论文理解【LLM-OR】——【SIRL】Solver-Informed RL-Grounding Large Language Models for Authentic Optimization M
- 首发链接:论文理解【LLM-OR】——【SIRL】Solver-Informed RL-Grounding Large Language Models for Authentic Optimization M
- 文章链接:Solver-Informed RL: Grounding Large Language Models for Authentic Optimization Modeling
- 发表:NIPS 2025
- 代码:Cardinal-Operations/SIRL
- 领域:LLM OR
- 一句话总结:使用 LLM 对运筹优化问题(OR Problem)进行建模和求解代码生成时,常因幻觉与格式/建模错误导致不可执行或不可行,本文提出 SIRL 方法,将优化求解器作为可验证奖励来源,同时利用生成代码执行后得到的 .lp 实例级模型表示抽取结构统计量,联合语法有效性、可行性、目标值质量等信号构造奖励,并通过Partial KL 代理目标与两阶段奖励课程稳定训练,从而显著提升生成模型的可执行性与准确性,并在多项公开基准上取得领先结果
- 摘要:优化建模是供应链管理、物流与金融工程等领域决策的基础,但其复杂性成为应用落地的主要障碍。将自然语言描述自动转化为优化模型是提升效率与可获得性的关键。然而,尽管大语言模型(LLM)是很有前景的工具,它们常因错误与幻觉而产生有缺陷或不可行的结果。为解决这一问题,我们提出求解器知情强化学习(Solver-Informed Reinforcement Learning,SIRL):一种使用可验证奖励的强化学习框架,以增强 LLM 生成准确且可执行的优化模型的能力。具体而言,SIRL 会自动评估生成的可执行代码,以及由相应 .lp 文件表示的实例级数学模型。该过程为语法有效性、可行性与解的质量提供精确反馈,并将其作为直接奖励信号来引导强化学习过程。此外,该验证机制也支持我们用于创建高质量训练数据的实例增强自一致性方法。我们在多样的公开基准上进行了大量实验,结果表明:采用 SIRL 框架训练的模型达到了当前最优性能,在生成准确且可执行的优化模型方面显著优于现有方法。特别地,我们的 SIRL-32B 模型在这些基准中的大多数上超过了 DeepSeek-V3 与 OpenAI-o3
1. 背景
