模型对象也支持从 checkpoint 构造
1
2
3
4
5# 从 Config 类初始化随机模型
model = BertModel(config)
# 也可从预训练 checkpoint 构造模型
model = BertModel.from_pretrained("google-bert/bert-base-cased")
2.1.2 使用 AutoModel
-
AutoModel类及其所有的相关类是对 Transformers 库中可用的各种模型的智能包装,它们可以自动猜测加载 checkpoint 适合的模型架构,然后实例化一个具有相同架构的模型。基于AutoModel类,可以用from_pretrained方法直接从模型地址下载模型和权重检查点,并返回 model 对象。这类似前文介绍过的AutoTokenizer类似。 -
通常我们会将上一节的
BertModel替换为等效的AutoModel类,这样可以摆脱对 checkpoint 的依赖如果你的代码适用于一个 checkpoint,那么它就可以无缝适用于另一个 checkpoint,即使体系结构不同这是如此,只要 checkpoint 是针对同类的任务(例如,情绪分析任务)训练的即可
-
这里我们加载一个小规模的中文情感分类模型作为示例
1
2
3
4
5from transformers import AutoConfig, AutoModel, AutoTokenizer
# 在线加载
# 若下载失败,也可以在仓库 https://huggingface.co/hfl/rbt3/tree/main 手动下载,然后在from_pretrained方法中传入本地文件夹加载
model = AutoModel.from_pretrained("hfl/rbt3")
model1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
...
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)可以看到这是一个
BertModel -
可以通过
model.config访问该模型的参数1
2# 查看模型配置参数
model.config1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31BertConfig {
"_name_or_path": "hfl/rbt3",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 3,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
...
"transformers_version": "4.41.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}可见,Bert 类模型的参数使用一个
BertConfig类对象管理,查看其源码定义,可以看到参数的解释1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72class BertConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`BertModel`] or a [`TFBertModel`]. It is used to
instantiate a BERT model according to the specified arguments, defining the model architecture. Instantiating a
configuration with the defaults will yield a similar configuration to that of the BERT
[google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 30522):
Vocabulary size of the BERT model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`BertModel`] or [`TFBertModel`].
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"silu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 2):
The vocabulary size of the `token_type_ids` passed when calling [`BertModel`] or [`TFBertModel`].
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
[Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
classifier_dropout (`float`, *optional*):
The dropout ratio for the classification head.
Examples:
```python
> >> from transformers import BertConfig, BertModel
> >> # Initializing a BERT google-bert/bert-base-uncased style configuration
> >> configuration = BertConfig()
> >> # Initializing a model (with random weights) from the google-bert/bert-base-uncased style configuration
> >> model = BertModel(configuration)
> >> # Accessing the model configuration
> >> configuration = model.config
```"""
model_type = "bert"
def __init__()
... -
注意到 BertConfig 类继承自
PretrainedConfig,这意味着之前从model.config打印的参数并不完整,进一步查看 PretrainedConfig 类的源码,可以看到模型使用的所有参数。了解模型使用的全部参数是重要的,因为我们修改模型时主要就是从修改参数入手
2.2 模型保存
- 使用
save_pretrained()方法将模型保存到指定位置1
2
3
4
5
6
7
8
9# 保存模型到指定路径
save_path = "C:\\Users\\xxxxx"
model = BertModel.from_pretrained("google-bert/bert-base-cased")
model.save_pretrained(save_path)
# 推荐同时保存对应的tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
tokenizer.save_pretrained(save_path) - 模型保存后会得到
config.json和model.safetensors两个文件,其中config.json存储了模型架构参数,以及 checkpoint 来源、Transformers 版本等元数据model.safetensors被称为 state dictionary(状态字典) ,它包含了模型的所有权重
2.3 模型调用
2.3.1 不带 Model Head 的模型调用
-
像 2.1.2 节那样加载,得到的 model 是不带 model head 的,这一点可以从打印从模型结构中看出,它以一个
BertPooler块结尾1
2
3
4
5
6...
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
...可见输出特征还是 768 维,这意味着没有接调整到目标维度的 model head。当我们想把预训练的模型作为序列特征提取器时,这种裸模型是有用的,可以通过加载模型时传入参数
output_attentions=True来获得模型所有层的 attention 张量1
2
3
4
5
6
7
8
9
10
11# 构造测试输入
sen = "弱小的我也有大梦想!"
