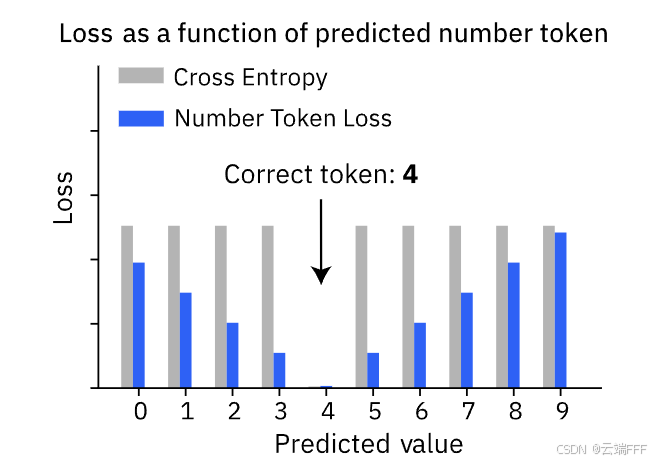
论文理解【LLM-回归】——【NTL】Regress, Don‘t Guess--A Regression-like Loss on Number Tokens for Language Model 尽管 LLM 在文本生成方面表现出色,但它们缺乏对数字的自然归纳偏置,导致在涉及数值的任务中表现不佳。本文提出了一种新的损失函数——Number Token Loss (NTL),以增强语言模型在数值任务中的表现 2025-10-16 机器学习 > 论文理解 #数值回归 #Transformer-Based
Transformess库(5)—— Datasets datasets 是一个简单易用的数据集加载库,可方便地从本地或 HF hub 加载数据集,并完成数据划分、清洗、数据集和加载器构造等工作 2025-10-08 常用库 > Transformers库 #Transformers库
Transformers库(4)—— Model 本文介绍了 Transformers 库的 Model 组件相关 API 的用法,包括模型的基本架构、预训练模型的加载、模型的微调等 2025-10-03 常用库 > Transformers库 #Transformers库
Transformers库(3)—— Tokenizer 本文介绍了 Transformers 库中的 Tokenizer 组件相关 API 的用法,包括其基本概念、使用方法和在不同任务中的应用。Tokenizer 是将原始字符串转换为模型可以计算的数值形式的工具 2025-10-02 常用库 > Transformers库 #Transformers库
