论文理解【CV-对比学习】——【SimCLR】A Simple Framework for Contrastive Learning of Visual Representations
- 首发链接:论文理解【CV-对比学习】——【SimCLR】A Simple Framework for Contrastive Learning of Visual Representations
- 文章链接:A Simple Framework for Contrastive Learning of Visual Representations
- 代码:google-research/simclr
- 发表:ICML 2020
- 领域:CV-对比学习
- 一句话总结:SimCLR 通过强数据增强、非线性投影头和大规模训练,构建了一个简单但高效的对比学习框架,在自监督与半监督视觉表征学习上大幅提升了性能
- 摘要:本文提出 SimCLR:一个用于对比学习视觉表征的简洁框架。我们简化了近期提出的自监督对比学习方法,无需专门的网络结构或记忆库。为了理解对比预测任务为何能学习到有用的表征,我们系统性地研究了框架中的关键组成部分。实验表明:(1) 数据增强的组合在定义有效预测任务时起关键作用;(2) 在表征与对比损失之间引入可学习的非线性变换显著提升了表征质量;(3) 相比监督学习,对比学习更依赖于更大的 batch size 和更长的训练过程。通过结合这些发现,我们显著超越了此前的自监督和半监督学习方法,在 ImageNet 上取得了新的最优结果。基于 SimCLR 表征的线性分类器在 ImageNet 上达到了 76.5% top-1 准确率,比此前的最佳方法提升了 7%,并且与监督训练的 ResNet-50 相当。在仅使用 1% 标签的情况下,微调后的模型实现了 85.8% top-5 准确率,比 AlexNet 少用 100 倍的标签却超越了其性能
