论文理解【LLM-回归】——【RAFT】Better autoregressive regression with LLMs via regression-aware fine-tuning
-
首发链接:论文理解【LLM-回归】——【RAFT】Better autoregressive regression with LLMs via regression-aware fine-tuning
-
文章链接:Better autoregressive regression with LLMs via regression-aware fine-tuning
-
发表:ICLR 2025 spotlight
-
领域:LLM 浮点回归
-
一句话总结:本文提出了回归感知微调(RAFT)方法,通过对候选数值的概率加权期望优化MSE误差,将回归损失融入标准 Decoder-Only LLM 微调,在保留自回归预训练的优势的同时利用数值目标的特性,显著提升模型的数值回归能力
- 摘要:基于 Decoder 的大语言模型(LLM)展现出极强的通用性,即便在看似与传统语言生成无关的问题上也取得了显著成果。回归问题的任务目标是实数而非文本标记,常见的处理方式包括:(1) 基于交叉熵损失进行微调,并在推理阶段采用自回归采样;(2)通过平方误差等合适损失函数对独立预测头进行微调。尽管这两种方法都取得了一定成效,但关于如何系统性地利用 Decoder LLM 进行回归任务的研究仍较为有限。本研究在统一视角下对比了不同先前工作,并提出基于贝叶斯最优决策规则的回归感知微调(RAFT)新方法。在多个基准测试和模型家族上的验证证明 RAFT 方法在性能上优于现有基线模型
1. 背景
1.1 语言模型的回归能力
-
很多实际应用涉及到语言模型回归,如语义相似度预测、翻译的自动质量评估以及情感分析等。这原本是 BERT 等 Encoder 类模型的专属领域。单随着 Decoder 类模型的发展,有必要开展针对该类语言模型的回归方法探索
-
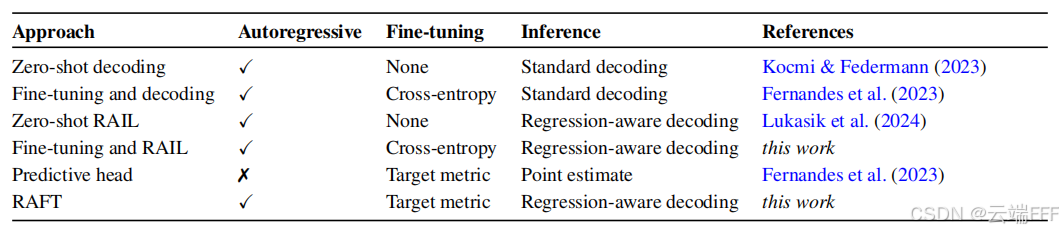
现有工作主要可分为自回归和预测头两类方法
-
作者认为两类方法都存在问题,希望提出一种既尊重LLM预训练的目标,又尊重NLP回归任务目标数值特性的微调方法
- 自回归类方法没有利用回归目标的数值特性,详见 论文理解【LLM-回归】—— 【NTL】Regress, Don‘t Guess--A Regression-like Loss on Number Tokens for Language Model 1.1 节