Transformers库(2)—— Pipeline Pipeline 是 Transformers 库的一个高层次封装类,它可以将数据预处理、模型调用、结果后处理三部分组装成流水线,为用户忽略复杂的中间过程,仅保留输入输出接口 2025-10-01 常用库 > Transformers库 #Transformers库
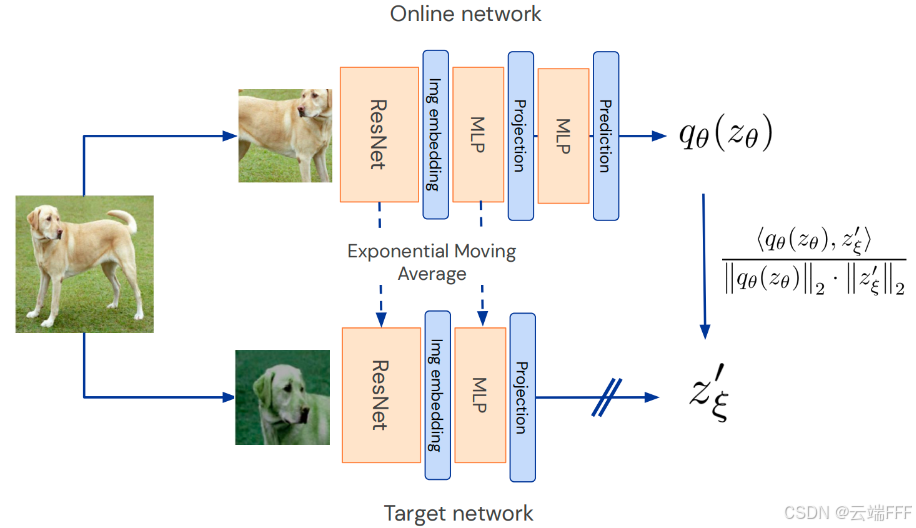
论文理解【CV-对比学习】——【BYOL】Bootstrap Your Own Latent-A New Approach to Self-Supervised Learning BYOL通过两个神经网络的互相学习,提出了第一种无需负样本的新型自监督图像表示学习方法,且在多个基准测试中超越了当时的 SOTA 2025-09-19 机器学习 > 论文理解 #自监督预训练 #对比学习 #CV
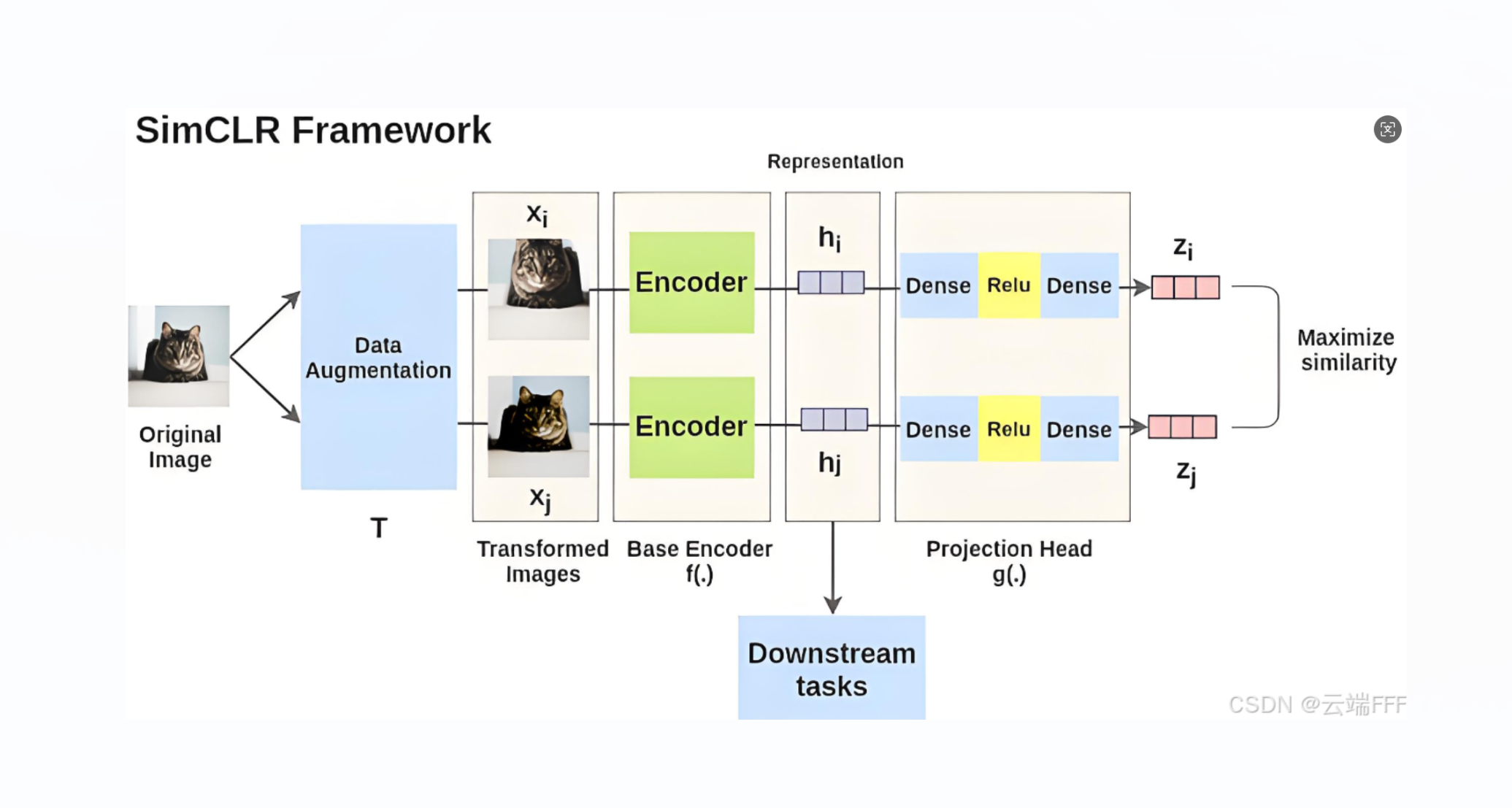
论文理解【CV-对比学习】——【SimCLR】A Simple Framework for Contrastive Learning of Visual Representations SimCLR 是一种简洁的自监督对比学习方法,通过强数据增强、非线性投影头与大批量训练,在无标签条件下学习判别性表示,在线性评估与下游任务中表现优异,大幅减少对人工标注的依赖。 2025-09-15 机器学习 > 论文理解 #自监督预训练 #对比学习 #CV
