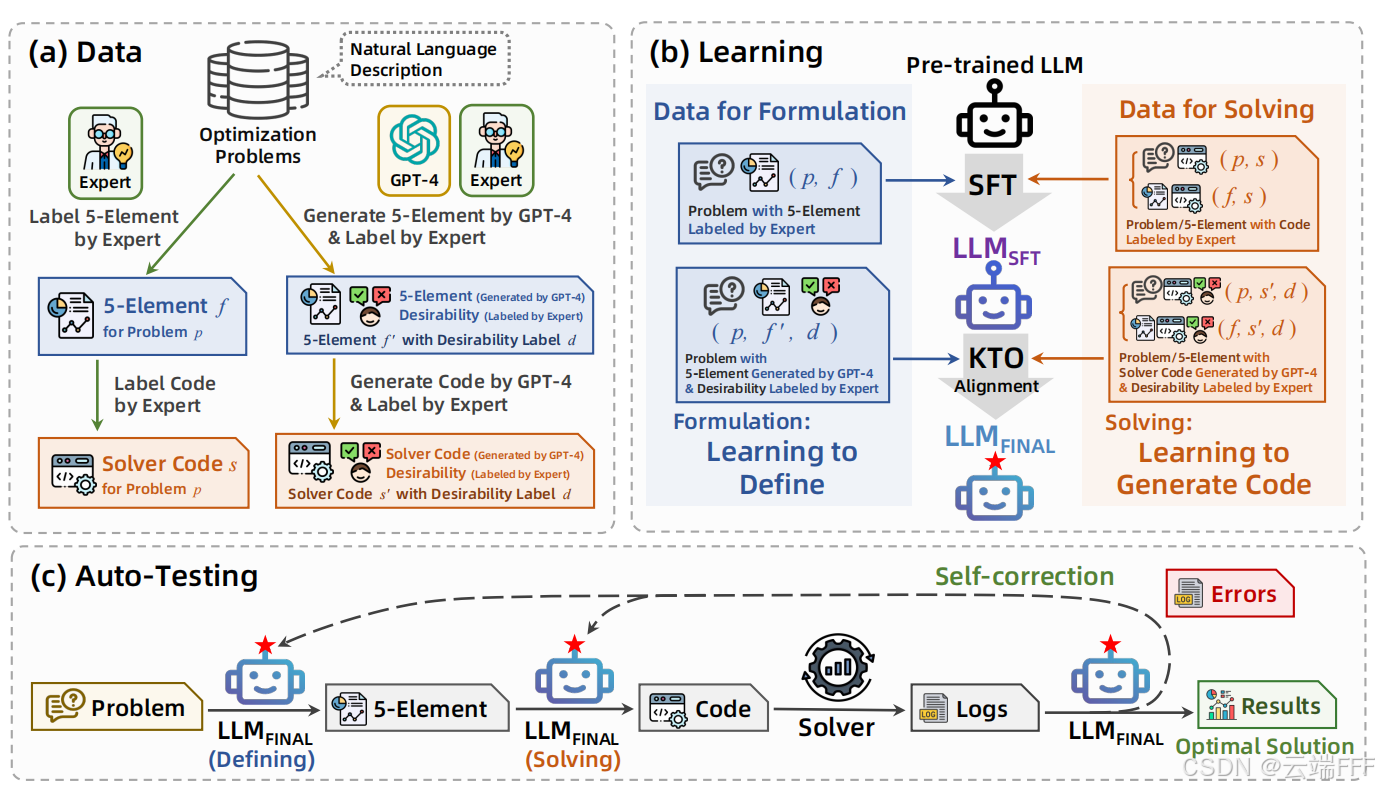
论文理解【LLM-OR】——【LLMOPT】Learning to Define and Solve General Optimization Problems from Scratch 针对 LLM-OR 任务,传统端到端直接生成方法的准确性与问题类型泛化受限;LLMOPT 引入五要素通用表述 + 多指令微调 + KTO 对齐 + 自动测试自纠错的学习式流程,从自然语言描述出发更稳健地定义并求解多类优化问题,在六个真实数据集上取得平均 11.08% 的准确率提升 2026-05-14 机器学习 > 论文理解 #LLM #LLM-OR
