论文理解【LLM-回归】——【NTL】Regress, Don‘t Guess--A Regression-like Loss on Number Tokens for Language Model
- 首发链接:论文理解【LLM-回归】——【NTL】Regress, Don‘t Guess--A Regression-like Loss on Number Tokens for Language Model
- 文章链接:Regress, Don't Guess -- A Regression-like Loss on Number Tokens for Language Models
- 代码:tum-ai/number-token-loss
- 介绍页:Regress, Don’t Guess
- Openreview: Regress, Don't Guess
- 发表:ICML 2025
- 领域:LLM 浮点回归
- 一句话总结:训练 LLM 通常使用的交叉熵损失不适用于数值回归,因此本文提出了数字token回归型损失函数(Number Token Loss, NTL),该损失通过引入数值接近性的 Lp 范数或 Wasserstein 距离,在几乎不增加计算开销的情况下显著提升了数学与回归任务的数值推理能力,且可无缝集成至大规模语言模型
- 摘要:虽然语言模型在文本生成方面表现出色,但它们在生成数字时缺乏天然的归纳偏置,因此在涉及定量推理的任务中(尤其是算术任务)表现不佳。其中一个根本限制是交叉熵损失(Cross Entropy loss)的性质,它假设标称尺度(nominal scale),因此无法传达生成的数字token之间的接近程度。对此,我们提出了一种完全在token层面上运行的类似回归的损失函数——数字token损失(Number Token Loss, NTL)。NTL有两种形式,分别最小化真实与预测数字token数值之间的Lp范数或Wasserstein距离。NTL可以轻松集成到任何语言模型中,并在训练期间与交叉熵目标共同优化,而不会增加推理时的计算开销。我们在多个数学数据集上评估了该方法,发现其在数学相关任务中持续提升性能。在一个回归任务上的直接比较表明,尽管NTL仅在token层面运行,其性能可与专门的回归头(regression head)相媲美。最后,我们将NTL扩展到30亿参数规模的模型,并观察到性能提升,表明其在大语言模型中的无缝集成潜力。我们希望这项工作能够激励LLM开发者改进其预训练目标。
1. 方法
1.1 语言模型的回归能力问题
- Transformers 类模型如今已广泛应用到各种科学领域,在这些领域中有大量的表格/数值数据,模型往往要同时输出自然语言文本和高精度数字。但显然,由于 LLM 使用的 CE 损失而非回归任务常用的 MSE 损失进行训练,其预测数字的能力不佳,具体而言有以下问题:
