论文理解【CV-对比学习】——【BYOL】Bootstrap Your Own Latent-A New Approach to Self-Supervised Learning
- 首发链接:论文理解【CV-对比学习】——【BYOL】Bootstrap Your Own Latent-A New Approach to Self-Supervised Learning
- 文章链接:Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning
- 代码:google-deepmind/deepmind-research
- 发表:NIPS 2020
- 领域:CV-对比学习
- 一句话总结:BYOL通过两个神经网络的互相学习,提出了一种无需负样本的新型自监督图像表示学习方法,且在多个基准测试中超越了当前的最先进技术
- 摘要:我们提出了 “Bootstrap Your Own Latent”(BYOL),这是一种用于自监督图像表示学习的新方法。BYOL依赖于两个神经网络,分别称为在线网络 online network 和目标网络 target network ,它们通过相互作用进行学习。训练过程首先对同一图像生成两张增强视图,然后 online 网络被训练来预测 target 网络对同一图像增强视图的表示,target 网络通过 online 网络的缓慢移动平均进行更新。与依赖于负样本的现有方法不同,BYOL在没有负样本的情况下实现了 SOTA 性能。BYOL 在 ImageNet 上使用 ResNet-50 架构的线性评估时达到了 74.3% 的 Top-1 分类准确率,使用更大的ResNet架构时达到了 79.6%。我们还展示了 BYOL 在迁移学习和半监督学习基准测试中表现优异,其性能至少与现有最先进的技术相当或更好
