论文理解【LLM-OR】——【LLMOPT】Learning to Define and Solve General Optimization Problems from Scratch
-
首发链接:论文理解【LLM-OR】——【LLMOPT】Learning to Define and Solve General Optimization Problems from Scratch
-
文章链接:LLMOPT: Learning to Define and Solve General Optimization Problems from Scratch
-
发表:ICLR 2025
-
领域:LLM OR
-
一句话总结:使用 LLM 对运筹优化问题(OR Problem)进行建模和求解代码生成时,传统端到端直接生成方法的准确性与问题类型泛化受限;LLMOPT 引入五要素通用表述 + 多指令微调 + KTO 对齐 + 自动测试自纠错的学习式流程,从自然语言描述出发更稳健地定义并求解多类优化问题,并在六个真实数据集上取得平均 11.08% 的准确率提升
- 摘要:优化问题在各类场景中普遍存在。将自然语言描述的优化问题进行形式化建模并进一步求解,往往需要高度专业的人类知识,这可能阻碍基于优化的决策在更大范围内应用。为实现问题建模与求解自动化,利用 LLMs 成为一种潜在途径。然而当前多数基于 LLM 的方法在准确性方面仍有限,且其能够建模的优化问题类型的通用性也受限。本文提出一个统一的学习式框架 LLMOPT 以提升优化泛化能力。LLMOPT 从优化问题的自然语言描述与预训练 LLM 出发,提出以五要素表述作为学习定义多样优化问题类型的通用模型;随后通过多指令微调提升问题形式化与求解器代码生成的准确性与通用性。进一步地,为防止 LLM 幻觉(例如为了避免执行错误而牺牲求解准确性),LLMOPT 引入模型对齐与自纠错机制。我们在六个真实世界数据集上评估 LLMOPT 的优化泛化能力,并与对比方法比较,这些数据集覆盖约 20 个领域(如健康、环境、能源与制造等)。大量实验结果表明,LLMOPT 能够建模多种优化问题类型(如线性/非线性规划、混合整数规划与组合优化),并相较于现有最先进方法实现了平均 11.08% 的求解准确率提升。代码已开源
1. 背景
- 本文研究优化问题的自动建模与编程,以减轻对人类专家的严重依赖。具体而言,这类问题要求输入一段自然语言描述的问题(如配送货、生产规划等问题),要求模型或系统完成运筹学建模,并生成问题求解代码
- 针对该任务,当前主要存在基于提示和基于微调的两类方法:
