强化学习拾遗 —— Off-policy 方法中的重要性采样比
- 首发链接:强化学习拾遗 —— Off-policy 方法中的重要性采样比
- 重要度采样比的概念在 RL 中似乎很简单,我以前也没太关注过,最近看 PER 论文突然想到一个问题,为何基于 DQN 的 PER 需要重要度采样比,而基于 Q-learning 的优先级 Dyna-Q 则不用,由此引发的一些思考整理成此文
- 开篇先说一下我的看法,针对 off-policy 的 value based control 方法
- MC Control 类方法使用行为策略 收集的数据估计目标策略 对应的价值 ,必须用重要性采样比调整期望
- TD Control 方法基于 Bellman Optimal Equation,使用行为策略 收集的数据直接估计最优策略 对应的价值 得到 ,进而导出行为策略 。这时只要考虑 的估计情况,由公式可知 的对应的期望和策略无关,因此我们可以使用任何行为策略收集数据,自然也不需要重要度采样比,这对于表格型 TD control 方法都成立(如 Q-learning、优先级 Dyan-Q 等)
- 对于使用的函数近似的 off-policy TD control 方法而言,由于函数近似方法本身的性质,它们得到的价值估计总会存在误差(注意并不是 “错误”),行为策略 越少访问的那些 ,价值估计误差越大。因此在实践中通常需要让行为数据对目标策略所关心的 具有足够覆盖(coverage),并尽量减少对分布外区域的 bootstrap 更新,所以 DQN 使用 -greedy 等“接近当前贪心策略”的行为策略来维持训练分布的稳定性。理论上 DQN 可以用 做 off-policy 校正,但在函数逼近 + bootstrap 场景下, 往往带来极高方差并加剧不稳定(-greedy 导致);因此经典 DQN 更依赖 target network、replay 等稳定化手段
- DQN + PER 情况下,PER 的 “按优先级采样” 导致了采样分布偏差,这里重要度采样比是针对 replay 的采样分布偏置进行校正
-
重要度采样比主要用于 off-policy 的 value based control 方法,这类方法特点为
- value based 意味着 agent 首先估计价值函数,再从中导出策略
- off-policy 意味着 agent 学习的 target policy 和与环境交互使用的 behavior policy 不同
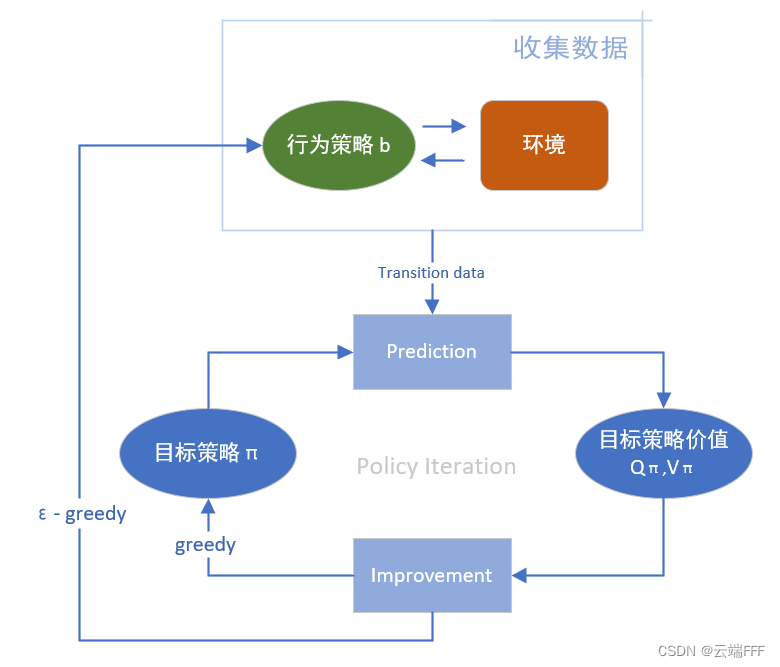
解 control 问题时,此类方法通常基于 policy iteration 思想,不停循环 “估计目标策略价值” 和 “优化目标策略” 两步直到收敛,示意图如下
1. 什么是重要度采样比
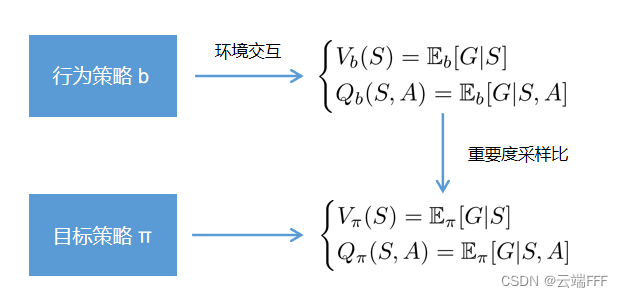
- 有时我们想估计目标分布下某一统计量的期望值,但是只有另一个分布的样本,这种利用来自其他分布的样本估计目标分布期望值的通用方法称为
重要度采样 - 观察前面的算法交互图,我们的目标是估计出目标策略对应的价值 ,但是估计时利用的样本全部来自行为策略 ,所以需要做重要度采样,我们可以根据每个 episode 或 transition 在目标策略和行动策略中出现的概率比例(相对概率)对其 return进行加权调整,从而获得目标策略 的 return 期望。这个用于调整的相对概率就是