1. 背景
1.1 视觉表征学习
- 本文考虑的问题是以自监督形式学习通用的视觉表征,即在无需人工标签的情况下训练可用于各类下游任务的 CV backbone。本文之前的主要有三种技术路线
- 生成式方法:目标是生成或建模输入像素空间,代表方法有 VAE、GAN 等。这类方法的缺点是计算开销大,而且未必对表征学习必要
- 判别式方法:通过设计 “监督学习预训练任务” 来学习表征,输入和标签都来自无监督数据。常见代表任务有图像上下文预测、Jigsaw拼图、图像上色、旋转预测等。这类方法依赖启发式任务设计,可能限制学习到表示的通用性
- 自监督学习:
1.2 对比学习
-
对比学习的核心思想是:通过构造正负样本对,让模型学到一个判别性的表示空间,在这个表示空间中 相似的样本尽量靠近,不同的样本尽量分开,这是当前自监督学习的主流方法
所谓判别性,是指同类样本聚在一起,不同类样本分得开,空间中的样本分布能有效地区分不同类别或语义
-
作为一种无监督(自监督)方法,对比学习的目标是学习样本特征的表示方法,即得到一个样本编码器。在此基础上增加分类/回归头并微调即可适用于各种下游任务,这样一种半监督(Semi-supervised)/ 自监督(Self-supervised)结合监督微调的典型流程如下图所示
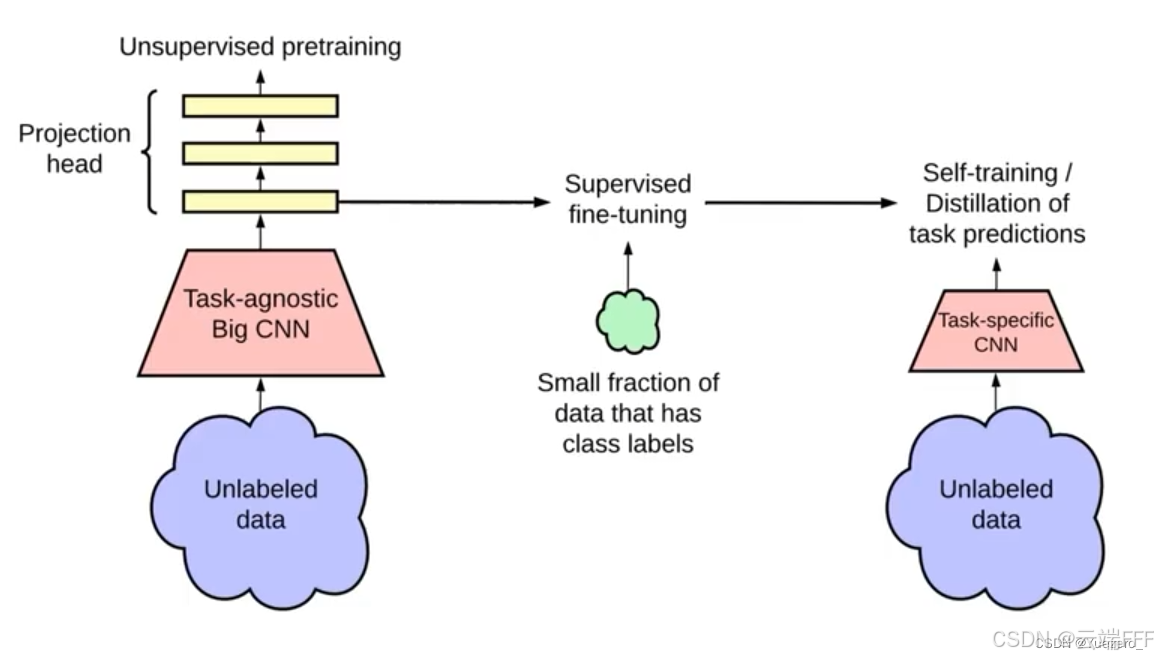
- 无监督预训练:使用 SimCLR 等方法,利用大量无标签数据训练 Encoder,其一般由任务无关的大规模 CNN 和映射到表示空间的投影头 MLP 组成