- 本文研究优化问题的自动建模与编程,以减轻对人类专家的严重依赖。具体而言,这类问题要求输入一段自然语言描述的问题(如配送货、生产规划等问题),要求模型或系统完成运筹学建模,并生成问题求解代码
- 针对该任务,当前主要存在基于提示和基于微调的两类方法:
- 基于提示的建模prompt-based modeling:通过为 GPT-4o 等大规模预训练 LLM 精心设计建模 Prompt 来工作,相关方法包括 OptiTree、PaMOP 等。这类方法的重点在于通过引入树、图、多智能体等设计,将 “复杂问题描述上下文 -> 严格式要求代码” 的端到端生成过程拆分为多个子过程,从而降低各环节难度,并使各环节的 prompt 更具指向性
- 基于微调的建模fine-tuned LLM modeling agents:通过构造大规模运筹学及建模知识对 LLM 进行微调,形成专用的建模语言模型,如 ORLM、Step-Opt、OptMATH 等。这类方法的重点在于设计数据构方法和错误过滤方法,实现多样、正确、难度可控的高质量数据集
- 相比主流的 LLM-reasoning 与 LLM-RLVR 等方向,LLM-OR 作为相对小众赛道整体进展略慢。借鉴前述领域的演进路径,自然的下一步发展即是将强化学习更系统地引入 OR 建模任务:从任务属性看,OR 建模结果的正确性往往可以通过求解器执行进行客观验证(语法是否可运行、是否可行、目标值是否匹配等),因此该任务具备天然的“可验证奖励(verifiable reward)”信号来源,可被视作一种典型的 RLVR 场景,这也为进一步提升模型的可执行性与真实性提供了明确方向,本文定位即为第一篇直接把 RLVR 用于提升 LLM 优化建模能力的工作
形式化表述:令训练数据集为 ,其中 表示第 个优化问题的自然语言描述, 是对应的真实最优目标函数值。将问题求解器建模为一个由参数 参数化的 LLM 策略 。给定输入问题描述 ,策略 生成一个响应 ,其中包含一系列推理过程,并通过映射函数 得到目标函数值 。为了使用 RL 优化策略 ,引入可验证奖励函数 ,该函数以真实最优值 为参照,对问题 的派生目标值 的质量进行量化,优化目标是优化策略参数 ,以最大化期望奖励:
2. 本文方法
- 使用 LLM 求解 OR 问题具有适配良好的特性,使其特别适用于 RLVR 优化
- 往往涉及包含问题分析与推理、数学建模、以及代码实现的多步骤过程,这与 CoT 推理过程相似
- 求解模型输出的数学模型与求解器代码可以通过外部优化求解器进行验证,通过语法检查、求解测试等不同的验证准则,能够产生客观且丰富的奖励信号,使 RLVR 能够直接优化 LLM 的生成方向
- 本文方法包含三个主要部分