重要度采样比 ρ - 简而言之,当价值估计方法对行为策略敏感,价值估计 和目标价值 不相等时,可以使用重要度采样比调整期望,使 ,目标价值估计更准确
2. 使用重要度采样比的场景
2.1 MC Control 方法(使用)
-
MC Control 使用蒙特卡洛方法做 prediction,其思想是直接使用经验期望估计真实期望,公式为( 表示估计)
显然经验期望是受到行为策略 影响的,因此需要做重要度采样
-
对于这种 MC prediction,有两种估计 的重要度采样方法,定义 为所有访问过状态的时刻的集合
- 使用
普通重要度采样比:,得到无偏估计,但方差无界 - 使用
加权重要度采样比:,得到有偏估计,但方差较小
- 使用
-
估计 的情况完全类似,这里不再展开,示意图如下
2.2 TD Control 方法(必要时使用)
- 所有 TD 方法的核心都是 Bellman equation 或 Bellman optimal equation,分别对应 on-policy 方法和 off-policy 方法
- 这两个等式有很好的性质,比如他们对应的算子都是压缩映射(可以依此证明价值估计一定收敛),又比如 Off-policy 情况下 TD target 是和行为策略无关的,请看下文分析
2.2.1 Q-learning(不使用)
-
Q-learning 算法直接对 Bellman optimal equation 不停迭代来估计价值,得到的估计期望如下
注意到等式右侧的期望只与状态转移分布 有关而与策略无关,不论训练 transition 来自于哪个策略,按照 Q-Learning 的更新式更新都能使 接近,又因为 Q-learning 是一个表格型方法没有泛化性,对一个 的价值更新完全不会影响到其他 的价值估计,因而无论使用什么行为策略去收集 transition,都不会引入偏差,也就不需要重要性采样
-
再仔细分析一下,得益于使用 Bellman optimal equation,这里有了一些 value iteration 的意味,我们估计的对象从目标策略的价值 变成了最优策略价值,这样我们就不用再考虑对 的估计有没有偏差了,具体地讲
- 原来我们利用 交互的样本估计 ,再根据结果提升 和 ,直到 ,引入重要度采样是为了更好地估计
- 现在我们利用 交互的样本直接估计 对应的 ,再从中直接导出更好的 和 。注意到这里估计没有偏差,因此不需要引入重要度采样比
-
需要注意的是,不同行为策略导致的价值收敛过程还是不一样的,行为策略更频繁访问 transition 的价值会更快收敛,当计算 transition 数量趋向无穷时,所有能无限采所有 的行为策略 最终会学到一样的价值函数
这就好像是用茶壶往一堆杯子里倒水,向一个杯子倒水不会干扰其他杯子。行为策略指导你向哪些杯子倒,其频繁访问的杯子更快装满水(价值收敛),如果所有杯子被访问的概率都大于 0,则时间趋于无穷时总能使所有杯子装满水(价值全部收敛到相同位置)
2.2.2 Dyna-Q(不使用)
- Dyna-Q 是 Sutton 在 RL 圣经中第八章介绍的方法,其实就是 Q-learning 加上了经验重放机制,同一章中还介绍了一种 “优先级遍历算法”,其实就是 Dyna-Q 加上了简化版本的经验优先重放(PER)机制
- 无论是均匀的经验重放,还是不均匀的经验重放,都可以把他们看做行为策略 的一部分,根据 2.2.1 节中的分析,这些不会改变价值估计结果,只是在经验重放中被强调过的那些的价值估计会较快收敛而已