- 监督微调:经过预训练后,使用针对下游任务的少量有标签数据进行监督学习,将原本 “通用” 的特征调整为对特定任务有用的特征
若监督数据量大,微调后即可以直接用于下游任务,或在第3步蒸馏到小模型 若监督数据极少,这一步后很可能过拟合到微调数据,需在第3步进行自监督训练
- 自监督/蒸馏:用微调后的模型为大量未标注数据构造伪标签,从而扩展第2步的小数据集。然后可以继续微调模型(常见于 FixMatch 等半监督方法),或重新训练一个新模型(常见于模型蒸馏或 Noisy Student 等 “教师-学生” 框架)。现代方法通常倾向于 “教师-学生” 框架,因为它可以反复迭代,逐步提升性能
扩展数据集的标签来自第2步的微调模型,伪标签并不提供新知识,为何自监督训练还能提升性能呢。原因包括
- 无标签数据覆盖了更大的目标分布空间,迫使模型在更大的空间进行拟合,缓解了对真实标记数据集的过拟合问题。这类似于数据增强思想:标签不完美但覆盖广,能正则化模型
- 高置信度伪标签相对可靠,模型对部分样本的预测可能非常自信,如果只挑选置信度高的伪标签来训练(confidence filtering),那扩展数据集的质量其实不错。通常这些样本落在真实标记数据集样本的内插空间中,可以让模型对这部分的拟合更精细
- 即使部分伪标签是错的,但只要噪声不系统性偏向某类,其可以看作一种正则化手段,深度模型通常能从大规模数据中“滤掉”一部分噪声。引入噪声标签后,模型训练时会受到 “矛盾的监督信号”,这迫使其不能死记硬背标签,而要在更大数据分布里找到决策边界,比如 NLP 中的标签平滑就是这个思路
- Student 可以比 Teacher 更强,Noisy Student 框架里,Student 用到了更大模型、更多数据增强、Dropout 等正则,使其性能比 Teacher 更强