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3") # 加载 tokenizer
inputs = tokenizer(sen, return_tensors="pt") # return_tensors="pt" 要求返回 tensor 张量
# 不带 model head 的模型调用
model = AutoModel.from_pretrained("hfl/rbt3", output_attentions=True) # 要求输出 attention 张量
output = model(**inputs)
print(output.keys()) # odict_keys(['last_hidden_state', 'pooler_output', 'attentions'])
assert output.last_hidden_state.shape[1] == len(inputs['input_ids'][0]) # 输出尺寸和输入尺寸相同查看最后一层 hidden state
1
2# 不带 model head 做下游任务时,通常我们是需要 model 提取的特征,即最后一层的 last_hidden_state
output.last_hidden_state # torch.Size([1, 12, 768])1
2
3
4
5
6
7
8tensor([[[ 0.6804, 0.6664, 0.7170, ..., -0.4102, 0.7839, -0.0262],
[-0.7378, -0.2748, 0.5034, ..., -0.1359, -0.4331, -0.5874],
[-0.0212, 0.5642, 0.1032, ..., -0.3617, 0.4646, -0.4747],
...,
[ 0.0853, 0.6679, -0.1757, ..., -0.0942, 0.4664, 0.2925],
[ 0.3336, 0.3224, -0.3355, ..., -0.3262, 0.2532, -0.2507],
[ 0.6761, 0.6688, 0.7154, ..., -0.4083, 0.7824, -0.0224]]],
grad_fn=<NativeLayerNormBackward0>)
2.3.2 带 Model Head 的模型调用
-
使用带有 1.3 节所述 model head 类名后缀的模型类加载模型,即可得到带 head 的模型
1
2
3
4from transformers import AutoModelForSequenceClassification
clz_model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3") # 加载带多分类头的模型
clz_model # 注意模型结构最后多了 (classifier): Linear(in_features=768, out_features=2, bias=True)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33Some weights of BertForSequenceClassification were not initialized from the model checkpoint at hfl/rbt3 and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
...
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)注意模型现在变成了一个
BertForSequenceClassification对象,其结构最后多了一个由dropout和classifier线性层组成的 head,而且这里提示我们Some weights of BertForSequenceClassification were not initialized...,说明这个线性层的参数 ckpt 中没有提供,需要我们针对下游任务特别训练 -
注意到分类头默认输出维度(类别数为2),这个可以通过参数
num_labels控制,从模型类BertForSequenceClassification定义进去检查。下面修改 model head 的输出维度看看1
2
3
4
5# 分类头默认输出维度(类别数为2),可以通过参数 num_labels 控制
from transformers import AutoModelForSequenceClassification, BertForSequenceClassification
clz_model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3", num_labels=10) # 指定10个类
clz_model # 注意模型结构最后多了 (classifier): Linear(in_features=768, out_features=10, bias=True)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33Some weights of BertForSequenceClassification were not initialized from the model checkpoint at hfl/rbt3 and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
...