- 缺乏数值归纳偏置:LLM擅长处理自然语言,但在处理数字时缺乏“理解数字大小或接近关系”的能力。例如,它可能认为“3”和“9”同样接近“2”,因为它们在token空间中等价
- 交叉熵损失不考虑数值关系:CE损失将所有错误预测视为同样错误,即“预测3代替2”和“预测9代替2”在损失上是一样的,忽视了数值距离的接近性
- Token化方式破坏数字结构:例如,“123” 可能会被拆分成多个数字token,导致模型难以恢复原始数值的结构和含义
- 嵌入学习无结构引导:数字token的embedding与普通文本token一样被随机初始化并学习,缺乏数值之间的连续性或位置关系
- 顺序预测无法捕捉高位数字的重要性:生成数字预测时,模型无法理解高位数字的重要性大于低位数字
- 过去的研究中大都尝试绕过以上问题,通过 “打补丁” 的方式提升 LLM 的数字预测能力,包括
- 任务重构类方法:
- 引入CoT,引导模型按步骤推理而不是直接输出答案;
- 引入验证器,生成多个备选答案后用外部模块进行校验;
- 调用计算器等外部工具做数值运算,模型只负责语言部分
- 模型结构改造类方法:
- 数字反序生成:从最低位开始生成数字,让模型更好地学习进位规则
- 固定数值嵌入:为数字token设计位置敏感的嵌入,如 Regression Transformer 和 xVal 方法
- 引入回归头:将 Transformer-based 模型作为特征提取器做标准回归任务,在早期科学任务中较常见。缺点是这些模型往往针对任务定制,难以和通用自然语言生成任务结合,且通常要求将数值范围压缩到某个固定区间
- 数字反序生成:从最低位开始生成数字,让模型更好地学习进位规则
- 修改损失函数:
- Gaussian Cross-Entropy (GCE):对 one-hot 的 ground truth 标签进行高斯平滑,使真实值附近的数字 token 也获得部分概率质量。这种方式的问题在于平滑处理完全是人为制造的,标签中并没有真正的不确定性,所以这 technical 提供了错误的标签
- 任务重构类方法:
- 作者认为上述方法并没有根本解决问题,因为它们或依赖于额外模块,或不适用于预训练阶段
1.2 本文方法
-
本文提出的 Number Token Loss(NTL)的核心思想是:对于所有数字token,损失随着其预测值与真实值的差距增大而增大,就像回归任务中的损失那样
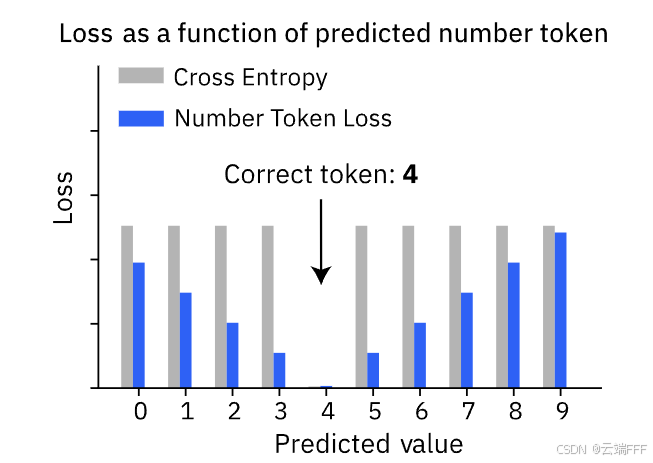
-