2. 本文方法
2.1 移除负样本对
-
SimCLR 等早期对比学习工作大都属于 “实例分类的判别性方法”,该方法将每张图像视为不同的类别,并通过区分数据增强后的不同类图像来训练模型。当图像数据很多时,明确学习一个分类器来区分所有图像是很困难的,实践中必须引入大 Batch Size 或外部存储库来增加负样本对数量。
-
针对该问题,BYOL 通过以下思路去除对比学习中的负样本对:
- 和传统方法一致,从同一张图像采样两种不同的数据增强视图,形成正样本对
- 不再考虑构造负样本对,此时对比学习的训练目标只剩下 “让正样本图像输出特征接近”,直接这样训练很容易导致 backbone 出现模型坍塌,即模型对所有输入都输出相同的特征值
- 为避免模型坍塌,不再用一个 backbone 提取视图特征,而是引入不对称的两个网络分别提取两个增强视图特征,通过 “教师-学生” 方式进行训练:
- 在线网络 (online network):真正被优化的网络,由编码器 (ViT/CNN)、投影头 (MLP)和预测器 (MLP)三部分组成。它作为 student,要学习 target network 的输出
- 目标网络 (target network):结构与在线网络相同,但没有预测器**,它的参数 由 online network 的参数做滑动平均 (EMA)** 得到。它作为 teacher,通过缓慢更新为 student 提供稳定的学习目标
-
下图显示了 SimCLR 和 BYOL 的模型结构差异
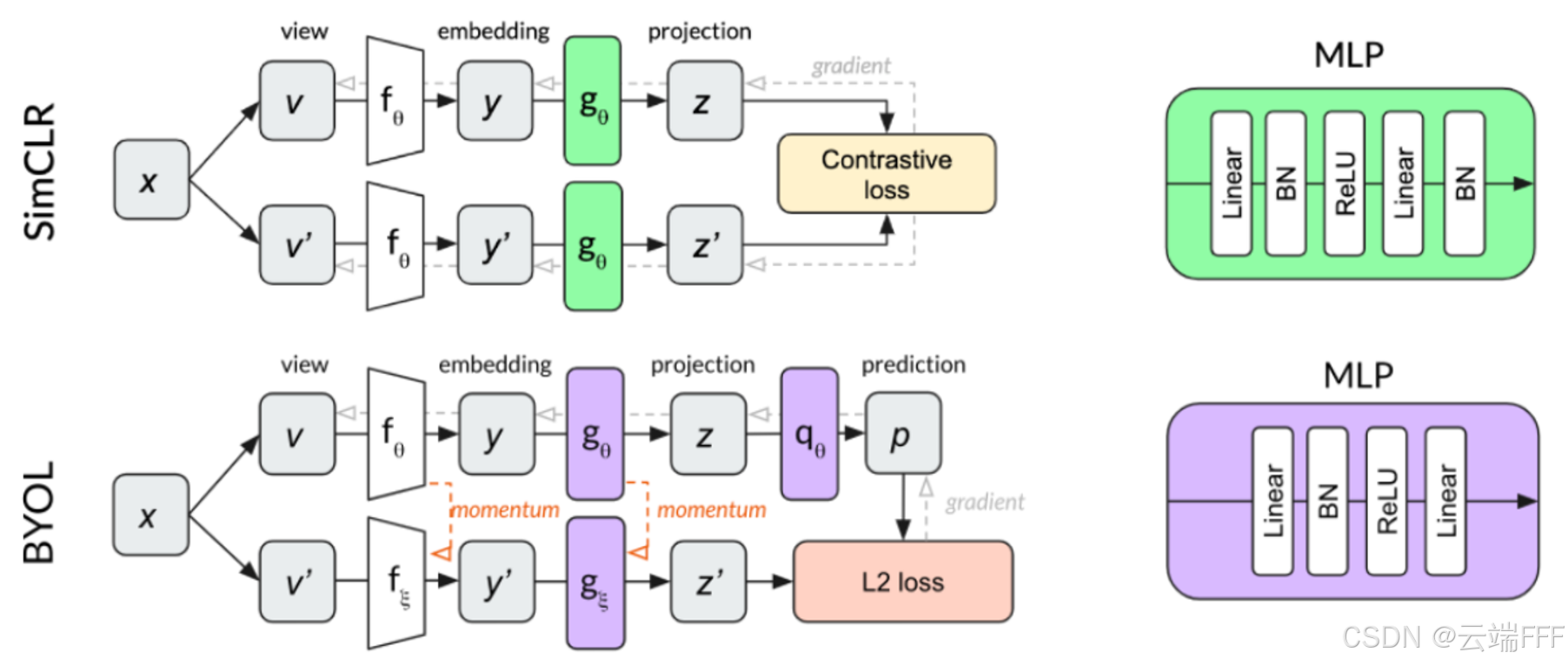