- 回归头类方法偏离了 Decoder-Only Transformer 的预训练目标
1.2 传统方法及其局限性
1.2.1 符号设定
- 设有词表 ,设 为 token 输入序列集合, 为实数值目标集合,本文只考虑十进制有限维目标值,因此排除无理数。进一步假设每个 存在唯一的字符串表示 。设 表示一个关于 的真实分布,有 。NLP回归任务常通过最小化 MSE 误差学习预测器
得到的贝叶斯最优预测器为
- 考虑使用 LLM 来执行此类回归任务,LLM 本身指定了 中的字符串分布 ,给定输入 ,用 表示可能生成结果的条件分布
1.2.2 传统方法
- 标准回归推理(few-shot prompting):通过自回归解码从分布 中通过贪婪或温度采样等方式生成自回归生成 ,进而得到
其中 表示将给定字符串转换为相应数值,对于 ,有 。这类算法本质上寻求近似众数
- RAIL(few-shot prompting):2024年方法 RAIL” 指出自回归模型训练时目标为最小化 0-1 解码损失 ,与回归中感兴趣的平方损失不完全一致,因此其基于 mse 损失 得到贝叶斯优化器
实践中,上式期望无法精确计算,可通过两种方式近似
- 抽样有限数量的 值取平均
- 对目标进行评分,这时假设目标值在有限网格 上,RAIL 预测器在网格上取加权平均数
对于中等大小的离散目标 ,可以设置 ;对于有界 ,可以通过等距分bin离散化得到 ,不要求
- 标准微调方法:直接对 LLM 进行感兴趣任务的微调可以有效提升回归性能。微调旨在最小化
一个合理的损失满足 ,其中 表示集合 上分布的集合。 的一种标准选择是交叉熵 CE 损失,即
其中 表示对目标数值 的 token 序列表示。更一般地,在离散化到某个有限网格 后,可以使用目标值的 NLP 描述(如 “优良中差” 等)表示 。经过微调的模型在推理时可使用上述 1 或 2 方法
- 引入回归头并微调:作为标准微调的一种替代方案,使用 LLM 前向传播得到的激活或嵌入来构造预测器。这里首先提取输入特征 ,然后将其输入回归头 (通常是一个可学习的线性层),然后可以在微调过程中直接最小化 mse 损失。需要注意的是,这种方法在推理时不执行自回归解码。先前的工作已经探索了一些 的选择。最常见的是对输出 token 嵌入、输出 logits 或输出概率进行池化或选择。例如,可以选取最终位置输出 logit 激活值,或对所有输出 token 嵌入做均值池化
1.2.3 传统方法的问题