论文理解【LLM-OR】——【OptiMUS】Scalable Optimization Modeling with (MI)LP Solvers and Large Language Models OptiMUS 把 “自然语言 → 优化建模与求解” 从单次生成改造成 “结构化问题 + 多智能体协作 + 连接图检索” 的模块化流程,并在更长更难的数据集上验证了这种结构化方法相对端到端 prompting 的优势 2026-05-14 机器学习 > 论文理解 #LLM #LLM-OR
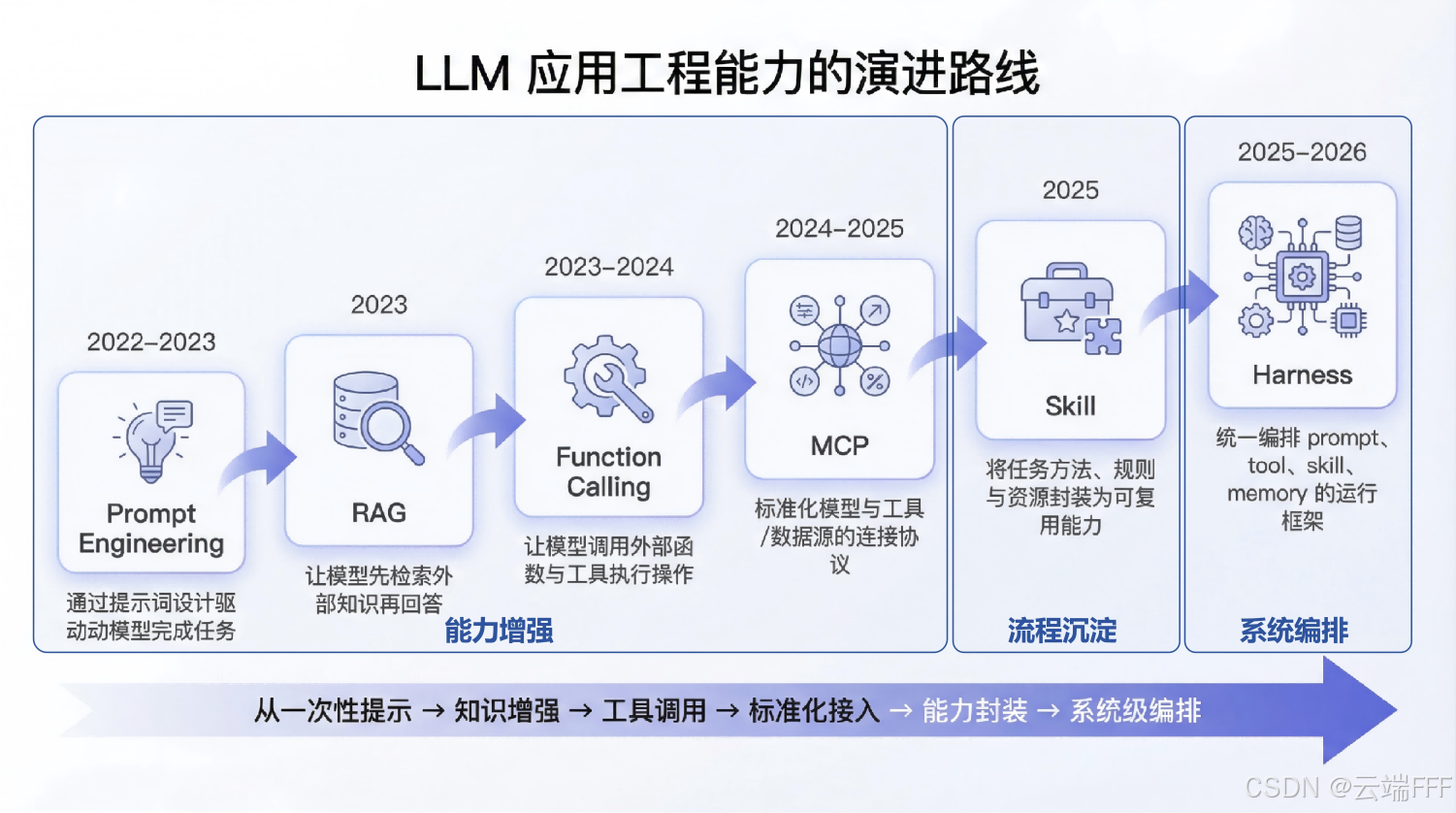
LLM-based Agent 技术演进 —— 从 Prompt Engineering 到 Harness 本文梳理了LLM应用工程形态的演进路径,划分为三个阶段:能力增强(Prompt