注意 BYOL 的 teacher 不是另一个提前训练好的模型,而是自己过去的状态的平均,相当于自己教自己,所以叫 self-distillation / bootstrap
- 监督学习里知识蒸馏(knowledge distillation) 指用一个训练好的大模型作为 teacher,训练小模型 student 拟合 teacher 的输出分布,从而缩小模型参数量
- BYOL 这个自蒸馏(self-distillation) 和 RL 算法中 target 网络很像,比如 DQN 中的 target Q-Network
-
下图显示了 BYOL 的训练过程
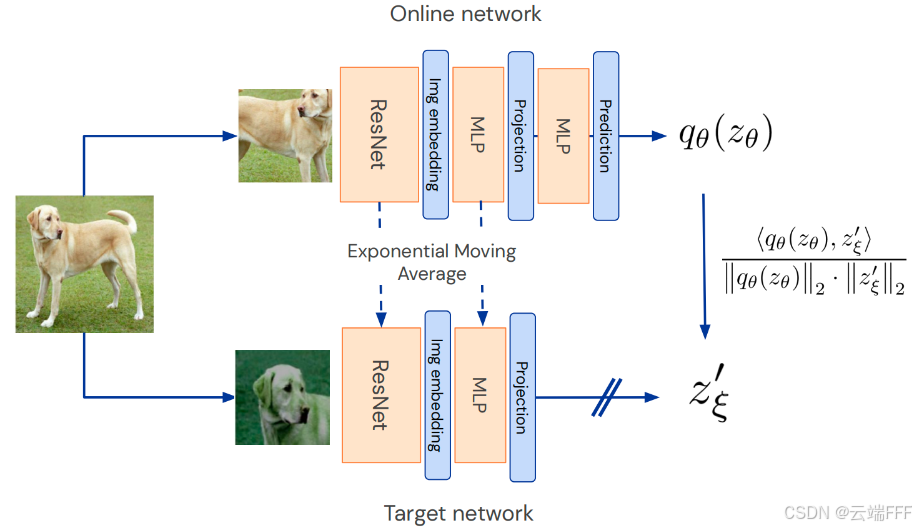
- 从数据集中采样图像 ,从两个图像增强分布中采样两种增强方法 和 ,生成两个增强视图 和
- Target network 分支输入增强视图 ,输出表示 和目标投影 ;Online network 分支输入增强视图 ,输出表示 、投影 和预测
- 令 Online network 预测 逼近目标投影 。先对 与 做 归一化:
归一化后有 ,通过优化以下归一化 MSE loss 来更新 Online network:
注意这里使用归一化后的 MSE,其本质本质是优化和 的余弦相似度,能让训练关注“方向一致性”(表示的语义)而不是绝对尺度,从而更稳定
Note:实践中会交换增强视图输入的分支计算两次损失,取二者之和作为最终损失
- 每次更新 Online network 参数 后,对 Target Network 参数 进行指数滑动平均(EMA)更新,它也被称为 momentum 网络