- 考虑微调 Pre-trained LLM 用于回归任务,一个直接的 baseline 是先用上式(6) 进行微调,由于对数损失是严格适定的(strictly proper),这在总体极限下可以恢复 Bayes 分布 。在此基础上,可以应用标准自回归(式2) 或 RAIL 方法(式4)进行推理
对数损失就是严格适定的,这本质是因为最小化交叉熵等价于最小化 KL 散度,而 KL 散度有唯一最小值,因此令对数损失最小化时,最优预测分布就是唯一的真实分布。这意味着当数据无限、模型足够强大时,最小化交叉熵的结果会让最优模型预测分布 唯一地收敛到真实的条件分布
- 然而,作者在此提出了两个引理,证明了即使模型分布和真实条件分布完全一致,标准解码或 RAIL 预测器仍然可能相较于 Bayes 最优预测器产生高平方误差
-
标准解码:由于一个分布的众数可能与其均值相距甚远,即便模型拟合分布 和真实分布 的距离非常小, 的均值和 的众数仍有可能相距甚远
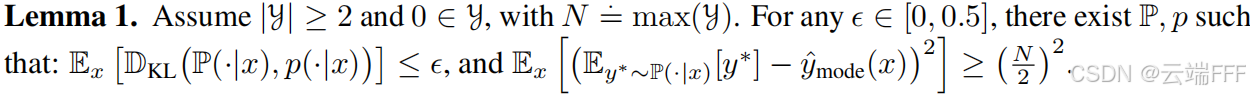
-
RAIL解码:即便模型拟合分布**和真实分布 的距离可能非常小,但由于 CE 损失只关心 token 分类概率,不具备数值敏感性(无法识别“数值大小”),微小的误差可能被式(4)中的候选标签 放大**
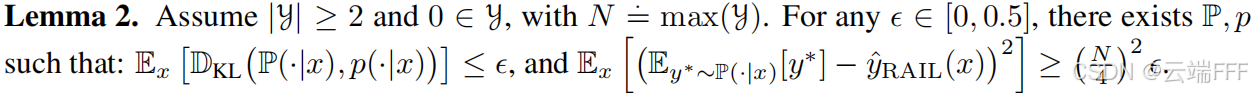
-
2. 本文方法
2.1 回归感知的 LLM 微调
- 为了 1.2.3 节的问题,作者提出一种新的回归感知目标,直接在 RAIL 预测器上最小化平方损失。定义回归感知微调(Regression-Aware Fine-Tuning, RAFT)损失如下:
这可以理解为使用 从 LLM 构造一个数值,并测量该数值与目标 之间的平方损失。实践中,给定一个有限网格 和微调数据集 ,经验损失为:
需要注意的是,计算此损失只需在模型下对每个打分即可,训练过程中不需要执行采样或解码。这种微调方式等价于直接最小化
和标准微调对比如下
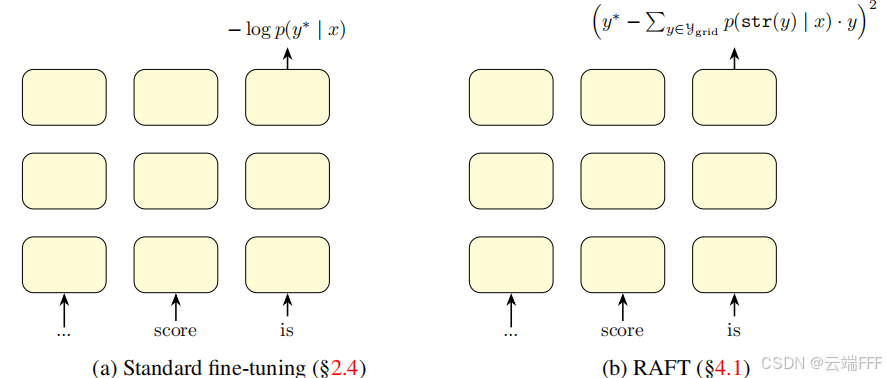
-
尽管 是在有限离散化的目标空间 上计算的,但在温和条件下,其能够模拟在整个整个数值空间上最小化式 (7) 得到的 Bayes 最优预测器
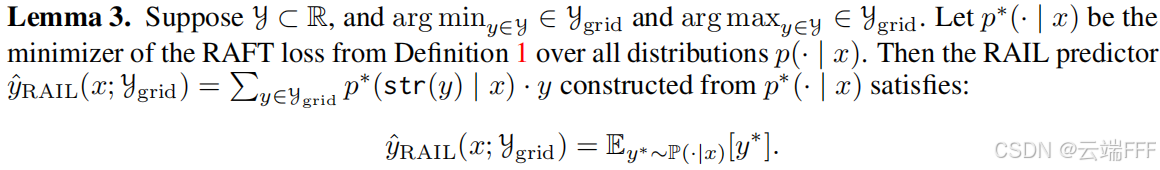
直觉上,任何数值目标都可由 中最小数与最大数的凸组合来表达,因此只要令它们在目标空间 内,即可通过优化 RAIL 预测器进行估计。具体地,给定任意 ,优化目标可以写作(省略字符串/浮点数转换)