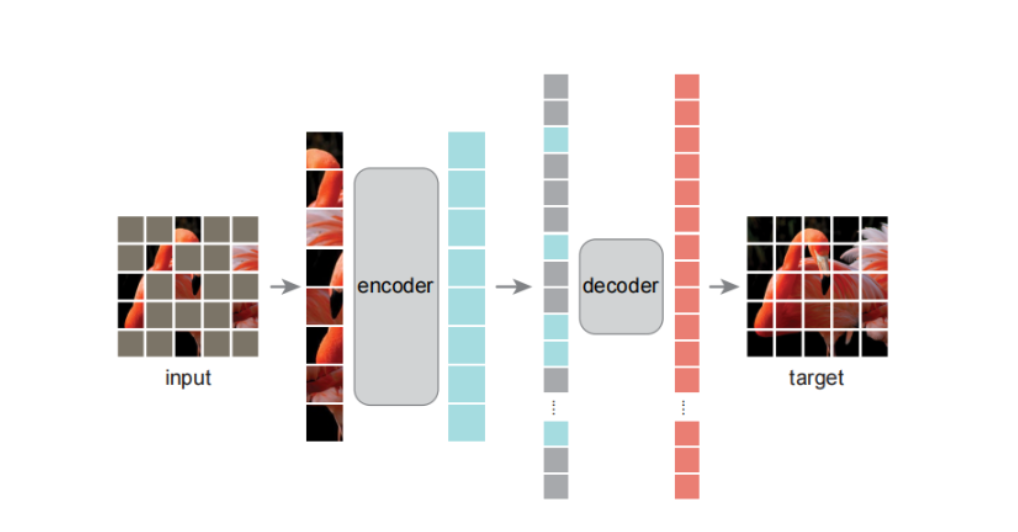
论文理解【Vision Transformer】—— 【MAE】Masked Autoencoders Are Scalable Vision Learners MAE 是一种 Transformer-Based CV backbone,其核心在于使用了类似 Bert 模型的训练机制,通过高比例随机 mask 图像 patch,使用非对称 Encoder-Decoder 架构进行自监督训练重建图像,实现了高效的视觉特征学习。 2025-09-10 机器学习 > 论文理解 #自监督预训练 #CV #Transformer-Based #Vision Transformer
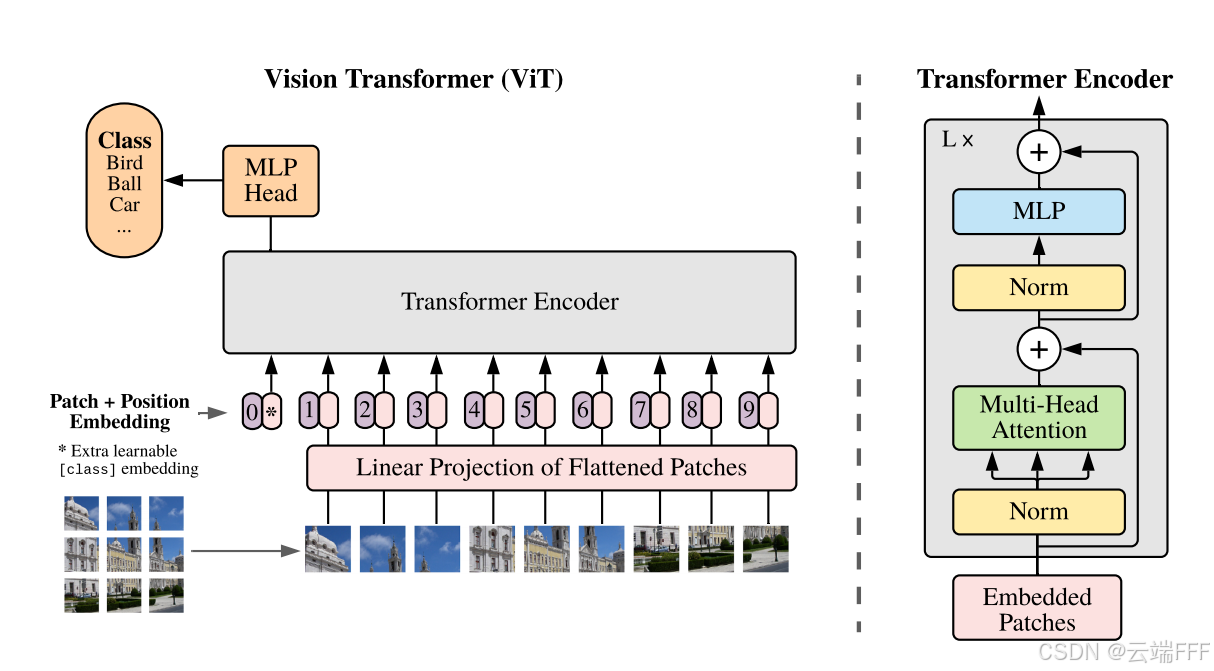
论文理解【Vision Transformer】——【VIT】An Image is Worth 16x16 Words-Transformers for Image Recognition at Scale VIT将图像切分成16x16的patch块,通过标准Transformer进行图像分类,在引入尽量少图像归纳偏置的情况下,验证了纯Transformer在图像分类任务中的有效性,为CV和NLP的模型统一奠定基础。 2025-09-10 机器学习 > 论文理解 #CV #Transformer-Based #Vision Transformer #CV backbone