指数滑动平均是一种给与最近数据更高权重的平均方法。实验表明动量系数 时效果好, 时模型只能学到 Target 随机初始化的特征,效果不好; 时 Target 不稳定,容易出现模型坍塌
- 训练结束后,和 SimCLR 一样只保留编码器 用于下游任务
-
BYOL 伪代码如下

2.2 避免模型坍塌
- 虽然 BYOL 优化式(2)时没有引入避免模型坍塌的显式项(如负样本),其仍然不会发生模型坍塌,这是因为:在 “预测器 接近最优” 的情形下,BYOL 对 Online network 的更新等价于减少 Target 投影在给定 Online 投影 条件下的条件方差。若 是常量(完全坍塌),这个条件方差达到最大值;任何让 携带信息的扰动都会降低条件方差,因此训练信号会推动模型离开坍塌状态 —— 即坍塌是不稳定的
- 为方便推导,计算损失时不进行归一化时损失,当预测器 收敛是,损失式 (2) 可以表示为
这意味着最小化等价于最大化 ,即使的期望在 条件下有更多变化。当 Online 投影 完全坍塌为常量 时, 无法再更新,有 ,模型坍塌导致训练损失实际上取到了最大值。因此在损失驱动下,模型会受到推动去走出常量映射,坍塌点对应的损失局部不是吸引态,而是可被下降方向逃离的不稳定点(只要 能对不同 给出不同条件均值)。
设 Online 分支中预测器 近似最优,即有 。此时损失函数(为方便推导,不进行归一化)可以写作
记 为向量 的第 个分量,则
带入总体期望并用塔式法则(law of total expectation)得到
对每一项,先对条件 求条件期望再对外取期望(等价转换):
对固定的 (即在条件期望里), 是常数,有
这里是在凑条件方差定义:。回代得到
把分量求和回到向量形式,损失等价于目标投影在给定在线投影 条件下的条件方差的期望