- 先只考虑等式约束,假设不等式约束不存在,得到最优解必要条件。利用拉格朗日乘子法,构造
对每个 求偏导并令其等于 0,有
任取 ,相减得到
注意对于给定的 , 和 无关,将其提到 外部,得到
- 进一步考虑可行性问题,这意味着需要存在一个合法概率分布 满足上式。由于 且 ,我们可以如下构造最优模型分布
2.2 与最小贝叶斯风险方法对比
-
RAFT 损失的一种朴素变体是通过采样模型预测来优化回归度量,从而最小化贝叶斯风险(Minimum Bayes Risk, MBR,该损失定义为
注意其与标准 RAFT 损失相比只是把期望符号 提到 MSE 的外边。实践中依然通过引入网格数值空间 进行损失计算,以避免进行模型推理
-
这种方式的一个重要问题在于,最小化会得到一个 one-hot 分布,其所有概率质量都集中在 中的一个目标值上

这使得模型质量完全取决于对原始目标空间 的近似程度。例如,若 仅由整数构成,即使原始目标空间 包含任意精度的浮点数,模型也只能预测整数,而标准 RAFT 不会因使用近似目标空间而损失精度
2.3 与回归头方法对比
-
RAFT 不仅与自回归 RAIL 解码有密切关系,而且在单数字网格的情况下(网格中每个元素对应于词汇表 中的一个 token),RAFT 的预测函数与预测头方法具有相似性。注意:若 对应于一个独立 token,则有
这里下标 是用矩阵表示法取输出 token 张量 中的值,表示在在输入 的最后一个位置,预测下一个 token 是 的概率。这时 RAIL 预测器变为:
-
现在可以将 RAFT 与下表所示以往工作中的各种预测器进行对比

-
将 RAFT 与上表中 “final-token logit 激活法” 进行比较是有启发性的。两者都具有如下形式:
其中 是某种激活函数, 是权重向量,观察到以下差异:
激活函数 权重向量 初始化 single-digit RAFT softmax 与 RAIL 解码一致 final-token logit 恒等映射 one-hot 引入随机回归头 注意到 RAFT 预测器在初始化时与 RAIL 解码完全一致,因此 zero-shot 性能好。相比之下,大多数预测头方法在初始化时会产生较大误差,因为它们偏离了 next token prediction 任务。因此,RAFT 可以看作是一种在初始化时就具有强性能的预测头方法,从而使优化更容易;在实验中也观察到 RAFT 的收敛速度比基线更快
-