1. 背景
1.1 视觉表征学习
- 本文考虑的问题是以自监督形式学习通用的视觉表征,即在无需人工标签的情况下训练可用于各类下游任务的 CV backbone。本文之前的主要有三种技术路线
- 生成式方法:目标是生成或建模输入像素空间,代表方法有 VAE、GAN 等。这类方法的缺点是计算开销大,而且未必对表征学习必要
- 判别式方法:通过设计 “监督学习预训练任务” 来学习表征,输入和标签都来自无监督数据。常见代表任务有图像上下文预测、Jigsaw拼图、图像上色、旋转预测等。这类方法依赖启发式任务设计,可能限制学习到表示的通用性
- 自监督学习:
- 基于对比学习的自监督学习:通过拉近正样本对、推远负样本对来学习潜在空间中的表征。一般认为此类方法学到的视觉表征更倾向于语义级别(物体之间关系、整体布局、类别等抽象特征)。代表方法有 Instance Discrimination, CPC, MoCo 等,以及本文提出的 SimCLR
本文之前的对比学习方法比较复杂,CPC依赖预测网络处理时序数据,MoCo依赖队列式内存库存储负样本
- 基于重建的自监督学习:让模型通过还原部分缺失的信息来学习有效的特征表示,一般认为此类方法学到的视觉表征更倾向于细节级别(边缘/纹理/局部形状等底层特征),代表方法有 Autoencoder、BEiT、MAE 等
- 基于对比学习的自监督学习:通过拉近正样本对、推远负样本对来学习潜在空间中的表征。一般认为此类方法学到的视觉表征更倾向于语义级别(物体之间关系、整体布局、类别等抽象特征)。代表方法有 Instance Discrimination, CPC, MoCo 等,以及本文提出的 SimCLR
1.2 对比学习
-
对比学习的核心思想是:通过构造正负样本对,让模型学到一个判别性的表示空间,在这个表示空间中 相似的样本尽量靠近,不同的样本尽量分开,这是当前自监督学习的主流方法