Engineering、RAG、Function Calling、MCP)、流程沉淀(Skill)和系统编排(Harness),并对 Skill 进行深入介绍 2026-04-08 LLM专题 #LLM #Agent #Skill #AI Engineering
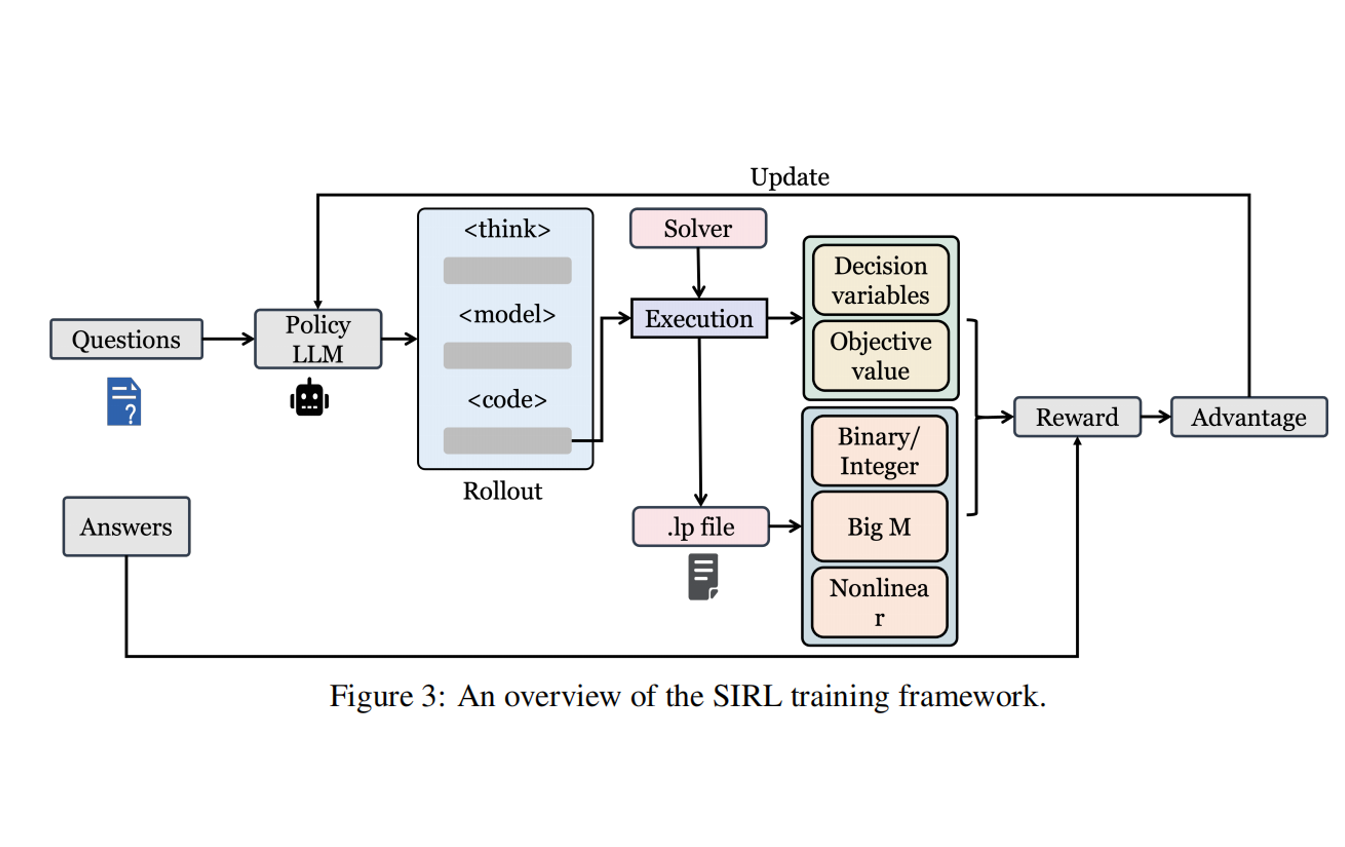
论文理解【LLM-OR】——【SIRL】Solver-Informed RL-Grounding Large Language Models for Authentic Optimization M 本文提出第一种针对基于 LLM 的 OR 问题建模和求解任务的 RLVR 方法,其基于求解器得到可验证奖励,设计了 Partial KL 