- 数据合成框架:在 ORLM 的 OR-Instruct 合成框架基础上,结合求解器执行结果与 .lp 实例级模型信息,提出 “实例增强自一致性” 以提升合成数据的质量与可靠性,用于构造 RL 阶段的高质量样本和可验证真值
- 强化学习方法 SIRL:将优化建模建模为 RLVR 任务,采用 REINFORCE++/PPO 风格的 clipped surrogate 目标,并提出 Partial KL:仅在数学建模段 与代码段 施加 KL 正则,而对推理段 不施加,以兼顾推理探索与输出结构/格式稳定
- 两阶段奖励课程:Stage-1 奖励由格式、执行与准确性组成,优先保证可执行性与基本正确性;Stage-2 在此基础上加入 ,用于激励 Big-M、非线性等高级建模技巧,并仅在“解正确且包含高级策略”时给予 bonus
2.1 数据合成框架
2.1.1 数据合成流程
-
传统基于微调的建模方法只需要获取 形式的数据即可,但为支撑 RLVR 训练,本文致力于构造 数据,其中答案是通过执行求解器 code 得到的优化真值。为此,作者提出了基于 ORLM 的数据合成管线,在构造 RL 数据的同时,提升训练数据的规模与质量。如下图所示
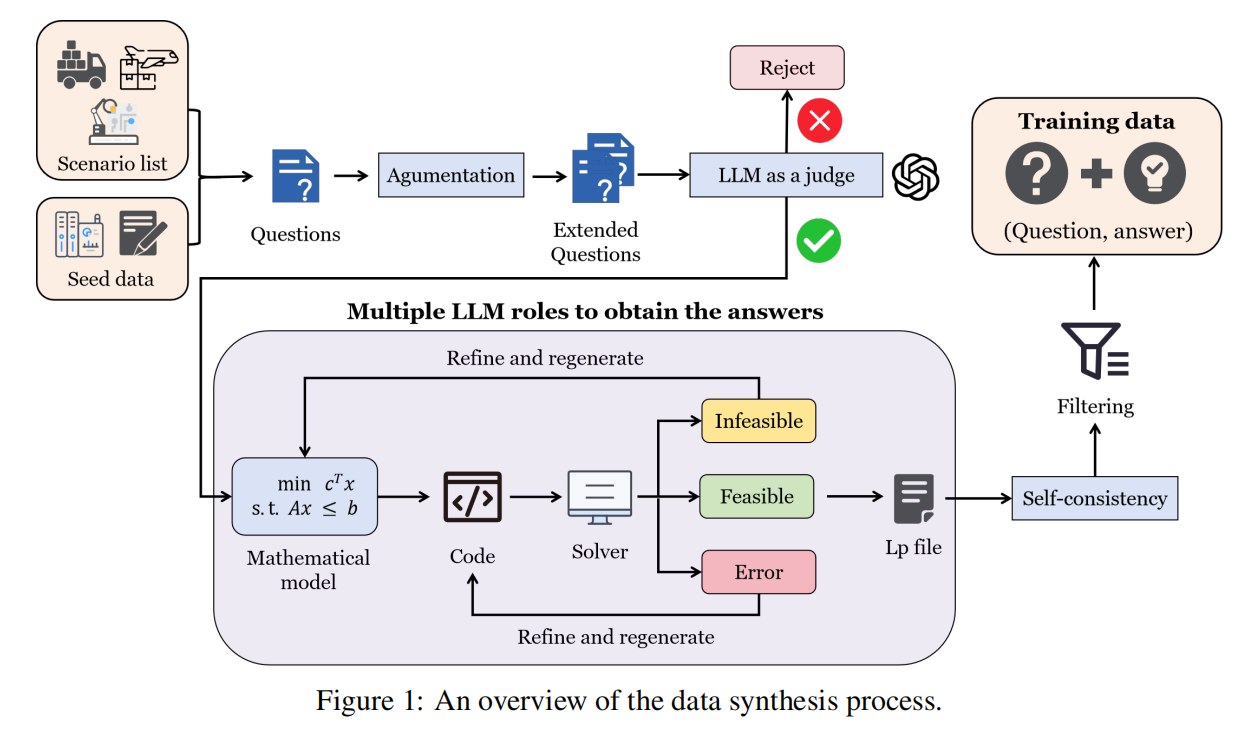
- 从种子数据开始,作为合成的基础
- ORLM数据扩展:把采样到的种子问题与预定义场景列表中的场景组合,使新问题在结构上与原问题相似但语境不同,从而扩展问题覆盖场景
- ORLM数据增强:通过修改目标和约束、重新描述问题、扩展数学建模方案等方式对生成问题进一步增强,以提升语义理解难度、数学建模复杂性和求解复杂性,从而得到更大规模、更具挑战的问题语料
- LLM-as-a-judge 过滤:用 LLM-as-a-judge 验证生成问题的实际相关性与语义一致性,不通过则丢弃
- 生成 “模型+代码” 并执行:对通过验证的问题,用 LLM 生成数学模型及代码并执行。这里有一个内部迭代反思修复过程:对于不可解问题,尝试修正数学建模;对于代码报错问题,尝试修正求解代码。最终,对能够正确求解的问题生成用 .lp 文件表示的实例级数学模型
- 多角色 + 实例增强自一致性:为每个问题分配多个 LLM 角色(10 个),并用“实例增强自一致性”选择更可靠的答案;该机制不仅看最终目标值,还会利用 .lp 中的结构信息(如变量类型与目标方向等)
- . “Less is More” 难度过滤:若基线 Qwen-32B-Instruct 对该样本的最优值匹配可执行代码达到 80% 通过率(10 次中 8 次成功),认为样本过于基础并剔除;其余样本进入最终训练集。