NTL 的基本思想是:任何 LLM 的词表中都有一些 token 对应数字而非文本,作者希望将这些数字 token 的对数几率与它们的数值结合起来计算损失,使其能够考虑数字标记的数值接,从而有效地增强传统 CE loss。注意 NTL 仍基于传统的 tokenize 和 embedding 方法处理和生成数字,因此其不引入额外的回归头,而是直接在 token 头上计算类似回归的损失 NTL。作者提出了两种损失增强方案:
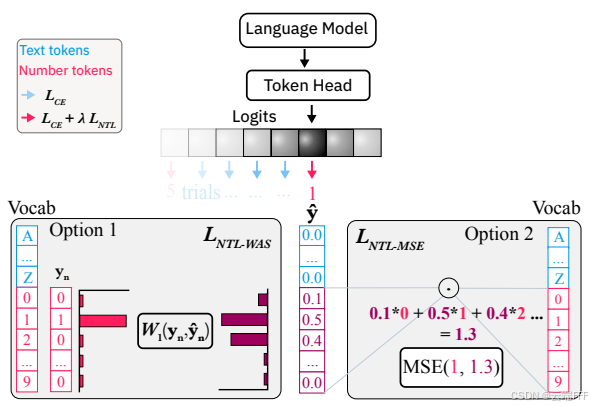
- NTL-WAS:使用 Wasserstein‑1 距离衡量预测分布与 one‑hot 标签分布之间的差异
- NTL-MSE:先计算预测分布中各数字对应数值的期望,再计算和真实数值之间的 MSE 误差(虽然直观,但可能存在一些不理想的局部最优点)
1.2.1 NTL-MSE
- 设语言模型 输出词表上的 softmax 概率分布,考虑第 个 token 的预测:
- 将上下文 输入模型,得到 token 的概率分布
- 设数字token(如)在词表中的索引范围为 ,用 表示数字 token 上的预测概率向量
- 设 表示数字 token 到数值的映射(如 等),通过向量点积计算模型预测的 token 的数值期望
- 设 batch 中共有 个数值token,NTL-MSE 是
模型预测数值期望和真实标签间的平均 MSE 损失,即MSE 使用 p=2 的 Lp 范数刻画距离,上式可以推广至其他 Lp 范数,对应 MAE 或 Huber loss 等
- 特点与局限
- 优点:简单直观,直接得到数值的“期望”并计算回归误差;
- 缺点:存在非唯一极小值问题(non-unique minima)
例如:若真实值为4,模型预测50%概率为0、50%概率为8,则期望仍为4,损失为0,但预测显然是错误的
1.2.2 NTL-WAS
-
设某个数字 token 的真实one-hot分布为 ,模型预测分布为 ,NTL-WAS 试图直接刻画 和真实分布 之间的差异
通常我们用 KL 散度 描述用分布间差异,但在这里行不通,因为 KL 散度就是 的交叉熵减去 的信息熵,它和训练 LLM 使用的标准交叉熵只差了一个常数( 的信息熵),因此还是缺乏数值感知能力。参考:信息论概念详细梳理:信息量、信息熵、条件熵、互信息、交叉熵、KL散度、JS散度
-
作者使用最优传输(Optimal Transport, OT)中的最小搬运代价,即 Wasserstein-1 距离来描述分布间差异
Wasserstein距离可以被理解为将一个概率分布转化为另一个概率分布所需的最小代价。这个代价是基于两个分布之间样本点的移动距离来计算的。 如下图所示,通过按中间的灰色箭头移动每个点对应的概率密度,可以将蓝色分布转换为红色分布,Wasserstein 距离可以理解为最小化这些箭头的平均平方长度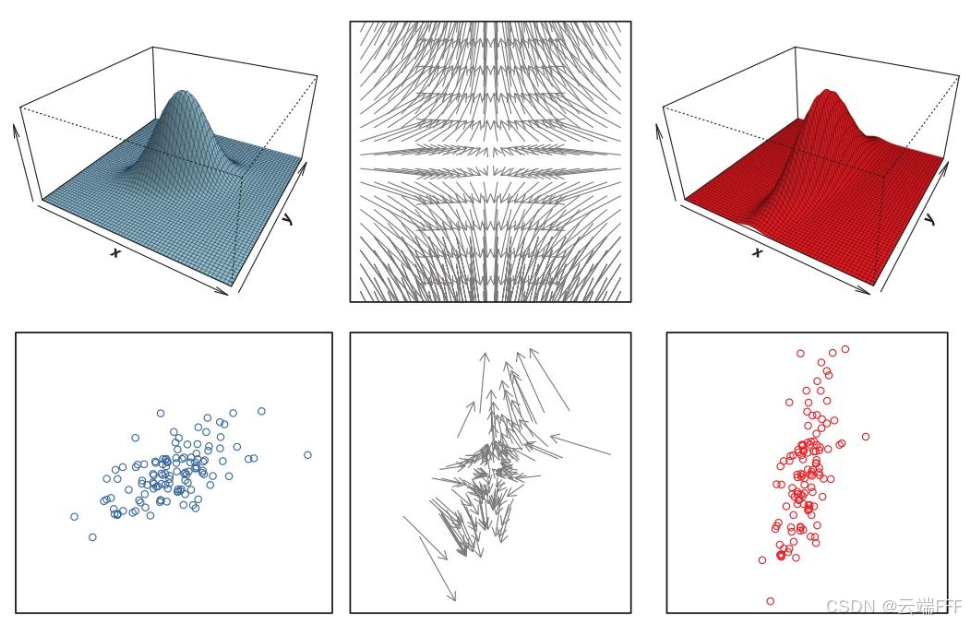
-