强化目标函数和两阶段奖励课程训练方法,达成了 SOTA 性能 2026-02-10 机器学习 > 论文理解 #LLM-RL #LLM #RL #LLM-OR
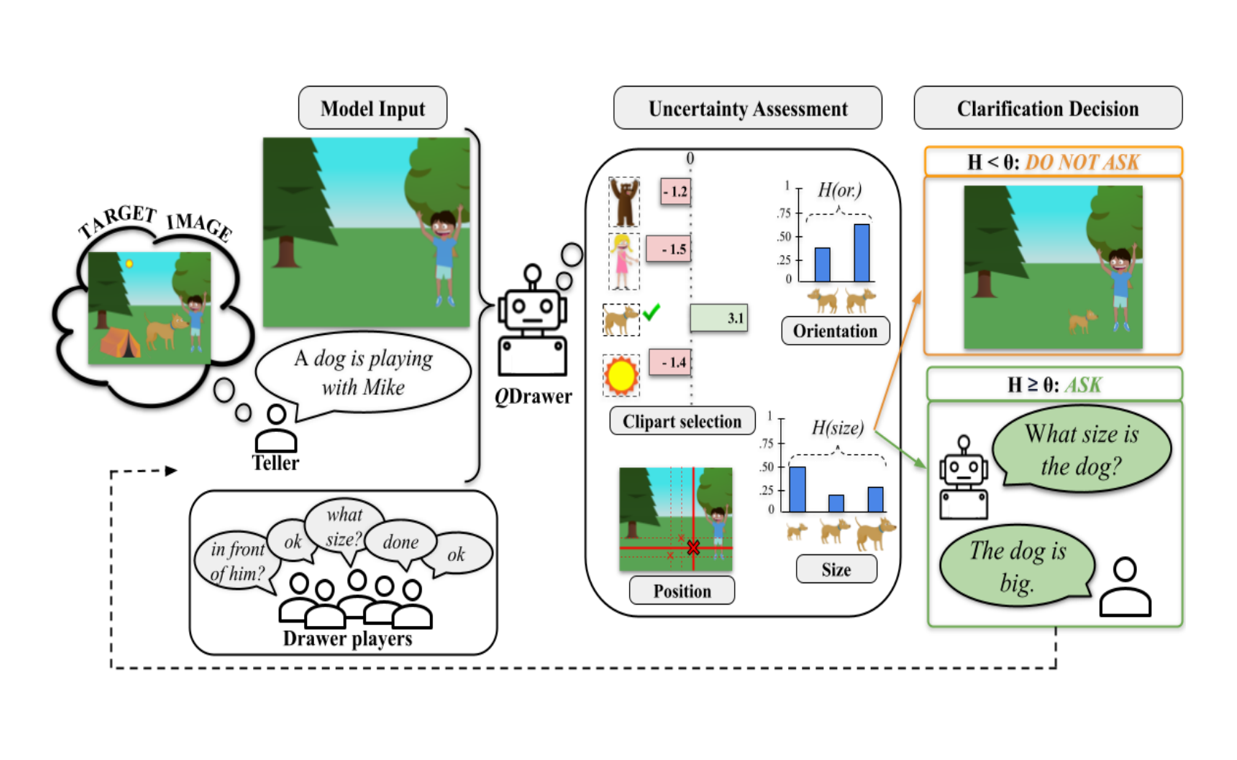
论文理解【LLM-Clarification】——【QDrawer】Asking the Right Question at the Right Time 本文基于 CoDraw 任务对 LLM 澄清提问的触发方式进行探索,发现模型内部不确定性与人类澄清决策相关性弱,使用不确定性阈值触发澄清提问相比模仿人类提问时机,性能和计算效率都更好 2026-02-05 机器学习 > 论文理解 #LLM #LLM-Clarification