再用 Law of total variance , 得到
- 以上结论基于预测器接近最优的假设,BYOL 的两个设计对于该假设有效性非常必要
- 引入可学习的预测器:Online 分支的额外小 MLP 使得该分支不必直接把编码 映射到目标投影 的同一空间,而可通过学到的预测器 来调节,使 Online 分支输出 更容易逼近条件均值 。若没有预测器( 固定为恒等映射), 很难需直接适配 ,无法保持 近似最优的假设,导致坍塌
- 目标网络用 EMA 平滑():如果 Target network 随 Online network 瞬时剧烈改变(比如直接复制 ),那么目标 本身会非常不稳定, 的假设不再可靠,从而破坏上述分析。EMA 使得能在相对稳定的目标下逐步逼近 ,让损失的梯度真的近似等价于降低条件方差
- 消融实验证明:去掉预测器或去掉 EMA(把目标固定或瞬时更新)都会导致坍塌或性能大跌,说明这两者在维持“预测器近似最优 + 目标稳定” 方面是必要的。
3. 实验
-
实验设置:
- 预训练数据:ImageNet(无标签)
- 网络架构:ResNet-50/101/152 及更大模型
- 优化器:同 SimCLR 使用 LARS 优化器
- 数据增强方式:同 SimCLR,首先 random crop 抠出部分图像,然后 resize 到 224x224 并使用随机水平翻转和颜色失真,最后使用 gaussian blur
-
性能表现
-
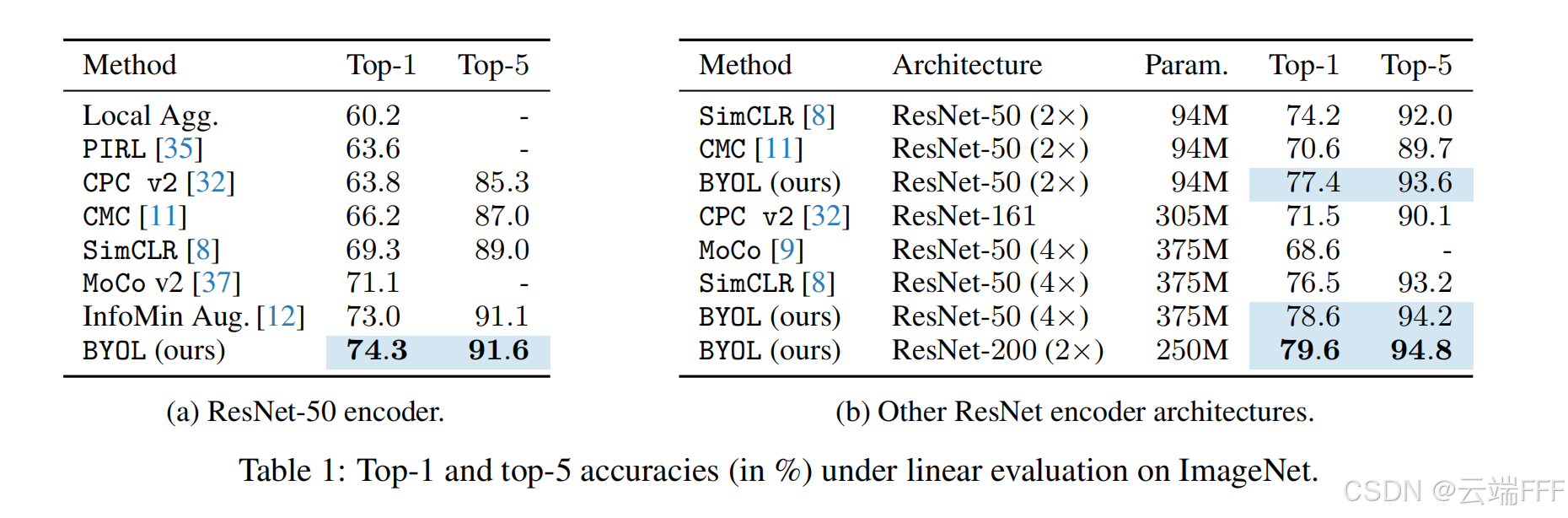
线性分类评估:在 ImageNet 上固定主干,只训练线性分类头
-
半监督学习:在少量标签(1% 或 10% ImageNet 标签)上微调