鉴于以上相似性,有必要仔细分析这些差异,并确定它们在 RAFT 性能中是否起到了重要作用。因此引入以下新的预测头变体:
- MLP on final-token logits:针对激活函数 差异,在 final-token logit 向量上应用一个两层的 sigmoid 激活 MLP,而不是只选择单个特殊 token 的 logit:
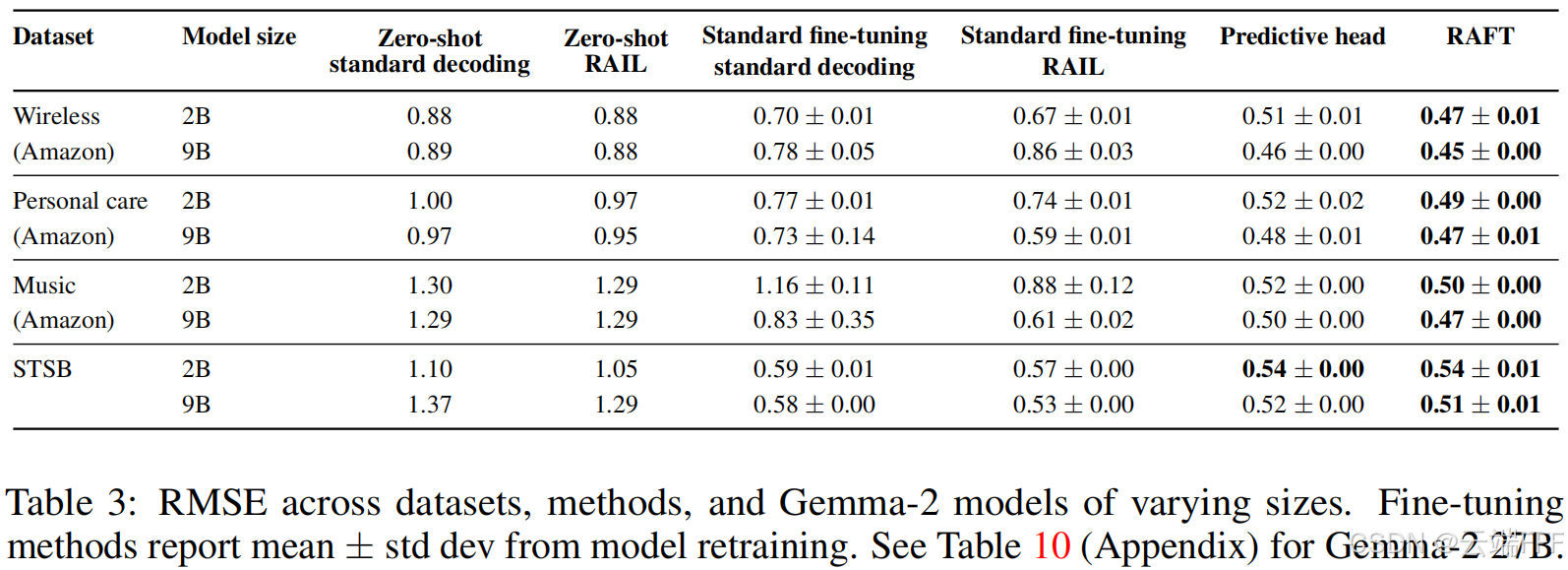
- Learnable-RAFT:针对权重向量 差异,在 RAFT 基础上引入可学习的的输出权重,而不是固定为向量 :
这添加了更多灵活性,但偏离了 next token prediction 的预训练任务
- MLP on final-token logits:针对激活函数 差异,在 final-token logit 向量上应用一个两层的 sigmoid 激活 MLP,而不是只选择单个特殊 token 的 logit:
-
为了分析预测器的灵活性和与预训练任务的一致性哪个更重要,作者将 Learnable-RAFT 与 RAFT 进行比较,并且测试了从随机初始化(而非预训练模型)开始微调的情况
3. 实验
- 数据集与指标:US Amazon Reviews(Wireless、Music、Personal Care 三类,目标是预测平均星数)、STSB(人工标注的句子对相似度评分)、MovieLens-1M(电影评分回归);主要指标为 RMSE。
- 模型:Gemma-2 与 PaLM-2,重复微调 3 次报告方差
- 方法:
- 自回归基线:零样本标准解码、零样本 RAIL、标准微调+标准解码、标准微调+RAIL;
- 预测头方法:传统预测头方法与本文新增变体;
- RAFT 及 learnable-RAFT 变体
- 实现要点:默认使用数字网格**,注意此设置下RAFT 仍能预测连续浮点数**
3.1 结果
-
在 Amazon 三个子集与 STSB 上,RAFT 最优,预测头优于纯自回归基线;采用 RAIL 推断和进行微调均有帮助,效果呈阶梯式提升
- 从“零样本标准解码 → 零样本 RAIL → 标准微调+标准解码 → 标准微调+RAIL”,性能逐步提升;
- 预测头 > 自回归基线,印证了标准 CE 微调与 MSE 误差不匹配的局限;
- RAFT > 预测头,支持“微调目标需与回归损失对齐且不偏离自回归设定”的命题。
-
在 Amazon Wireless 上,RAFT 优于多种预测头变体(如 special-token、2 层 MLP、序列池化);learnable-RAFT 相比 RAFT 无优势