2.2.3 DQN(不使用)
-
DQN 可以看作 “Q-learning + 函数近似 + 经验回放 + target network”。它仍然基于 Bellman optimal equation 做 bootstrap 更新:我们用行为数据(replay buffer 里的 transition)去逼近 ,再从中导出更好的策略。
-
更具体地讲,第 (i) 次迭代最常见的写法是最小化 TD error 的平方损失(省略常数):
其中 是 replay buffer 诱导的采样分布(可以理解为行为策略 + PER 回放机制共同诱导的数据分布), 是 target network 参数
-
现在回答核心问题:为什么 DQN 通常不显式使用 这类“策略重要性采样比”?
-
因为 DQN 的目标函数本来就定义在 “ 分布下的 TD error” 上:DQN 做的是:在 replay 的采样分布 上,让 的 Bellman 残差尽可能小。此时再乘一个 的权重,本质上是在修改优化目标(从 “在 上拟合” 变成 “在另一种加权分布上拟合”),并不会天然带来“更正确”的 。
-
在 DQN 里往往“方差大、收益小”:DQN 的目标策略通常接近 greedy,而行为策略常用 -greedy。若硬做 :
- 贪心动作上的权重可能很大(尤其动作空间大、 小时)
- 非贪心动作权重可能接近 0(样本被大量“抹掉”)
结果往往是:梯度噪声更大、训练更抖,稳定性变差
-
DQN 已经包含 “函数近似 + bootstrap + off-policy” 的死亡三要素,稳定性主要靠工程 tricks,而不是靠 去 “变无偏”,所以 DQN 经典稳定化手段是 replay、target network、Double Q 等,用来控制 bootstrap 目标漂移与分布外外推误差,而不是用重要性采样比强行校正
-
-
当然,这并不意味着“行为策略随便选都行”。函数近似下,覆盖(coverage) 才是关键:行为数据很少覆盖的 区域, 往往更不稳定,bootstrap 还可能把这种误差 “传染” 到更多状态上。所以 DQN 实践中通常让行为策略不过度偏离当前贪心策略(例如 -greedy),以维持训练分布的可控性
-
DQN 论文讲解请参考:论文理解【RL经典】 —— 【DQN】Human-level control through deep reinforcement learning
2.2.4 PER(使用)
- PER 是适用于 DQN 系列方法的一个 trick,它在经验回放的过程中以更高的概率重放那些 TD error 更大的 transition,这相当于给原始 DQN 中的行为策略 加入了一个无法预测的偏移,这时 就可能和 相差很多了,根据 2.2.3 节的分析,这时需要使用重要度采样比,把 对应的价值期望拉回到 的水平。更准确地说,PER 引入的重要性采样(IS)权重,核心目的不是校正 的策略 mismatch,而是校正 replay 的抽样分布偏差
- PER 论文讲解请参考:论文理解【RL - Exp Replay】 —— 【PER】Prioritized Experience Replay
2.3 其他
- RL 中还有一些重要性采样比的高级用法,比如 “折扣敏感的重要度采样比”(见 Sutton 圣经书 5.8 节),但和本文主要讨论的问题无关,不再展开