Wasserstein-1 距离(距离)是最常用的一种幂次为1的Wasserstein距离,其一般形式为
设 表示度量空间中的两个点,联合分布 代表最优搬运规划,描述从 搬运到 的最佳概率质量, 表示两点间搬运代价。在 LLM 中,上式退化到离散形式
其中
-
Wasserstein-1 距离难以直接计算,因为通常需通过线性规划求解 ,计算成本高。但作者发现当标签是 one-hot 分布,数值 token 的索引与其数值一一对应,且使用欧式距离作为搬运代价时,最优传输问题退化为直接将全部质量从预测分布“搬运”到真实值上的最小总距离,即以下闭式解
其中 表示将第 个数值 token 预测为 token 的概率, 表示 个数值 token的真实数值, 表示 token 对应的真实数值,这就是作者提出的 NTL-WAS 损失。
-
以外,为了适配非 one-hot 标签的情况(比如对数字标签进行平滑处理),作者还提出一种变形。当数字 token 索引 根据数值 排序且这些值等距分布,那么可以使用累积分布函数 CDF(⋅) 来计算 Wasserstein-1 距离
作者默认使用 ,因为它比 快 230 倍,且不要求数值 token 等距分布,因此适合和自然语言数据一起训练
1.3 小结
-
作者通过系数 将 NTL 损失附加到普通的交叉熵损失上,得到最终损失
其中 的两个版本对所有非数值标记都产生零损失,默认取
-
下图对交叉熵损失和两种 NTL 损失进行了可视化,图中真实标签是 4,假设概率全部分配在 3 和 5 上
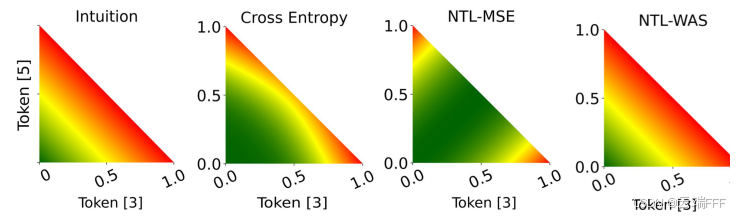
由绿到红表示损失越来越大,可见 NTL-WAS 避免了 NTL-MSE 的非唯一最小值问题,和期望行为(最左侧)最接近
2. 实验
2.1 实验设定
- 模型:使用 T5-base 和 T5-large 用于主要实验;Granite-3.2B 和 T5-3B 用于大模型扩展验证
- 数据集:包括DeepMind的数学问答数据集、rJokes数据集和GSM8k数据集等
- 算术与数学推理:
AddSub、MultiArith、SVAMP、GSM8K用于评估数学推理能力;使用准确率指标 - 回归任务:
rJokes幽默评分回归,用于比较NTL与传统回归头;使用均方根误差(RMSE)、皮尔逊相关系数(Pearson r)指标 - 文本任务:
MultiRC多句阅读理解,用于验证NTL不会破坏文本生成能力
- 算术与数学推理:
- 评测指标:
- 算术与数学推理:准确率(Accuracy)。
- 回归任务:均方根误差(RMSE)、皮尔逊相关系数(Pearson r)。
- 文本任务:Token准确率、BLEU、ROUGE-1。
2.2 实验结果
2.2.1 多任务数学数据集
-
多任务数学数据集上,NTL 提升了插值和外推性能,这证实了通过微小的、架构无关的损失修改可以有效提升大型语言模型中的数字表示