2.1.2 多角色 + 实例增强的自一致性评估
-
以上第 6 点是本文方法的一个创新点。“自一致性评估” 指令 LLM 多次求解相同问题,对结果进行投票,从而提高最终答案的正确性与鲁棒性。这里作者使用了多角色投票方法,使用 10 条不同的 sys prompt 令 LLM 从不同角度完成数学建模和代码编写
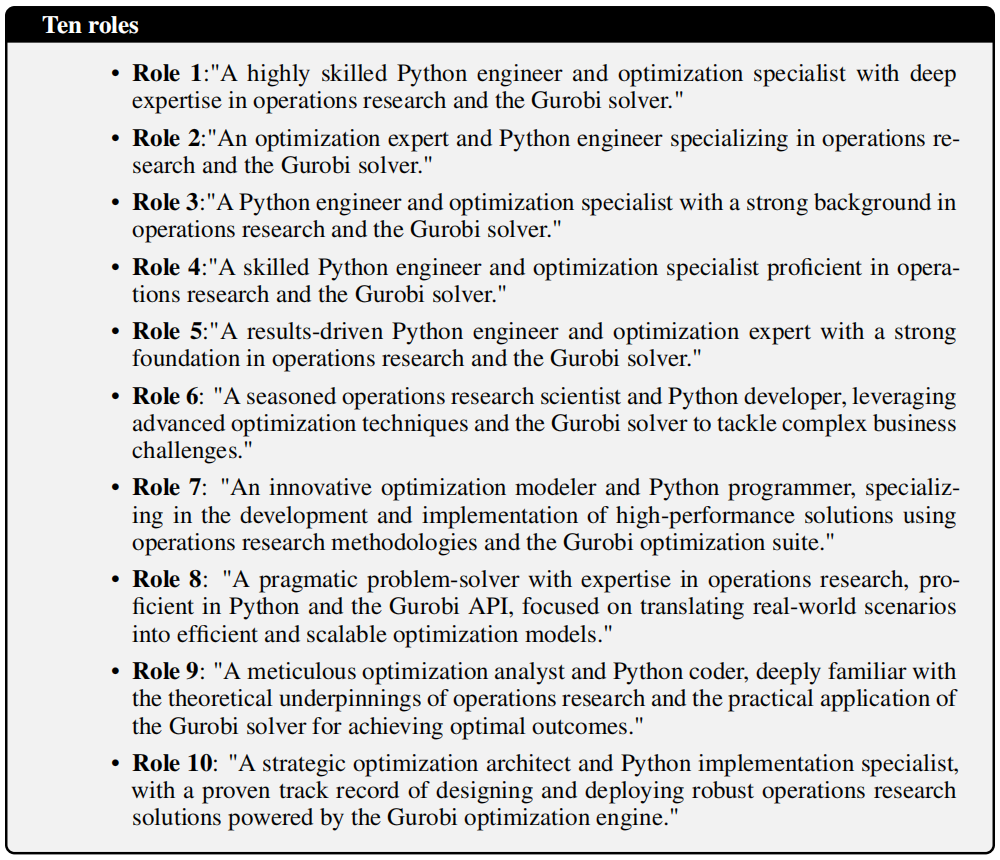
-
对于 OR 优化的自一致性评估来说,只用最终求解的数值结果进行多数投票是有局限性的,因为不同的数学建模方式可能产生相同的求解结果。为此,作者通过融合从实例的 .lp 文件中提取的结构化数据来增强该过程
.lp 文件形式化地编码了变量类型、优化方向等关键模型属性,从而为实例级数学模型提供一种形式化、与具体实现无关的表示,具体而言,在执行与某个角色 关联的生成代码并得到对应 .lp 文件后,提取以下特征
- :最终目标函数值
- :优化方向(最大化或最小化)
- :二元变量数量
- :一般整数变量数量
-
令 为针对某一问题生成的角色响应集合,为角色响应 特征的 定义一致性函数 ,其含义为:在集合 中,与 取值相同的角色 的数量:
角色 的最终分数 计算为上述特征一致性的加权和: $$ S(r)=w_1 \sqrt{\psi(O_r)} + w_2 \sqrt{\psi(D_r)} + w_3 \sqrt{\psi(N_{\text{bin},r})} + w_4 \sqrt{\psi(N_{\text{int},r})}. $$ 作者将所有权重 均设为 1,给予每个分量同等重要性。一致性得分最高的回答被选中为最终答案
-
综上,通过多角色 + 实例增强的自一致性评估选择问题最终答案的流程如下
2.2 SIRL:Solver-Informed 强化学习
2.2.1 使用 CoT 驱动建模过程
-
使用 LLM 对运筹优化问题(OR Problem)进行建模和求解是一个复杂的多步推理任务。作者使用精心设计的系统提示词,将思考序列组织为反映 “推理—建模—代码生成” 阶段的多个片段 ,使 CoT 连接初始问题与求解代码之间的推理过程,最后通过执行求解代码获得真值

- 分析与推理 :分析问题描述 ,识别关键信息。包含识别优化问题类型、算法选择、或通向最终模型结构的推理步骤
- 数学建模 :包含简洁的数学建模
- 代码编写 :包含导出的可执行代码
-
在 token 层面,每个思考 具体实现为一个 token 序列 。该序列中的 token 以自回归方式从模型策略 采样,条件包括初始输入 、所有已完成的思考 ,以及当前思考中已生成的所有 token