所谓判别性,是指同类样本聚在一起,不同类样本分得开,空间中的样本分布能有效地区分不同类别或语义
-
作为一种无监督(自监督)方法,对比学习的目标是学习样本特征的表示方法,即得到一个样本编码器。在此基础上增加分类/回归头并微调即可适用于各种下游任务,这样一种半监督(Semi-supervised)/ 自监督(Self-supervised)结合监督微调的典型流程如下图所示
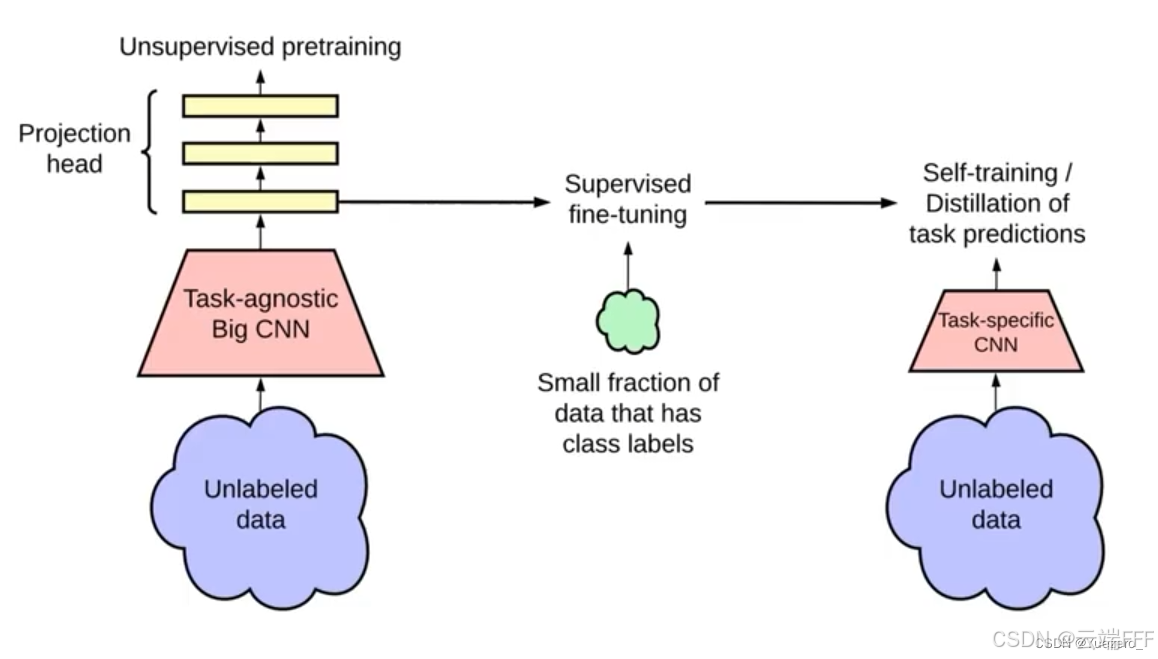
- 无监督预训练:使用 SimCLR 等方法,利用大量无标签数据训练 Encoder,其一般由任务无关的大规模 CNN 和映射到表示空间的投影头 MLP 组成
- 监督微调:经过预训练后,使用针对下游任务的少量有标签数据进行监督学习,将原本 “通用” 的特征调整为对特定任务有用的特征
若监督数据量大,微调后即可以直接用于下游任务,或在第3步蒸馏到小模型 若监督数据极少,这一步后很可能过拟合到微调数据,需在第3步进行自监督训练
- 自监督/蒸馏:用微调后的模型为大量未标注数据构造伪标签,从而扩展第2步的小数据集。然后可以继续微调模型(常见于 FixMatch 等半监督方法),或重新训练一个新模型(常见于模型蒸馏或 Noisy Student 等 “教师-学生” 框架)。现代方法通常倾向于 “教师-学生” 框架,因为它可以反复迭代,逐步提升性能
扩展数据集的标签来自第2步的微调模型,伪标签并不提供新知识,为何自监督训练还能提升性能呢。原因包括
- 无标签数据覆盖了更大的目标分布空间,迫使模型在更大的空间进行拟合,缓解了对真实标记数据集的过拟合问题。这类似于数据增强思想:标签不完美但覆盖广,能正则化模型