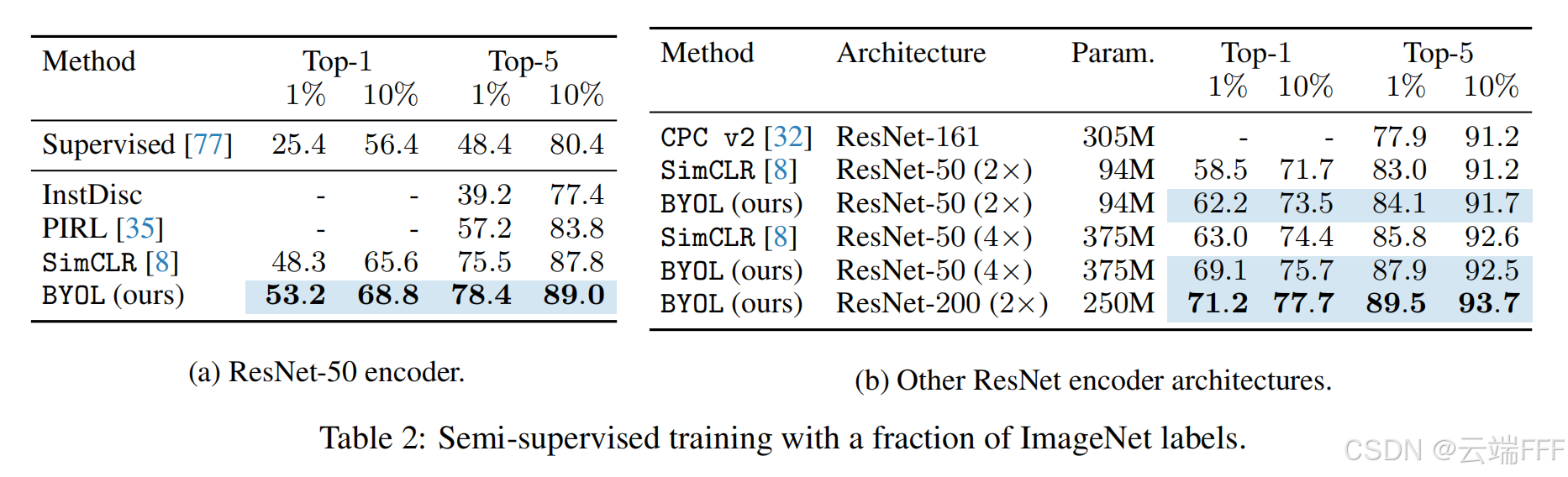
-
迁移学习:在下游任务(CIFAR-10/100、VOC 检测分割、COCO检测、Places205分类等)上微调。
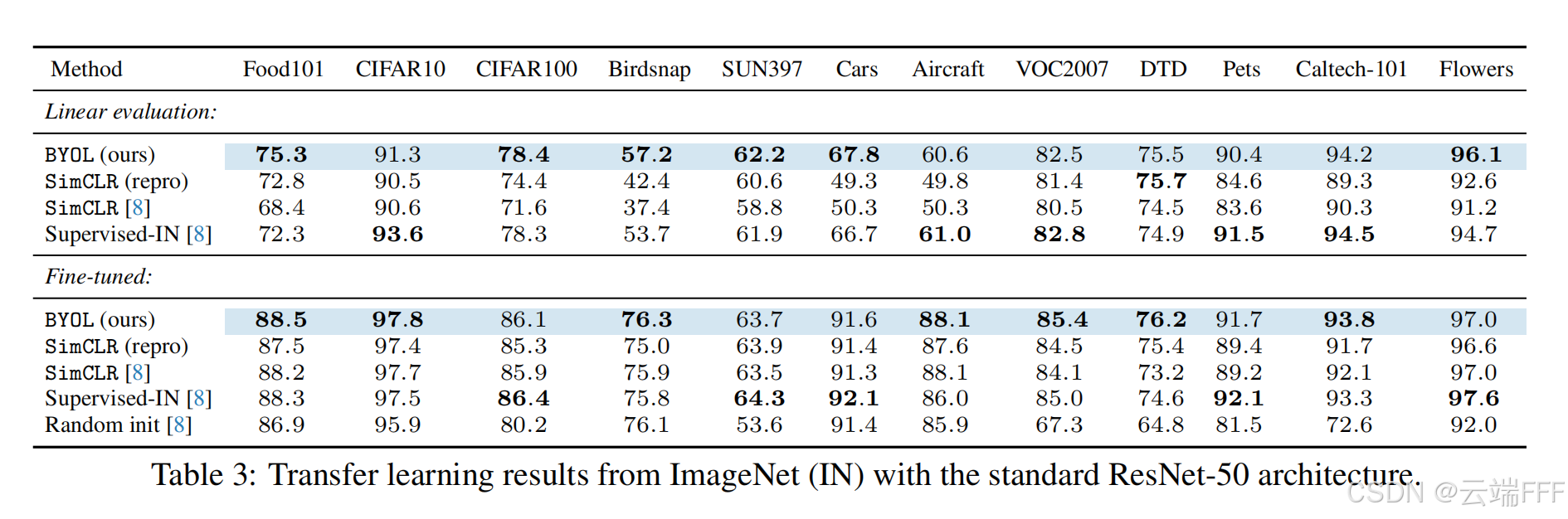
-
-
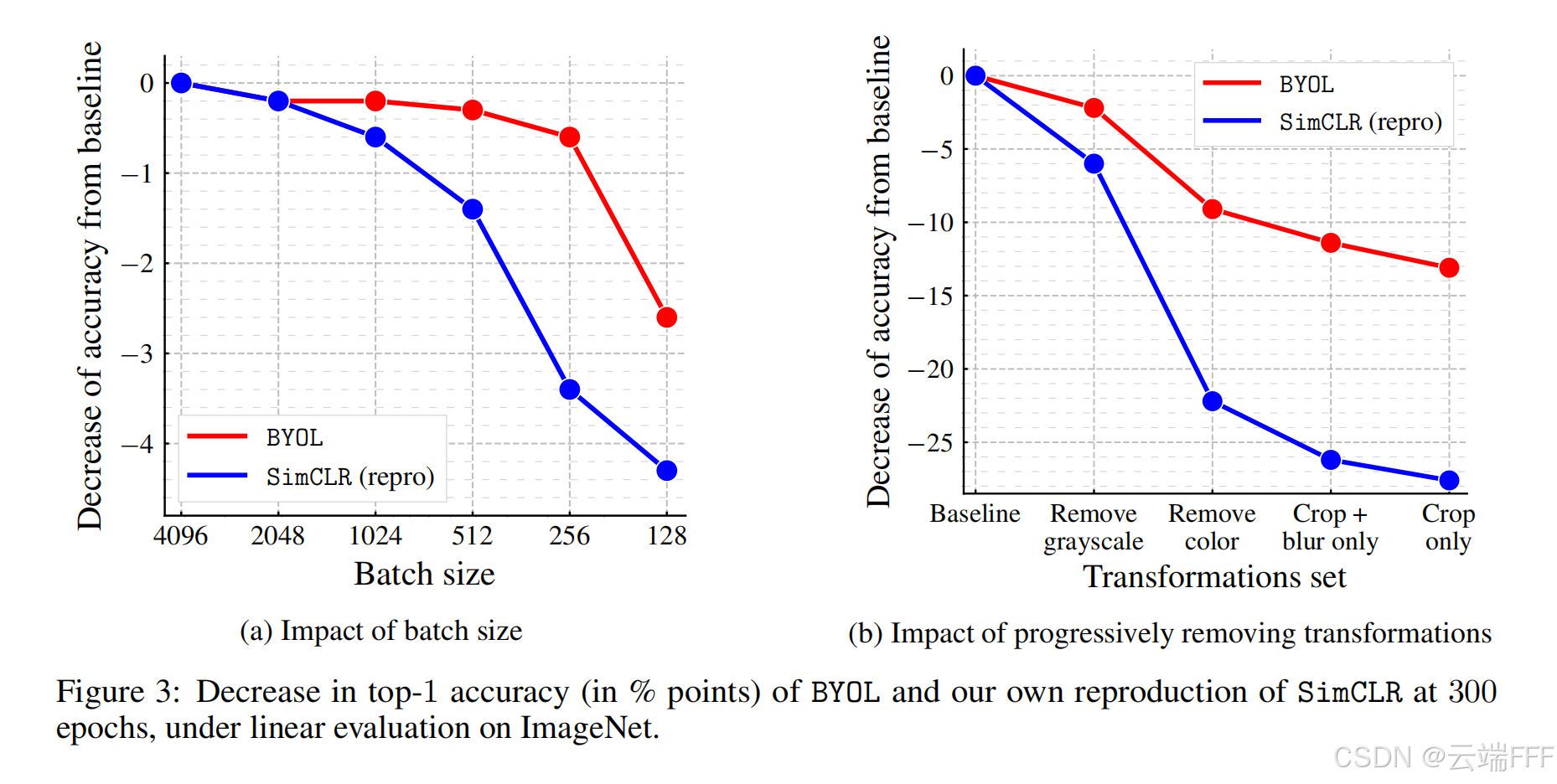
和 SimCLR 对比:SimCLR 需要大量负样本提供判别信号 Batch size 必须设得很大,这导致训练硬件成本高昂,而 BYOL 没有负样本限制,使用小 Batch size 时性能相对好很多
4. 总结
- BYOL 提出了一种无需负样本的自监督图像表示学习框架,通过双网络结构、预测器和动量更新机制,在 ImageNet 等大规模数据集上取得了与甚至超越对比学习方法的表现。其创新点在于:
- 消除了对负样本的依赖:区别于SimCLR、MoCo等对比学习方法,不需要庞大的负样本库或大批量训练,也能学到区分度很强的特征
- 引入预测器(predictor)+动量目标网络(momentum target network):形成不对称结构并提供稳定目标,有效避免了模型坍塌。
- 在 ImageNet 上首次实现无负样本自监督的 SOTA:ResNet-50线性评估达到74.3% Top-1准确率,ResNet-200达79.6%,并在半监督和多种下游任务上表现优异。
- BYOL 展示了自监督学习可以摆脱负样本仍然获得强大表征能力的可能,大幅降低了对复杂对比设计的依赖,也启发了后续一系列基于自蒸馏或教师–学生结构的工作(如 SimSiam、DINO 等)