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=10, bias=True)
) -
使用以上模型做前向传播试试
1
clz_model(**inputs)1
2SequenceClassifierOutput(loss=None, logits=tensor([[ 0.1448, 0.1539, -0.1112, 0.1182, 0.2485, 0.4370, 0.3614, 0.5981,
0.5442, -0.2900]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)可见输出结构中存在一个
loss成员,说明前向过程中就有计算 loss 的结构了,不妨看一下BertForSequenceClassification类的定义1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_SEQUENCE_CLASSIFICATION,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
expected_output=_SEQ_CLASS_EXPECTED_OUTPUT,
expected_loss=_SEQ_CLASS_EXPECTED_LOSS,
)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], SequenceClassifierOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)从 forward 方法中可见,如果传入了 labels 参数,则会进一步根据输出尺寸
num_labels自动识别任务类型,并使用相应的损失函数计算 loss 作为返回的一部分
3. 下游任务训练
- 在 2.2.2 节,我们构造了一个
BertForSequenceClassification模型,它的 Bert 骨干加载了预训练的 ckpt 权重,而分类头权重是随机初始化的。本节我们使用 ChnSentiCorp_htl_all数据集对它做下游任务训练,该数据集由 7000 多条酒店评论数据,包括 5000 多条正向评论,2000 多条负向评论,用这些数据继续训练,可以得到一个文本情感分类模型。由于模型中绝大部分参数都有良好的初始权重,且模型规模很小,训练成本并不高 - 我们这里不使用 Transformers 库的 pipeline、evaluate、trainer 和 dataset,尽量手动实现全部代码,细节请参考注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100import os
import sys
base_path = os.path.abspath(os.path.join(os.path.dirname(__file__)))
sys.path.append(base_path)
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from torch.optim import Adam
class MyDataset(Dataset):
def __init__(self) -> None:
super().__init__()
self.data = pd.read_csv(f"{base_path}/ChnSentiCorp_htl_all.csv") # 加载原始数据
self.data = self.data.dropna() # 去掉 nan 值
def __getitem__(self, index):
text:str = self.data.iloc[index]["review"]
label:int = self.data.iloc[index]["label"]
return text, label
def __len__(self):
return len(self.data)
def collate_func(batch):
# 对 dataloader 得到的 batch data 进行后处理
# batch data 是一个 list,其中每个元素是 (sample, label) 形式的元组
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
# 对原始 texts 列表进行批量 tokenize,通过填充或截断保持 token 长度为 128,要求返回的每个字段都是 pytorch tensor
global tokenizer
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
# 增加 label 字段,这样之后模型前向传播时可以直接计算 loss
inputs["labels"] = torch.tensor(labels)
return inputs
def evaluate(model):
model.eval()
acc_num = 0
with torch.inference_mode():
for batch in validloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
acc_num += (pred.long() == batch["labels"].long()).float().sum()
return acc_num / len(validset)
def train(model, optimizer, epoch=3, log_step=100):
global_step = 0
for ep in range(epoch):
model.train()
for batch in trainloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
optimizer.zero_grad()
output = model(**batch) # batch 是一个字典,其中包含 model forward 方法所需的字段,每个字段 value 是 batch tensor
output.loss.backward() # batch 字典中包含 labels 时会计算损失,详见源码
optimizer.step()
if global_step % log_step == 0:
print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")
global_step += 1
acc = evaluate(model)
print(f"ep: {ep}, acc: {acc}")
if __name__ == "__main__":
# 构造训练集/测试集以及对应的 Dataloader
dataset = MyDataset()
train_size = int(0.9*len(dataset))
vaild_size = len(dataset) - train_size
trainset, validset = random_split(dataset, lengths=[train_size, vaild_size])
trainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
# 构造 tokenizer、model 和 optimizer
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3") # 从 AutoModelForSequenceClassification 加载标准初始化模型,从 AutoModel.from_pretrained("hfl/rbt3") 加载 ckpt 权重模型
if torch.cuda.is_available():
model = model.cuda()
optimizer = Adam(model.parameters(), lr=2e-5)
# 训练
train(model, optimizer)
# 测试
sen = "我觉得这家酒店不错,饭很好吃!"
id2_label = {0: "差评!", 1: "好评!"}
model.eval()
with torch.inference_mode():
inputs = tokenizer(sen, return_tensors="pt")
inputs = {k: v.cuda() for k, v in inputs.items()}
logits = model(**inputs).logits
pred = torch.argmax(logits, dim=-1)
print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")1
2
3
4
5
6
7
8
9
10
11
12
13Some weights of BertForSequenceClassification were not initialized from the model checkpoint at hfl/rbt3 and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
ep: 0, global_step: 0, loss: 0.6289803385734558
ep: 0, global_step: 200, loss: 0.17686372995376587
ep: 0, acc: 0.8944659233093262
ep: 1, global_step: 300, loss: 0.18355882167816162
ep: 1, global_step: 400, loss: 0.27272453904151917
ep: 1, acc: 0.8957529067993164
ep: 2, global_step: 500, loss: 0.18500971794128418
ep: 2, global_step: 600, loss: 0.08873294293880463
ep: 2, acc: 0.8918918967247009
输入:我觉得这家酒店不错,饭很好吃!
模型预测结果:好评!