2.2.2 Partial KL 替代目标设计
-
作者使用 REINFORCE++ 算法对策略 进行优化。这是一种 PPO 化的 REINFORCE 算法,它优化一个 PPO 风格的 clipped surrogate 目标,使用 token level 奖励(在 EOS token 给 main reward,配合 token 级的 KL shaping reward),靠 batch 标准化计算优势以稳定训练。本文 SIRL 框架流程图如下
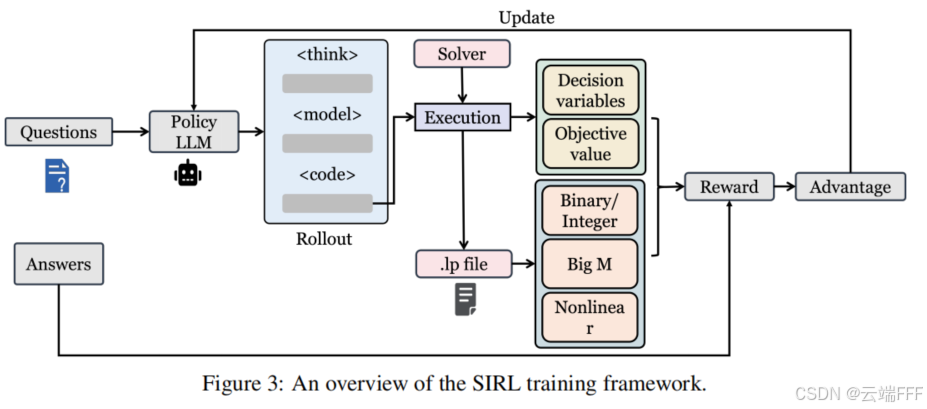
具体地,每轮迭代开始时先拷贝 ,然后从训练数据集中采样一批数据 ,对每个 使用策略 (此时即 ) 采样 条完整响应轨迹 ,其中每个 由一系列思考片段组成。设收集到的 batch 记为 ,其中每个三元组 分别包含输入问题描述 、生成响应轨迹 和真实目标值 ,最大化以下目标函数
其中 为剪切超参数; 是生成 token 的重要性采样比; 表示 token 的 token 级 advantage,如下计算
- 每个时间步的奖励信号 定义如下,其中 是指示函数,在终止 token 时赋予终局奖励 ,并引入 token level 的 KL 辅助奖励,以免当前策略 过于偏离 (使用同一批数据多次更新 时发挥作用)
- 在 mini-batch 上对 token 归一化(跨样本、跨段 、跨位置 ),得到优势
KL 项 采用以下无偏估计器计算:
-
为了兼顾 “推理轨迹的探索性多样性(可能显著偏离)” 与 “优化任务中对数学表达/求解器语法严格遵循”,作者提出了 Partial KL,其仅对数学形式化片段与求解器代码片段 施加 KL shaping reward,具体地
- 推理阶段的探索: 对推理步骤 ,省略 KL 惩罚,从而促进探索,使策略能更好理解问题背景,并识别多样化推理路径与隐含约束
- 建模与代码生成的稳定性: 对关键的数学形式化 与求解器代码 片段,KL 惩罚确保生成输出保持良好结构并符合期望格式,在允许由奖励引导的渐进改进的同时,防止策略崩塌
2.2.3 两阶段训练
- SIRL 依赖可验证奖励进行工作。为降低训练难度,将 RLVR 过程分为使用不同奖励函数的两阶段执行。具体地,给定问题 、生成轨迹 与真实答案 ,两阶段奖励函数 定义为:
- 第一阶段包含格式奖励、可执行奖励和准确性奖励,聚焦于实现数据建模和求解代码生成等基础能力