- 高置信度伪标签相对可靠,模型对部分样本的预测可能非常自信,如果只挑选置信度高的伪标签来训练(confidence filtering),那扩展数据集的质量其实不错。通常这些样本落在真实标记数据集样本的内插空间中,可以让模型对这部分的拟合更精细
- 即使部分伪标签是错的,但只要噪声不系统性偏向某类,其可以看作一种正则化手段,深度模型通常能从大规模数据中“滤掉”一部分噪声。引入噪声标签后,模型训练时会受到 “矛盾的监督信号”,这迫使其不能死记硬背标签,而要在更大数据分布里找到决策边界,比如 NLP 中的标签平滑就是这个思路
- Student 可以比 Teacher 更强,Noisy Student 框架里,Student 用到了更大模型、更多数据增强、Dropout 等正则,使其性能比 Teacher 更强
2. 本文方法
- 本文的研究重点在于:
- 如何在不依赖专门架构或记忆库的情况下简化对比学习算法;
- 如何通过数据增强和损失函数的设计来提高表示质量;
- 如何在训练过程中利用更大的批量大小和更长的训练时间
2.1 对比学习框架
-
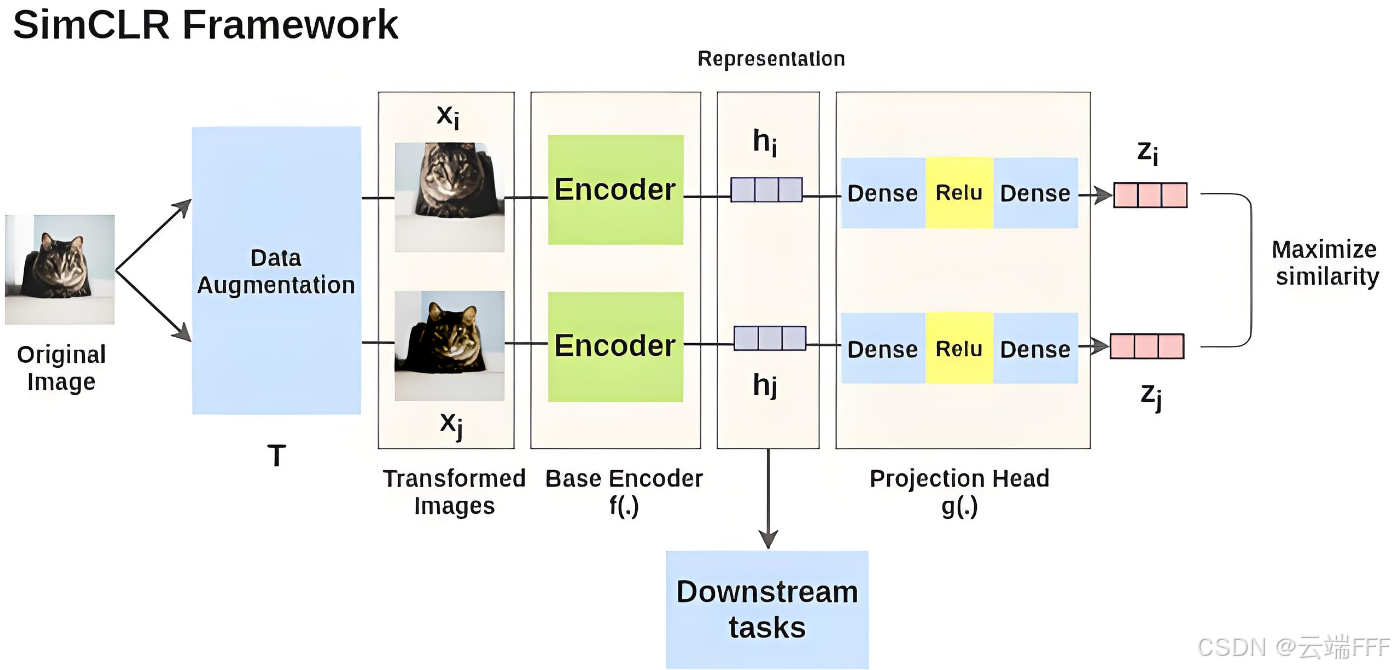
下图展示了 SimCLR 的训练方法

- 从无标签数据集随机抽取样本,使用简单的图像增强(随机裁剪、随机颜色失真和高斯模糊)组合对每个样本进行两次变换
实验表明,数据增强的方式很重要,作者在此连续应用三种简单的增强方法:随机裁剪然后将大小调整回原始大小,随机颜色失真,以及随机高斯模糊
- 用一个 CNN 骨干网络 提取增强样本特征 ,再用 MLP 投影头 将特征投影到表示空间得到
本文使用 ResNet-50 作为特征提取网络 ,用带一个隐藏层的 Relu 激活 MLP 作为投影头 。实验表明,引入非线性变换 非常重要,其有效过滤了数据增强本身引入的特征,只保留下游任务所需的语义特征信息