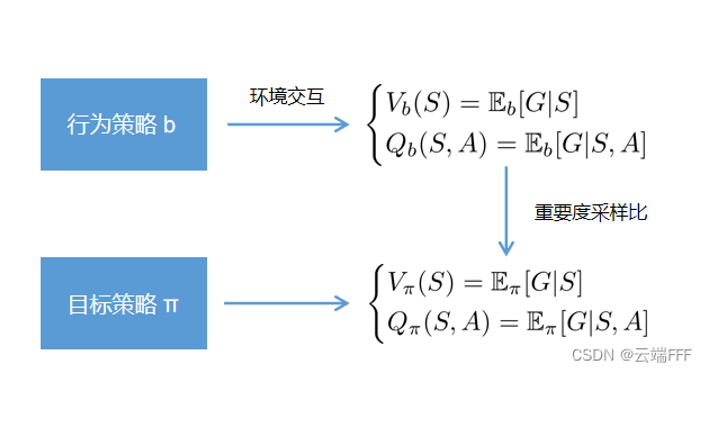
强化学习拾遗 —— Off-policy 方法中的重要性采样比 考虑一个问题:为何基于 DQN 的 PER 需要重要度采样比,而基于 Q-learning 的优先级 Dyna-Q 则不用 2026-02-02 机器学习 > 强化学习 #强化学习
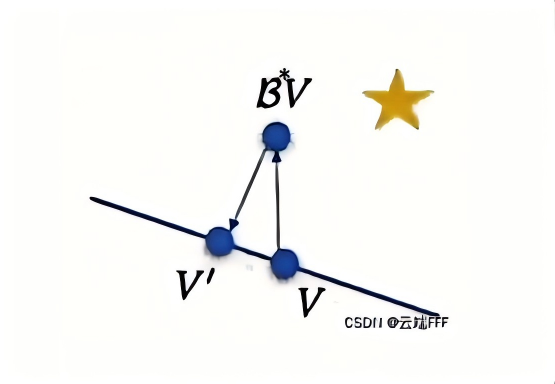
强化学习拾遗 —— 表格型方法和函数近似方法中 Bellman 迭代的收敛性分析 本文考察表格型 model-based evaluation 方法中,使用 Bellman 算子进行迭代的收敛性:首先补充一些测度论中的定义,然后介绍压缩映射原理和不动点,最后证明收敛性 2026-02-02 机器学习 > 强化学习 #强化学习