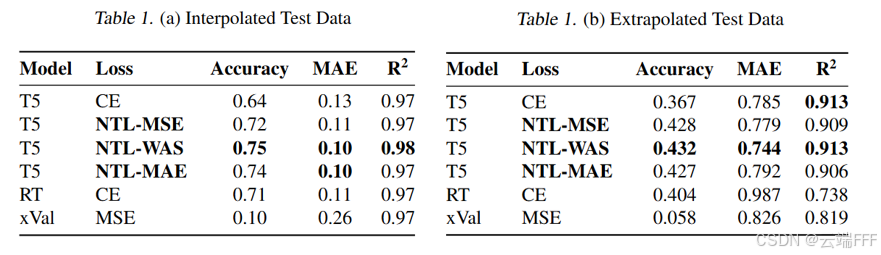
对比方法中xVal使用了回归头,其表现不佳的原因可能是由于所数据集中数字取值范围很广,xVal 的有效数字范围限制在 因此实验中对 xVal 的数据集进行了以 为比例缩放,这意味着较大的数字无法再被模型充分区分,因为它们的嵌入变得非常相似
-
作者在数据集的一个子集上进行消融实验,该子任务由基本的整数算术问答对组成,其中输入是一个包含算术表达式的简短自然语言问题,输出是一个单独的整数,共 10 万条数据,评估插值和外推表现
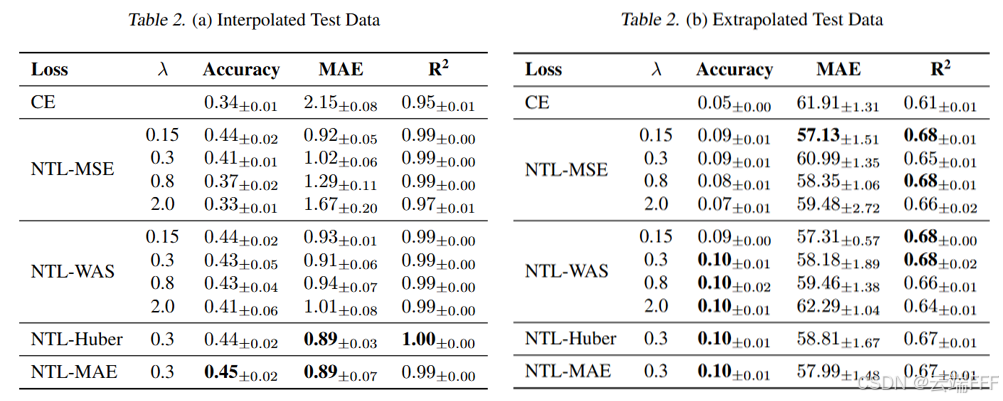
NTL 的两种变体相比于仅使用 CE 损失都能提高算术性能。此外,NTL-WAS在插值和外推测试集上的表现大多优于NTL-MSE, 对两种变体都表现最好
-
作者进一步和高斯交叉熵 GCE 对比,并考虑将其和 NTL 混合使用的效果(此时使用 )
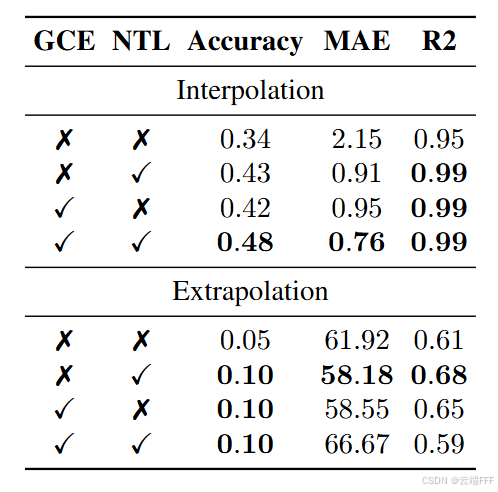
尽管NTL和GCE都提高了模型性能,但NTL通常更优;插值测试中 NTL 和 GCE 组合使用效果最佳,说明某些任务中 NTL 和 GCE 可以相互受益
2.2.2 回归任务
-
理想情况下,LLM 应能够解决甚至完全专注于预测数值的任务,例如估算分子的一个属性。这时通常将 Transformer 骨干视作特征提取器,并引入回归头,从而允许使用 MSE 等适当的回归损失函数
-
为了测试 NTL 仅基于 token 解决回归任务的能力,作者在 rJokes 数据集上进行实验,该数据集用于预测笑话的幽默水平
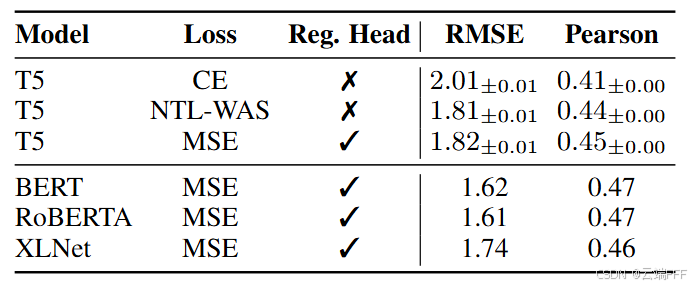
- NTL 相比标准 CE 有显著提升
- 带回归头的 BERT、RoBERTA 和 XLNet 在表现上优于使用 NTL-WAS 训练的T5,但作者将此归因于这些模型的参数数量几乎是 T5-small 模型的两倍,因此性能差距不显著
2.2.3 模型无关性
-
作为一种损失函数,NTL可以应用于训练任意模型,包括 Mamba 等超出 Transformer 基础的 LLM。作者测试了使用 NTL 训练仅 Decoder-only 模型的 GPT-2 和 IBM Granite 的有效性
-
作者构造了一个算术乘法任务,令有 位和 位的两个数字相乘,在训练时 ,测试时 。汇报未见测试样本的平均绝对百分比误差(MAPE),涵盖内插和外推
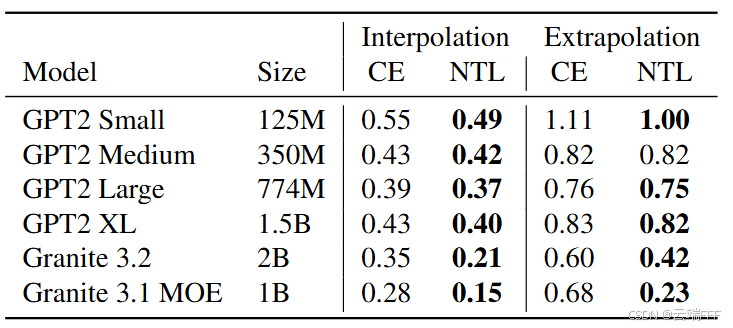
- NTL 在乘法任务的 MAPE 方面一致提高了性能
- NTL 对外推能力的提升比内插更显著,这一点尤为重要,因为数学任务中的外推能力通常较差