- 抽取 mini-batch 进行训练,设其中有 个原始样本,增强后得到 个增强样本。我们认为经过简单变换的图像没有语义差异,应具有一致的表征,故令来自相同原始样本的增强图像构成正样本对,令来自不同原始图像的增强图像构造负样本对。因此对于任意增强样本 ,设其和增强样本 构造成正样本对,同时和其他 个增强样本构造成负样本对。优化如下 NT-Xent 损失
其中 是指示函数,当且仅当 时为1, 是温度稀疏, 是余弦相似度,即两个向量 规范化后的点积
优化 可以理解为分母尽量小(负样本对更远)且分子尽量大(正样本对更近)。NT-Xent 损失本质上是更有名的 InfoNCE loss 的一个实例
- 从无标签数据集随机抽取样本,使用简单的图像增强(随机裁剪、随机颜色失真和高斯模糊)组合对每个样本进行两次变换
-
SimCLR 完整训练框架如下所示。最终只保留能够提取图像特征的编码器网络用于下游任务
-
SimCLR 伪代码如下

2.2 训练细节
-
增大 Batch Size:对比学习依赖大量负样本提供丰富的训练信号,如果每个样本只有少数负例,模型可能学不到好的判别边界。Memory bank 是早期对比学习方法常用的一个 trick,其将历史样本的特征表示缓存在一个全局字典中,并在计算当前批次损失时将这些缓存特征作为额外的负样本参与对比。这种方式使得模型即便在小 batch 条件下,也能拥有大量负样本,缓解了显存和计算资源不足带来的限制。然而,由于 memory bank 中的特征来自于旧的模型参数,可能会出现表示不一致或过时的问题,因此后续方法(如 MoCo)又提出了动量编码器与队列机制,以保持负样本表征的更新稳定性。SimCLR 追求精简,没有使用 memory bank,仅靠同一个 batch 内的样本来构建对比关系,因此需要很大的 Batch size(文中设为 8192),为了稳定训练,使用了 LARS 优化器