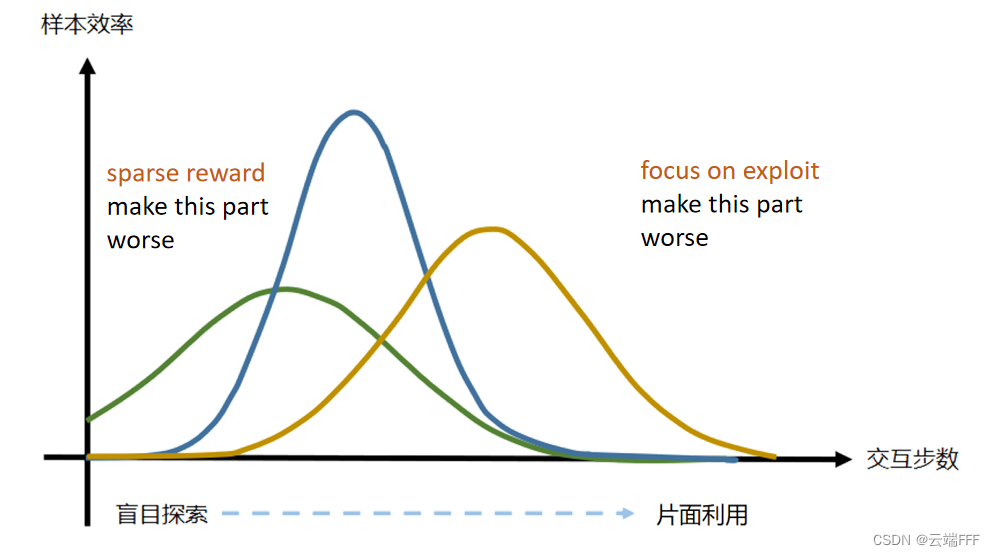
强化学习拾遗 —— 强化学习的样本效率 总所周知,样本效率低下是强化学习的一个重要问题,本文试图从本质上分析造成这一问题的原因,并简单介绍一些改进措施 2026-02-02 机器学习 > 强化学习 #强化学习 #样本效率
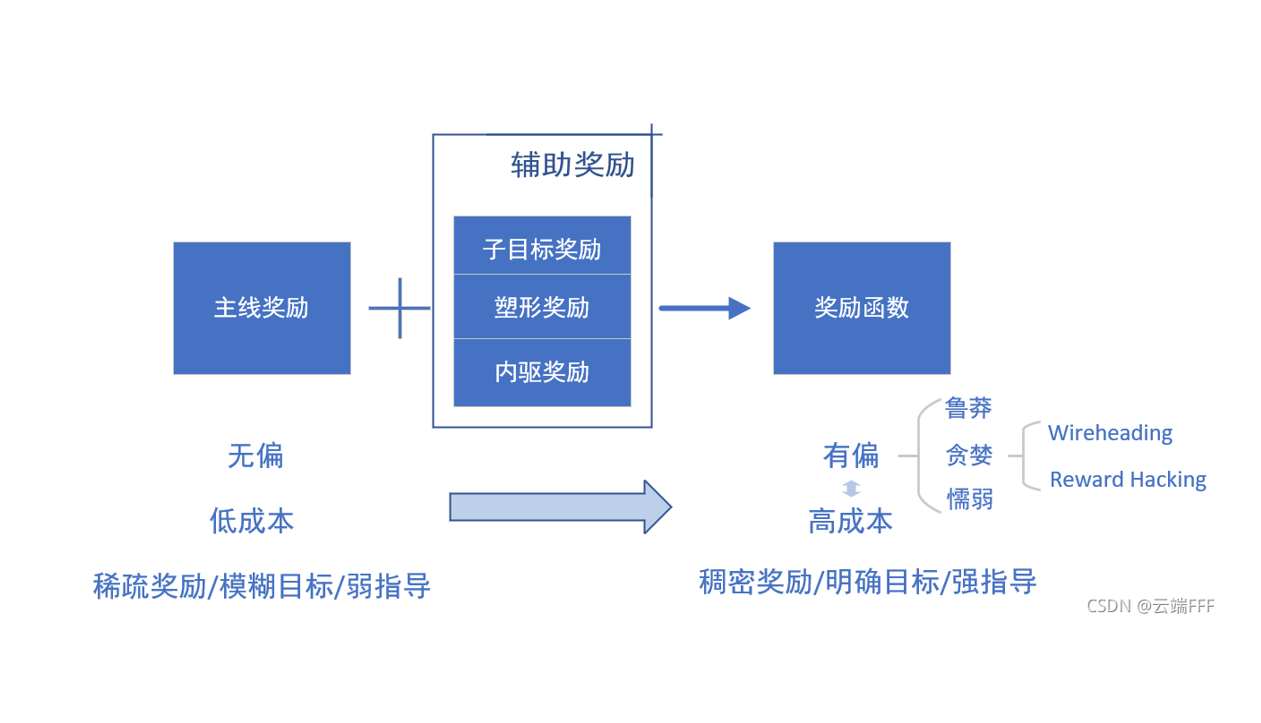
强化学习拾遗 —— 再看奖励函数 本文介绍设计奖励函数的一般思路及面临的困境,对奖励函数的本质进行分析,从更高的角度建立对奖励函数的深刻认识 2026-02-02 机器学习 > 强化学习 #强化学习 #奖励函数
LPSolversandLargeLanguageModels/index.png)