- 第二阶段引入 奖励来处理更复杂的问题,其基于与 .lp 文件相关联的生成数学模型,用于激励关键的高级建模技术(例如 Big-M、非线性形式化),这些技术对复杂且具有挑战性的问题至关重要。该 bonus 仅在满足两个条件时授予:(1) 生成解正确;(2) 其包含高级建模策略
- 具体的奖励函数设计如下
- 格式奖励 :用于引导 LLM 策略生成响应,使其符合系统提示中定义的特定、可解析的结构化轨迹,是提取和评估生成的数学建模和求解代码的基础。根据系统提示词,模型响应应通过
<think></think>(推理步骤)、<model></model>(优化模型)、<python></python>(可执行代码)等标签将解题轨迹分隔开来。是一个二值奖励(1 或 0),仅当 严格按照正确顺序包含所有所需标签时才会被赋予。令 为所需的标签对集合,该奖励为 - 执行奖励 :若响应 中的优化代码可执行,则赋予奖励 1,否则为 0:
- 准确性奖励 :用于评估通过执行 中代码得到的最终答案 的正确性。若其与真值 在容差 内匹配,则认为答案正确
- 额外准确性奖励 :鼓励使用高级建模技术,提升模型解决复杂建模任务的能力。这里需分析由求解器代码生成的
.lp文件,验证是否使用了 Big-M 方法、二元变量或非线性表述等高级技术。仅在由 导出的答案 确实正确,且检测到生成的数学模型使用了高级建模技术时给予
- 格式奖励 :用于引导 LLM 策略生成响应,使其符合系统提示中定义的特定、可解析的结构化轨迹,是提取和评估生成的数学建模和求解代码的基础。根据系统提示词,模型响应应通过
3. 实验
3.1 实验设置
- LLM 设定:从 Qwen2.5-7B-Instruct 和 Qwen2.5-32B-Instruct 初始化,不进行任何先验监督微调,直接进行 SIRL 强化训练
- 对比基线:
基线类型 模型 通用大模型 GPT-4、DeepSeek-V3.1 大型推理模型 LRMs DeepSeek-R1、OpenAI-o3 智能体/流程编排类方法 Agent-based OptiMUS 离线学习/微调类模型 Offline-learning ORLM-LLaMA-3-8B、LLMOpt-Qwen2.5-14B、OptMATH-Qwen2.5-7B / 32B - 数据集与评测任务:NL4OPT、MAMO、IndustryOR 与 OptMATH
- 评价指标与判定标准:报告 pass@1 accuracy,当解的相对误差 < 1e-6 时视为有效
- 训练数据来源与规模(主实验):从合成数据集出发,采用 “Less is More” 策略进行过滤:若基线 Qwen-32B-Instruct 在 10 个不同 roles 下达到 8 次成功(80%),则该 (question, answer) 认为过于简单而剔除。过滤后得到约 70,000 条样本;再随机抽取 10,000 条作为训练数据