LARS主要针对大规模数据和模型,可能会遇到参数更新太大导致模型不稳定的问题。LARS通过逐层调整学习率来解决这个问题
-
全局 Batch Norm:在分布式训练时,每张 GPU 上只处理一个 mini-batch 的子集,标准 BN 只在 单卡的局部 batch 上计算均值和方差,归一化尺度不同不同导致不同 GPU 上样本的 embedding 空间不同,对比关系失真,影响训练。全局 BN 通过跨 GPU 通信收集整个全局 batch 的均值和方差,保证 BN 使用全局一致的统计量,稳定相似度计算
-
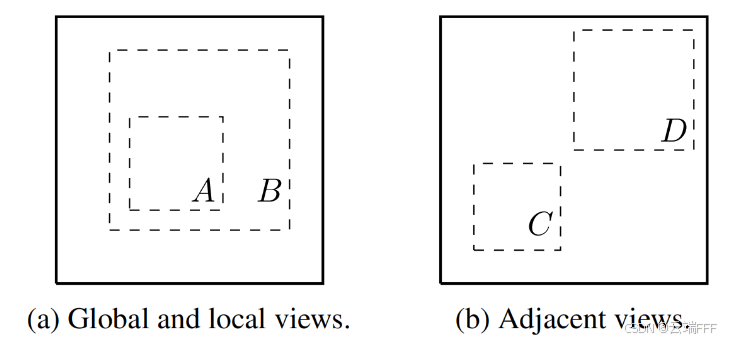
数据增强组合:本文系统地研究了数据增强的影响,考虑了多种常见增强策略。所有数据增强都基于 “随机裁剪” 增强,这是最关键的增强手段,且能消除 ImageNet 数据集的图像尺寸不统一问题。随机裁剪会自然地构造出两种优化任务。如下图所示,高重叠正样本对(a)可以给模型提供稳定的低层视觉对齐信号;低重叠正样本对(b)迫使模型学习更强的语义一致性
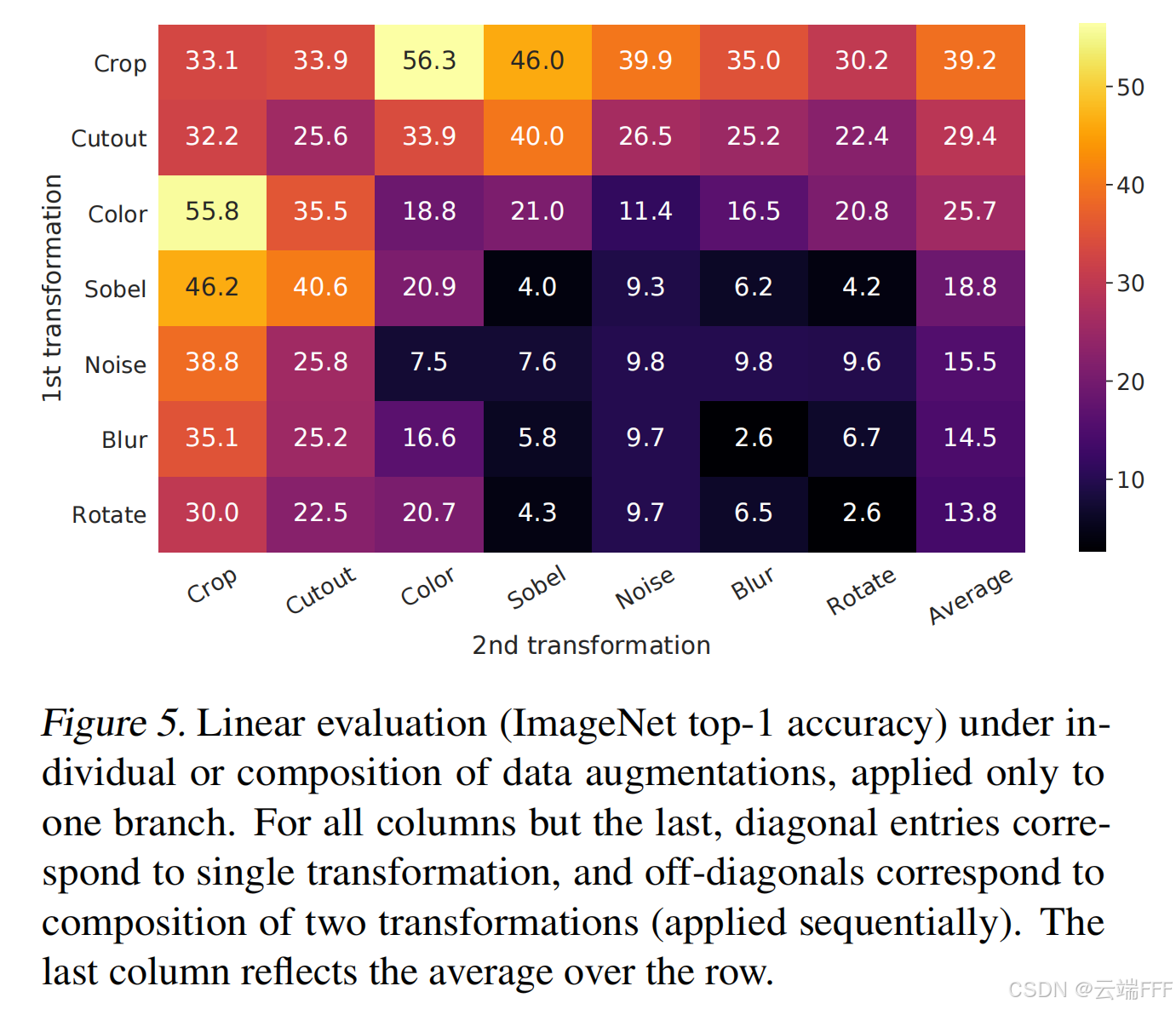
在此基础上,作者系统研究了随机裁剪和其他数据增强方法的组合情况

结论如下,随机裁剪和随机颜色失真的组合表现最好,作者认为这是因为仅使用随机裁剪时,模型可以通过颜色相似度很简单地判别正负样本,而随机颜色失真使模型无法作弊
3. 实验
3.1 表示质量
-
作者使用对比学习领域广泛使用的 linear evaluation protocol 评估 SimCLR 学到的表示质量。其做法是:自监督预训练完成后,冻结 backbone(encoder)参数,在它的输出表示上面训练一个线性分类器(通常是一个单层全连接层,softmax 输出),来评估表示的质量(文中使用 top-1 / top-5 分类准确率)