-
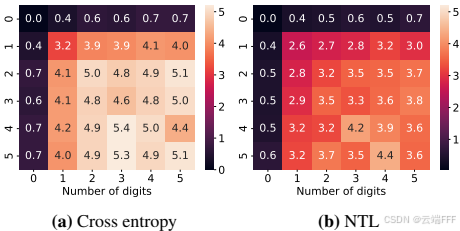
作者还分析了使用 NTL 与仅使用 CE 相比在乘法任务上训练的样本效率。下图显示了训练 GPT2 Small 令 MAPE 低于 0.5 所需的 epoch 数量,可见 NTL 所需的 epoch 更少
2.2.4 其他
- NTL对不同的分词方式都很有效:以上实验中 T5 模型的 NTL-WAS 实现依赖于定制的单个数字(single-digit)分词器,该分词器基于 SentencePiece Tokenizer,并包括一些由多个数字(multiple-digits)组成的 token。作者在 rJokes 和数学问答数据集上进行了进一步实验,考察不使用 NTL-WAS 的单数字分词器以及支持多数字 token 的更通用 NTL-WAS 版本。结果证实 NTL-WAS 在两种分词方案下均有效,其中单数字分词器与 NTL-WAS 的结合表现最佳。一个与多数字分词相关的问题是,某些 token 的数值非常大,会对损失产生不成比例的影响,特别是在数字 token 分布不均匀的情况下
- 在标准语言建模任务中 NTL 不会影响性能:作者在重新格式化的 MultiRC 数据集上进行实验,结果表明在一项需要文本理解的任务中,使用 NTL 进行训练不会妨碍性能
- NLT 在大规模模型上表现良好:作者在 GSM8k 数据集上训练了具有30亿参数的 T5 模型,使用 NTL 进行训练将准确率从 13.5% 提高到了 17.7%,与 Gemma-2B 等更适合数学推理的大型语言模型的性能相匹配
3. 结论
- 该研究针对 LLMs 在数值推理和算术任务中表现欠佳的问题,提出了一种数值 token 损失 NTL,旨在增强模型对数字的感知能力。作者指出,传统的交叉熵损失(Cross-Entropy, CE)仅在名义尺度上度量 token 差异,无法体现预测数字与真实数字的接近程度,从而限制了模型的数值推理能力。NTL通过在训练目标中引入数值距离信息,以回归式损失形式优化数字 token 的预测,其核心包括两种实现:
- NTL-MSE:将数字 token 的预测概率与其数值加权,计算均方误差;
- NTL-WAS:基于离散的Wasserstein-1距离度量预测分布与真实分布的差异,更好地避免局部最小值问题。
- NTL 通过增强语言模型对数值数据的感知能力,显著提高了模型在数学和科学任务中的表现。NTL不仅在不增加运行时开销的情况下有效,而且可以无缝集成到现有的语言模型架构中。实验结果表明,NTL在多任务数学数据集、回归任务、不同模型架构和分词策略下均表现出色,并且在大规模语言模型中也具有很好的扩展性。未来的研究可以进一步探索NTL与其他数值特定训练适应的协同效应,以及在中大型开源模型上的应用潜力。