-
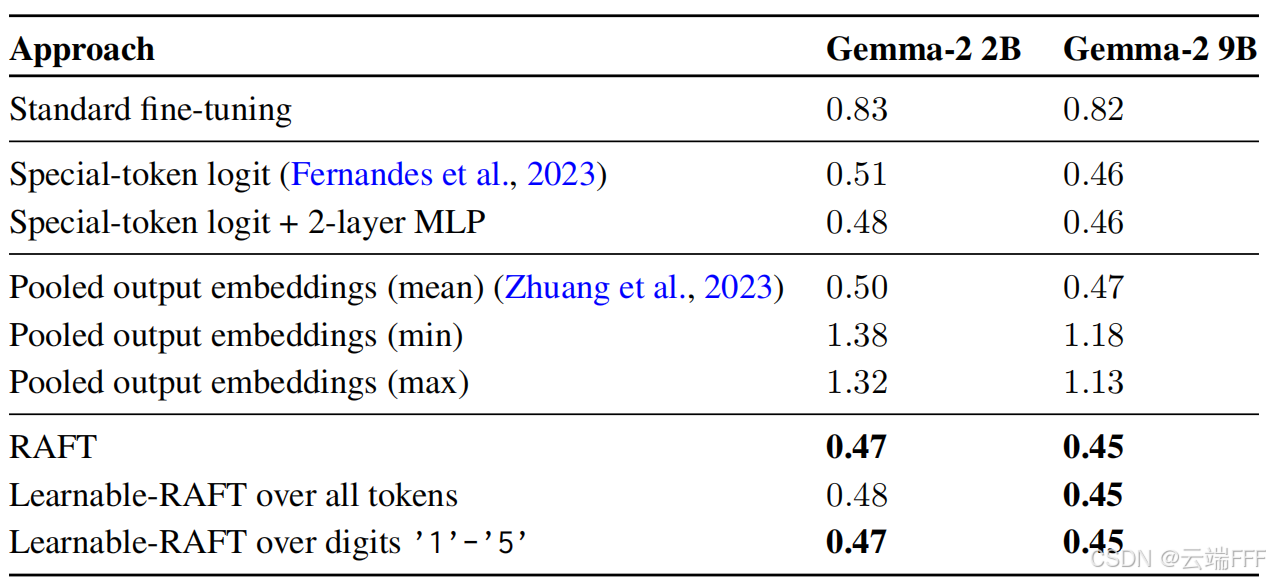
RAFT 仅在预训练情况下由于回归头:
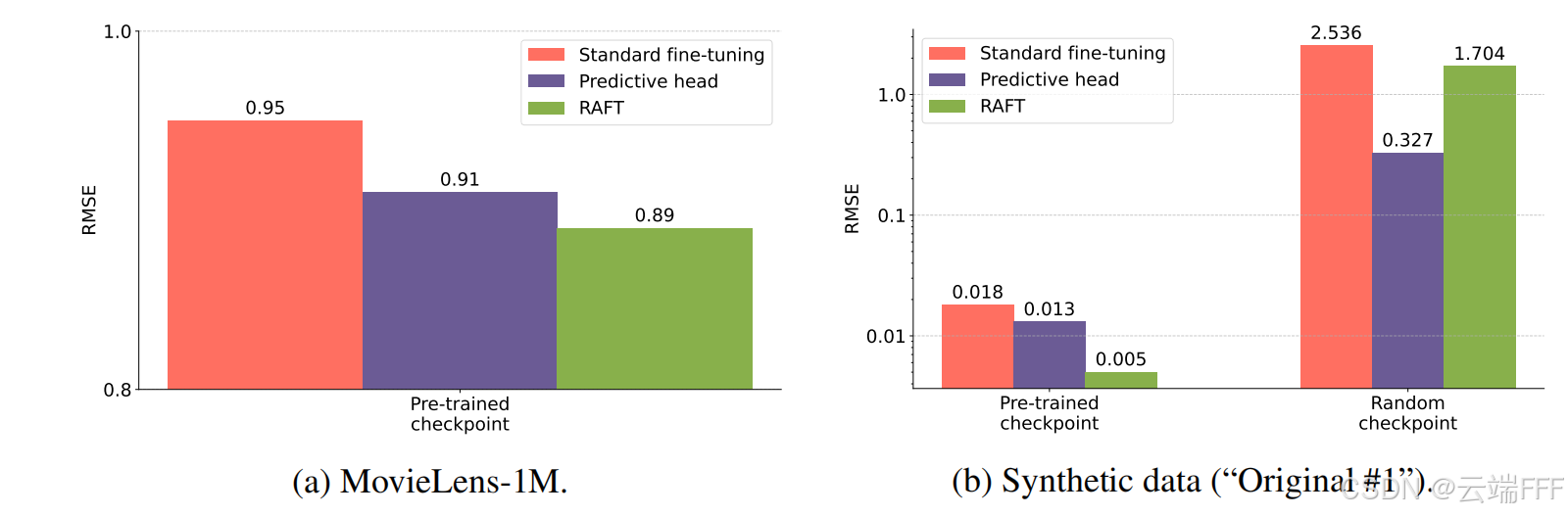
- MovieLens-1M:RAFT 明显优于标准微调与预测头。
- 合成数据(Original #1):从预训练检查点出发时 RAFT > 基线;随机初始化时 RAFT 反而不占优,凸显与预训练任务对齐的重要性。
3.2 结论与扩展发现
- 核心结论:跨数据集与模型,RAFT 一致优于自回归基线与预测头方法;收益来自于微调目标与回归损失对齐且保持自回归/下一词预测的一致性。
- 收敛性:RAFT 起点即与 RAIL 一致,初始 RMSE 更低、收敛更快
- 分布形态:RAFT 训练后,数字 token 概率的熵上升(不收紧不确定性),与 MBR 微调形成对照
- 稳健性:附录给出 STSB-1K 子集、Gemma-2 27B 与 PaLM-2 的结果,整体趋势一致
4. 总结
- 用 LLM 做回归存在割裂性,引入回归头理论上能做到贝叶斯最优,但这种微调的目标和预训练不同,模型要“重新学”怎么把隐藏表示映射到数值空间,等于浪费了预训练阶段对 token 分布的建模。如何在标准自回归序列生成的基础上实现高质量回归长期以来是一个重要问题
- 本文亮点在于理论上统一了传统自回归解码和额外回归头两类方法,证明在温和条件下自回归解码也可实现最优 MSE 收敛,方法上无需额外参数或模块,仅通过改写损失就能直接利用已有自回归模型的预训练能力。实验结果表明 RAFT 在多项回归任务中显著优于现有方法,同时还能提供更合理的不确定性分布,简单、高效且与当下大规模 LLM 生态高度兼容,这些有点使本文获得了审稿人高度评价,并中选 spotlight
- 强行说的话,可能存在以下问题
- 相比回归头性能提升有限,理论上 RAFT 和回归头方法都能收敛到最优,因此虽然 RAFT 有较好的 zero-shot 能力,经过充分训练的回归头应该能取得一样好的结果,这可能在应用角度削弱了本文的意义
- RAFT 严重依赖于预训练,从头训练时表现不如回归头方法,这也涉及到 的选取,若其中的网格值不存在于预训练词表,则性能难以保证
- 微调可能损害模型的自然语言生成能力,尽管这脱离了问题的问题设定,但可能是有意义的问题。一种朴素的方法是使用 LoRA/adapter 等方式进行微调,并仅在下游用任务加载 adapter