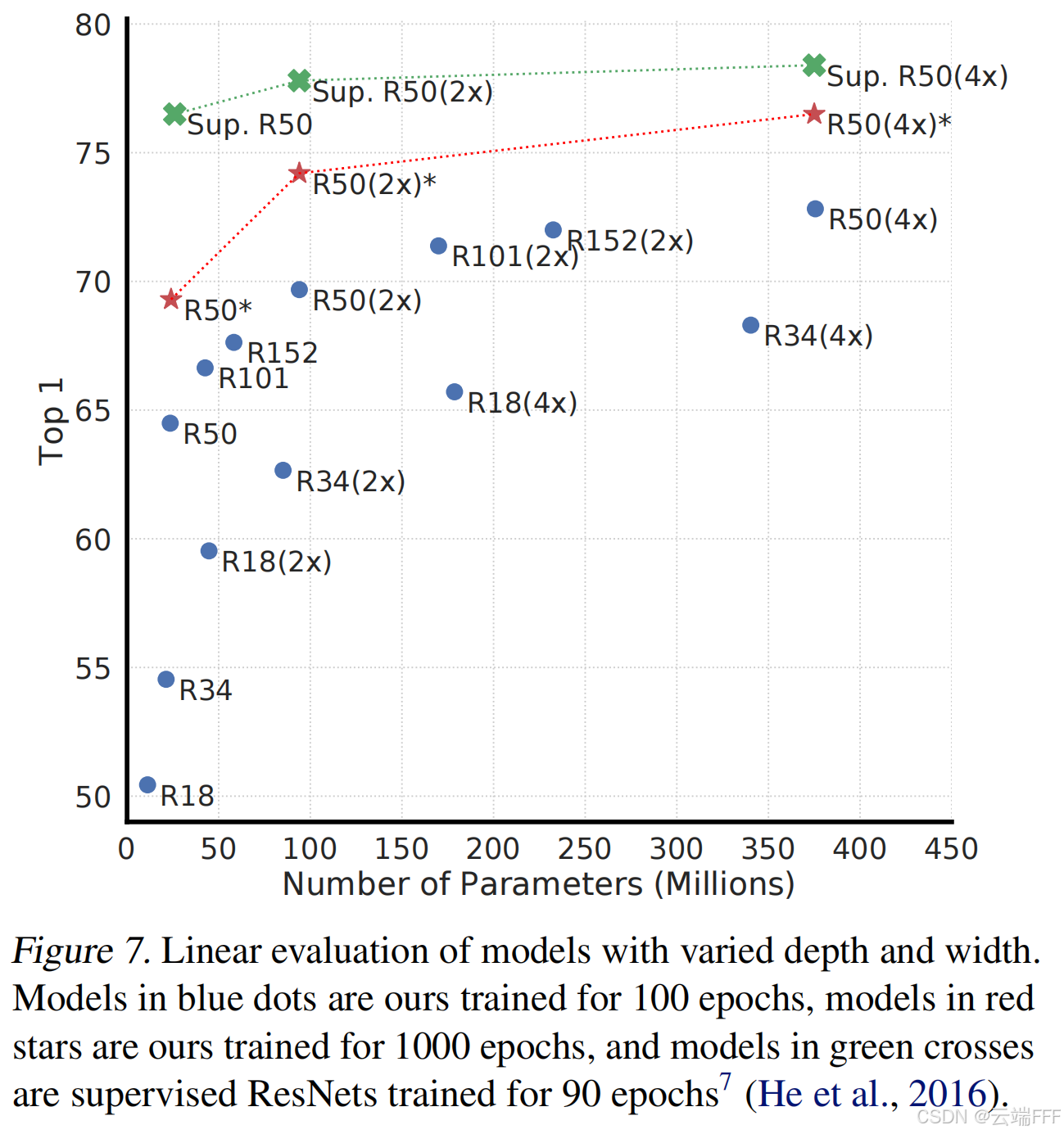
这里SimCLR预训练和微调、ResNet监督学习使用的都是全量数据。注意到虽然监督学习在相同模型规模下表现更好,但 SimCLR 的性能随模型规模增加而提升更快,表明自监督对比学习学到的表示在大模型条件下更具潜力
-
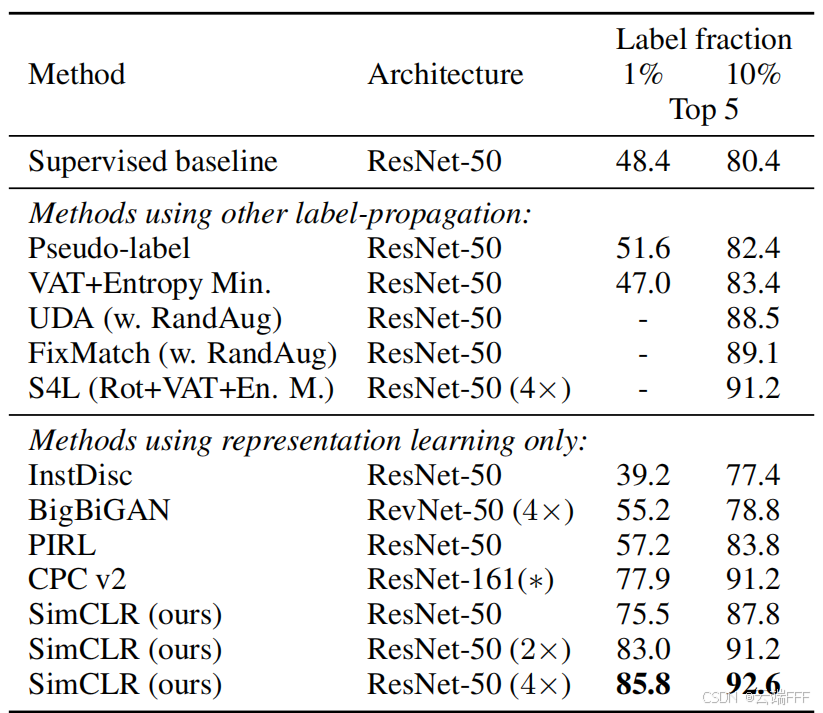
SimCLR 在半监督学习场景下表现良好。结果表明,即使只使用 1% 或 10% 的 ImageNet 标签对预训练模型进行微调,SimCLR 也能显著超过监督学习的基线模型,说明 SimCLR 学到的表示在少标签环境下尤为有效,大幅降低了对大规模标注数据的依赖
3.2 消融实验
-
非线性投影头提高了表示质量:作者对比了(1)恒等映射;(2)线性投影;(3)具有一个额外隐藏层的默认非线性投影(ReLU激活)三种投影头,发现非线性成分能够提升性能
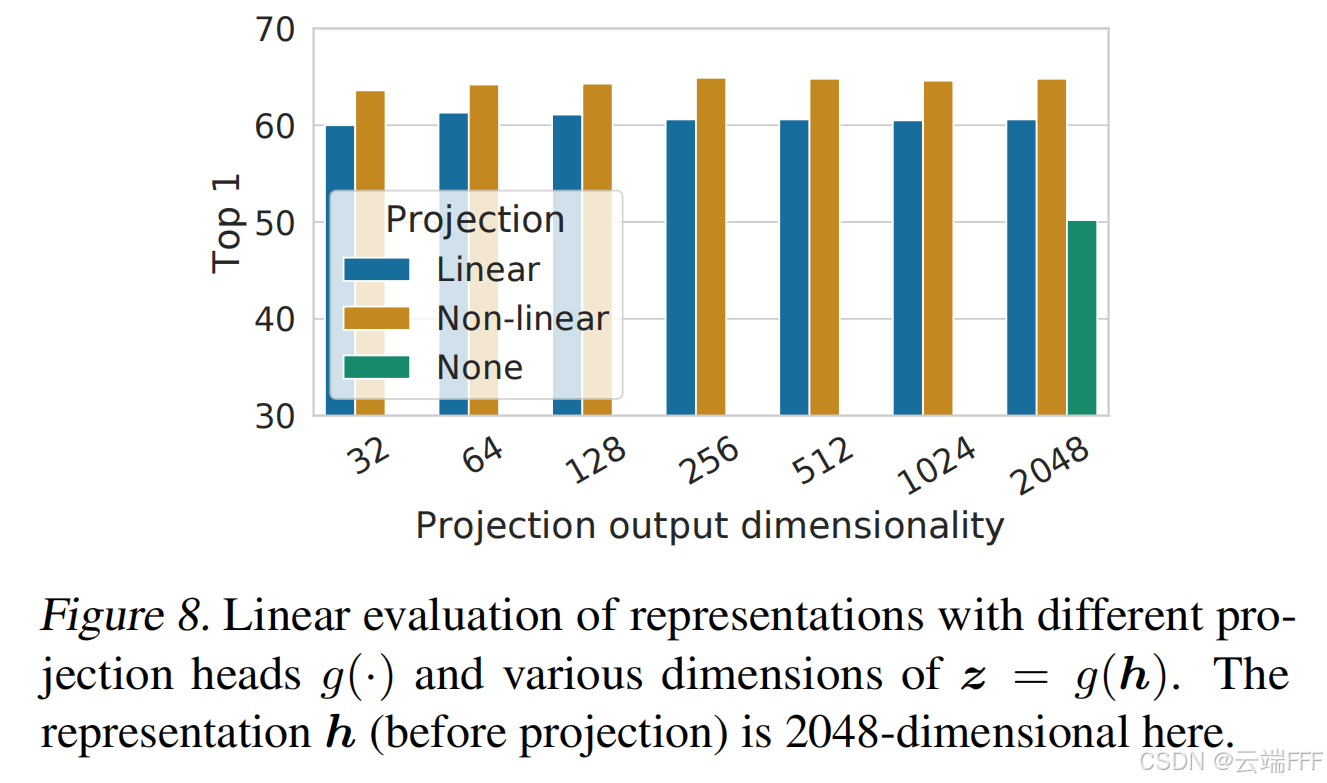
作者认为这是因为非线性 MLP 能有效消除数据增强本身引入的特征
作者构造实验,分别用预训练后 backbone 输出 和 backbone + projection head 输出 训练额外的 MLP 分类器,预测输入样本经历了哪种数据增强变换。后者预测精度显著下降,接近随机
-
NT-Xent 损失最优:作者探讨了损失函数的选择

-
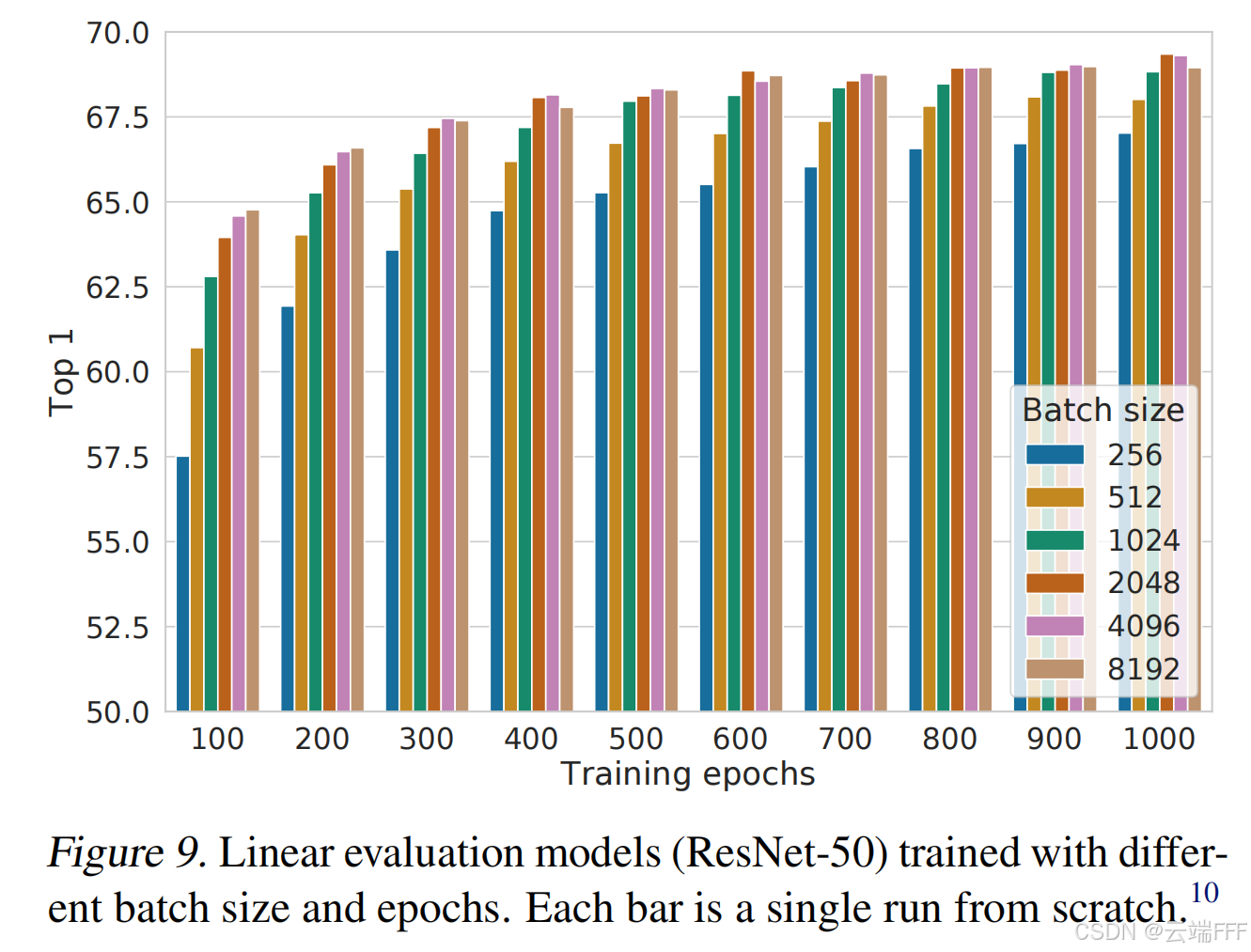
对比学习需要更大 Batch Size 和更长训练时间:下图展示了模型训练不同数量的 epoch 后,Batch Size 的影响,注意到大 Batch Size 优势明显。与监督学习不同,对比学习中更大的 Batch Size 和更长的训练时间提供了更多的负例,有助于提升收敛速度和性能