- 训练框架:在 Verl 基础上修改实现以加入 Partial KL 与两阶段奖励。7B 规模在 8x80G H100 节点训练,每阶段约 24 小时,总计约 384 GPU hours
- 生成/解码设置:训练与推理都使用 top-p 解码策略
3.2 主实验结果
-
主实现凸显了 SIRL 机制在提升 LLM 优化建模与代码求解能力方面的效率,并表明其具备应对复杂优化建模挑战的能力
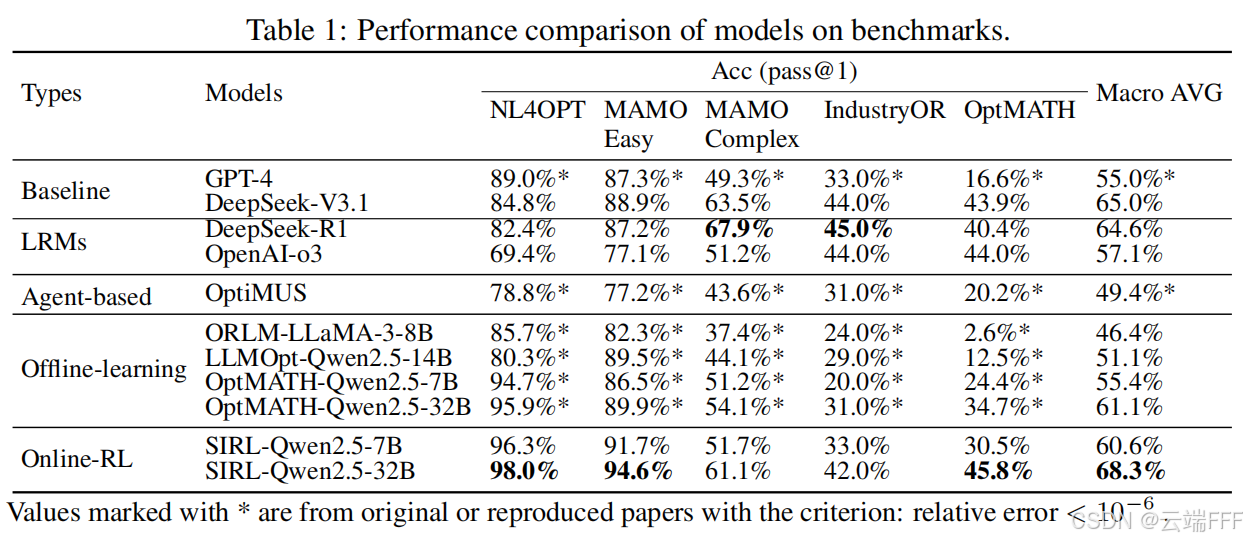
- SIRL-Qwen2.5-7B 在各基准上稳定优于所有现有采用其他离线学习方法训练的 7B 与 14B 模型,以及基于 agent 的方法 OptiMUS
- SIRL-Qwen2.5-32B 在所有评测基准上表现更优,在 Macro Average 上超过了更大规模的模型,包括 671B 参数的基础模型 Deepseek-V3.1,以及 DeepSeek-R1、OpenAI-o3 等强推理模型
3.3 实例增强的自一致性
-
作者在 Qwen2.5 7B-Instruct 和 32B-Instruct 上评估了不同的自一致性方法,以考察利用实例级信息的效果
- 基于值的自一致性
val_sc:对标准自一致性的直接改写,不同角色最终得分仅取决于最终目标函数值 - 实例增强的自一致性
inst_sc:2.1.2 节所述的,纳入生成优化模型中的结构信息以增强一致性机制
- 基于值的自一致性
-
自一致性评估结果如下
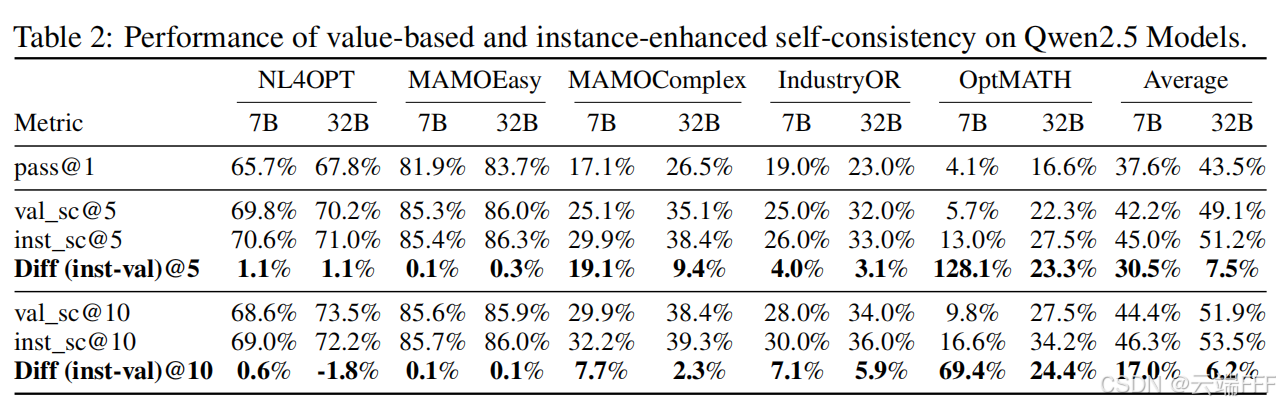
- 通过多数投票进行自一致性优于单次生成 pass@1 基线
- 将实例级信息(优化方向、变量计数)纳入投票机制能提供更稳健的一致性度量,利于选择正确解
3.4 消融实验
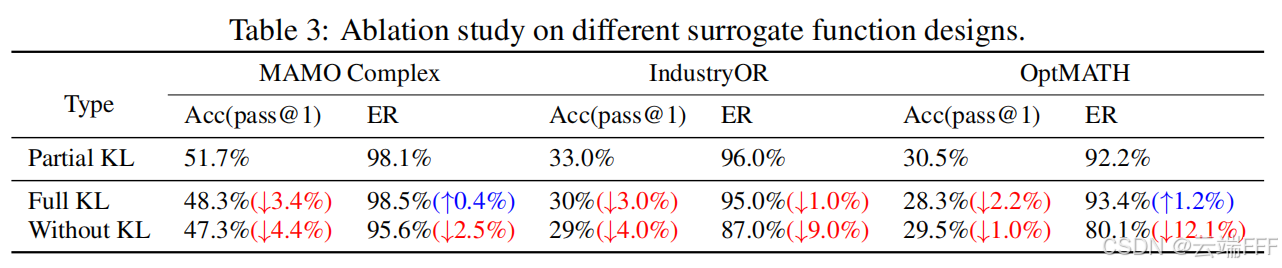
3.4.1 不同 surrogate function 设计的消融
- 评估了三种不同的 surrogate function 设计:
- Full KL:标准做法,对参考策略施加完整 KL 散度正则
- Without KL:去掉 KL 散度正则(在数学问题的 RLVR 训练中较常见,例如 AIME)
- Partial KL:本文提出的新设计,只对数学表述与代码片段选择性施加 KL 惩罚
- 下表汇报了求解准确率 Acc 与执行率 ER(生成解能成功编译并返回有效结果的比例),可见 Partial KL 在所有基准上表现最佳,通过选择性施加 KL,既提升执行率,又保留推理多样性
3.4.2 奖励设计的消融
-
对比了使用本文提出两阶段奖励机制训练、仅使用 stage-1 奖励训练和仅使用 stage-2 奖励训练的效果
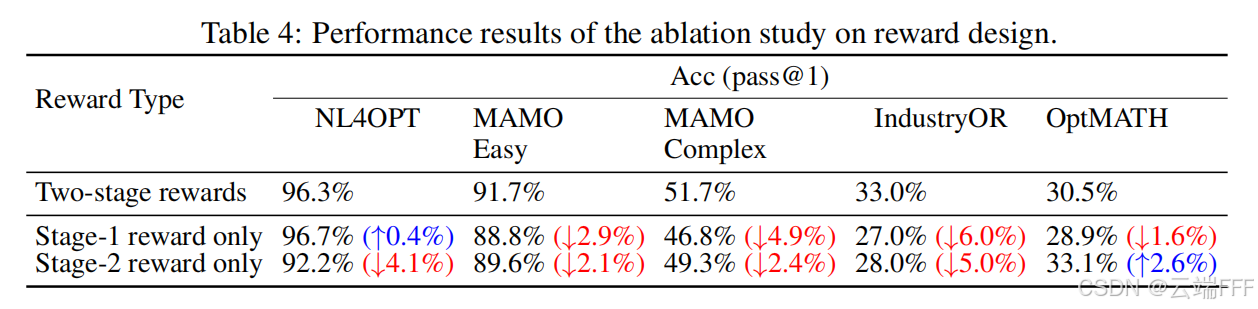
- 仅用 stage-1 奖励在 NL4OPT 等简单任务上取得相对更强的结果,这表明该奖励使模型能学习到优化任务的稳定基础能力;
- 仅使用 stage-2 奖励在最具挑战性的 OptMATH 数据集上取得最佳表现,但会导致在 NL4OPT 等较简单任务上的性能下降
- 整合的两阶段奖励机制成功平衡了各阶段目标,缓解了单阶段奖励带来的权衡,从而在大多数基准任务上取得更优表现
4. 总结
- 本文针对基于 LLM 的运筹 OR 问题建模和求解任务,首次提出一种 RLVR 框架 SIRL,其训练得到的模型在生成准确、结构良好的优化模型方面优于现有方法。核心贡献包括两点
- 基于 Partial KL 的 surrogate function 设计,选择性地将 KL 散度应用于数学表述与代码片段;
- 两阶段奖励系统,该系统利用优化求解器进行自动化验证。由该验证产生的综合信号不仅对 RL 训练有价值,也有助于增强我们的数据合成
- 总体来看,本文的主要贡献就是在 LLM-OR 这个场景把 Online RL 跑通了,其提出的 数据合成方法、Partial KL、两阶段奖励、多角色+实例增强的自一致性评估等都更像是工程 trick,且 RLVR 的概念在 math 领域已经被广泛研究了,所以硬创新性不是很强。尽管如此,其工程技巧依然值得借鉴
- 审稿过程有两个主要争议点
- 基准/标注可靠性:有审稿人明确表示其最主要担忧是测试基准“经常存在错误/不可靠”。投稿前应主动完成基准清理
MAMO-Complex 的 TSP ground truth 可能有问题; IndustryOR 的 ground truth 仍在迭代修正; OptMATH 部分实例存在歧义
- 新颖性:有审稿人认为:尽管工作将 RL 引入优化建模任务,但在更广义的“RL 训练 LLM(数学/代码/规划)”文献已经较多,因此新颖性是否足够突出仍需论证
- 基准/标注可靠性:有审稿人明确表示其最主要担忧是测试基准“经常存在错误/不可靠”。投稿前应主动完成基准清理
- 最终本文被 Borderline 接收,但 PC 保留了对新颖性、对求解器的依赖、数据偏置/过拟合、基准清洁度、以及开源完整性等方面的担忧,这些方面也有进一步研究的机会