3.2 下游任务性能
-
在 ImageNet 上的 linear evaluation(固定 encoder,只训练线性分类器)评估,SimCLR 超越了当时的其他 SOTA 自监督方法(MoCo、PIRL、CPC v2、AMDIM 等)
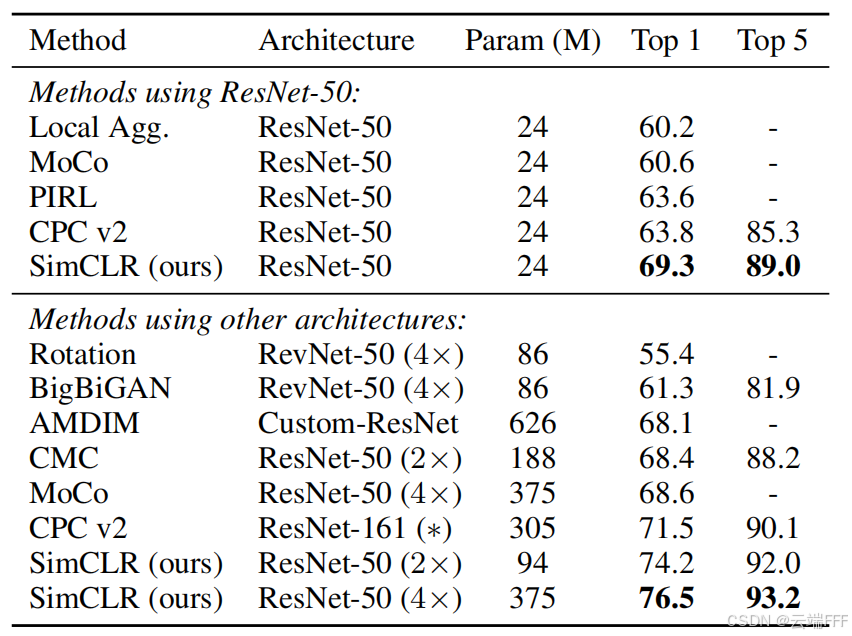
-
在 12 个下游分类数据集(如 CIFAR-10、VOC2007、Flowers、Caltech-101 等)上做迁移学习对比,比较 SimCLR 和全监督预训练的模型
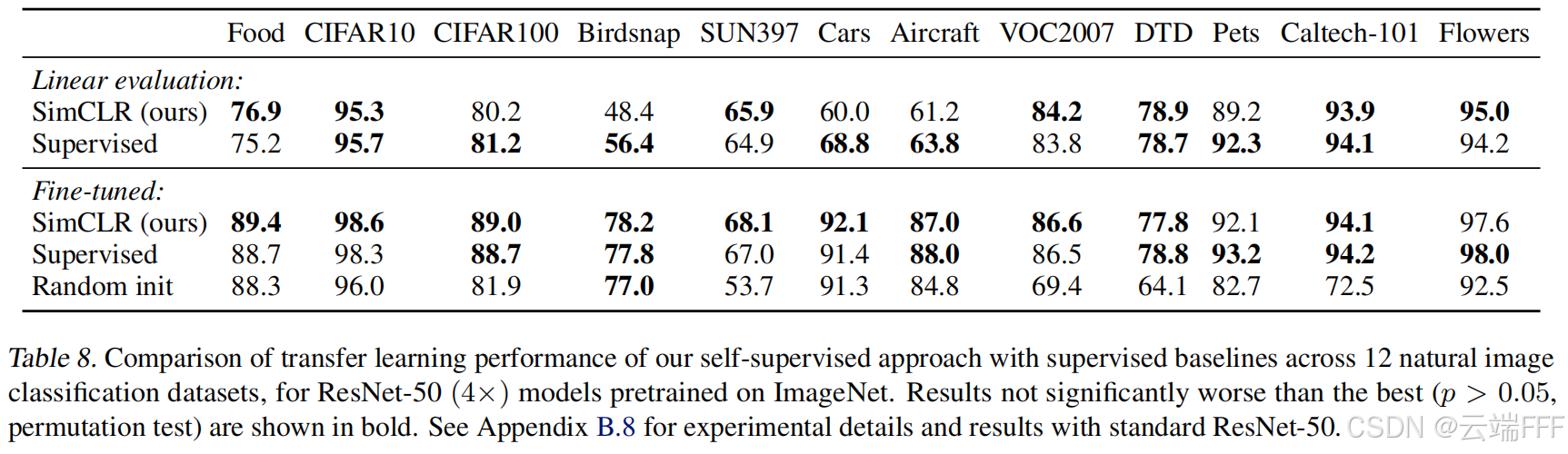
注意到 SimCLR 学到的表示具有良好的迁移性和泛化性,在下游任务中不输甚至超过监督学习:
- linear evaluation(frozen encoder)设定下,SimCLR 在多个数据集上和监督学习接近甚至更优
- full fine-tuning 设定下,SimCLR 在 5 个数据集上优于监督预训练,5 个数据集相当,仅在 Pets 和 Flowers 上稍弱
4. 总结
- SimCLR 提出了一个简洁而高效的自监督对比学习框架,在无需额外结构(如记忆库或专门的架构设计)的情况下,通过 大规模数据增强、非线性投影头以及大批量训练,显著提升了表示学习的效果。其创新点在于:
- 强调了数据增强组合(随机裁剪+颜色扰动+模糊)在构造对比任务中的关键作用;
- 证明了简单的架构配合适当的训练策略即可在 ImageNet 上超越既有自监督方法,达到与监督学习接近的性能
- SimCLR 展示了对比学习在 少标签场景 和 下游迁移任务 中的巨大潜力,大幅降低了对大规模人工标注的依赖。它不仅推动了自监督学习方法走向主流,也为后续如 BYOL、DINO、CLIP 等一系列工作奠定了基础。