- 基于提示的建模prompt-based modeling:通过为 GPT-4o 等大规模预训练 LLM 精心设计建模 Prompt 来工作,相关方法包括 OptiTree、PaMOP、OptiMUS 等。这类方法的重点在于通过引入树、图、多智能体等设计,将 “复杂问题描述上下文 -> 严格式要求代码” 的端到端生成过程拆分为多个子过程,从而降低各环节难度,并使各环节的 prompt 更具针对性和指向性
- 基于微调的建模fine-tuned LLM modeling agents:通过构造大规模运筹学及建模知识对 LLM 进行微调,形成专用的建模语言模型,如 ORLM、Step-Opt、OptMATH 等。这类方法的重点在于设计数据构方法和错误过滤方法,实现多样、正确、难度可控的高质量数据集。此外,从 2025 年开始也逐步出现了基于 RL post-training 的方法,将 OR 建模求解视作 RLVR 任务解决,如 SIRL 等。通过进行针对性训练,基于微调的方法往往可以用更小参数量的模型达成和通用大模型相似的性能
- 作者认为现有方法的优化泛化能力不足,即要么求解不准,要么覆盖类型/跨任务能力不够,例如
- 对于基于提示的方法,作者认为一个典型风险是:LLM 会出现 “为了不报错而写出能跑但不正确代码” 的行为,导致求解精度下降。作者将这归为一种 “幻觉问题”
- 对于基于微调的方法,作者复现 ORLM 时观察到,模型似乎只剩下写代码的能力,并且无法回答其他问题
2. 本文方法
-
本文提出 LLMOPT 框架,致力于提升模型的求解精度和通用性。如下图所示
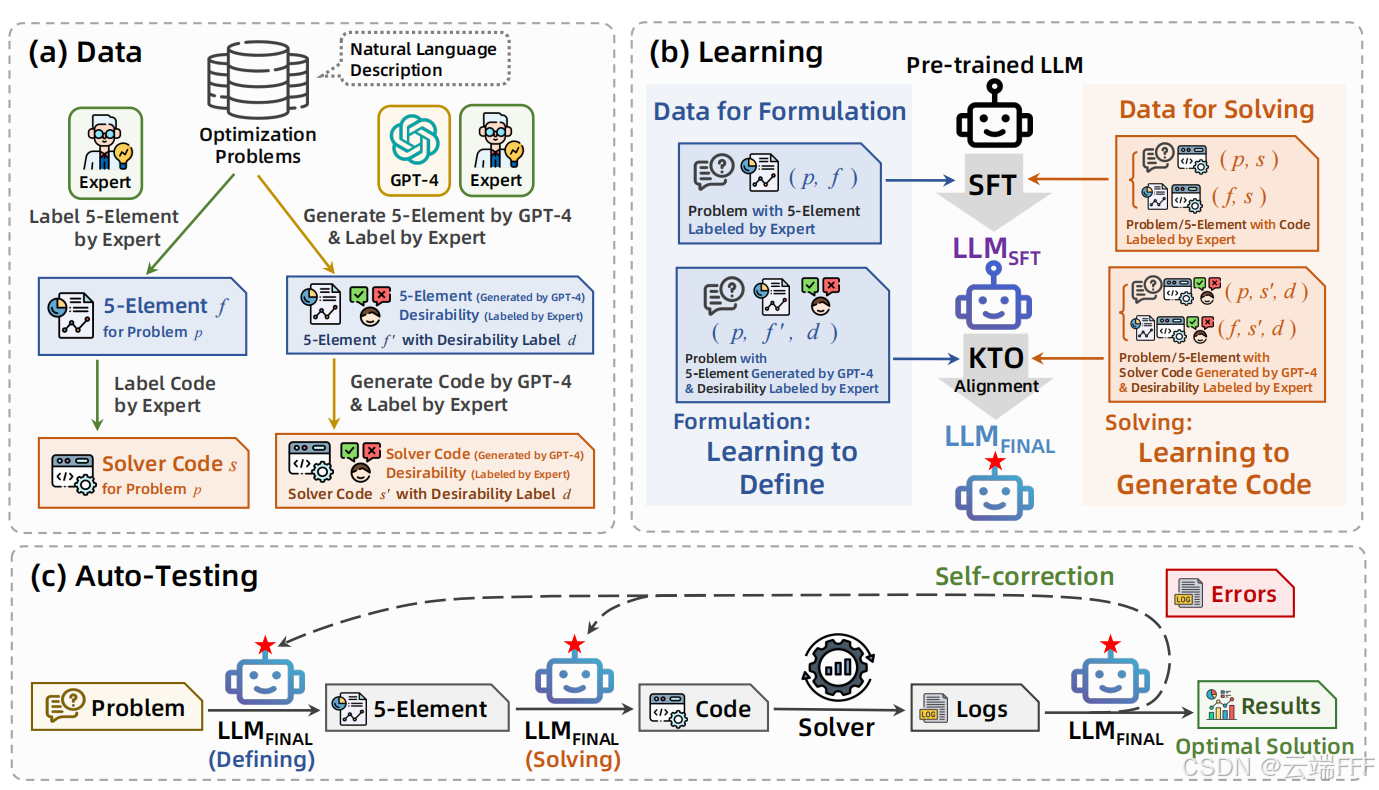
LLMOPT 由三个关键组件组成:数据(data)、学习(learning)与自动测试(auto-testing)
- 数据:用
五要素表述five-element formulation对优化问题进行良好定义,专家与 GPT-4 协同完成五元素公式及求解器代码标注 - 学习:
多指令监督微调multi-instruction supervised fine-tuning来提升 LLM 在 “定义” 和 “求解” 优化问题两方面的准确性,并引入模型对齐model alignment以进一步提升准确性并降低幻觉风险 - 自动测试:建立
自纠错机制self-correction mechanism自动测试流程,实现优化问题的自动定义和求解
- 数据:用
2.1 数据:优化问题的通用定义与标注
2.1.1 优化问题的五要素表述
-
数学上,一个优化问题可以形式化表示为如下表达式:
其中, 是 维决策变量, 是 的可行域,目标是最小化目标函数 。约束由向量值函数 表示,其中 表示一系列不等式约束,且 是这些约束的上界向量
-
作者提出基于优化问题的 5 个关键部分:
集合Sets、参数Parameters、变量Variables、目标Objective与约束Constraints定义优化问题的通用描述形式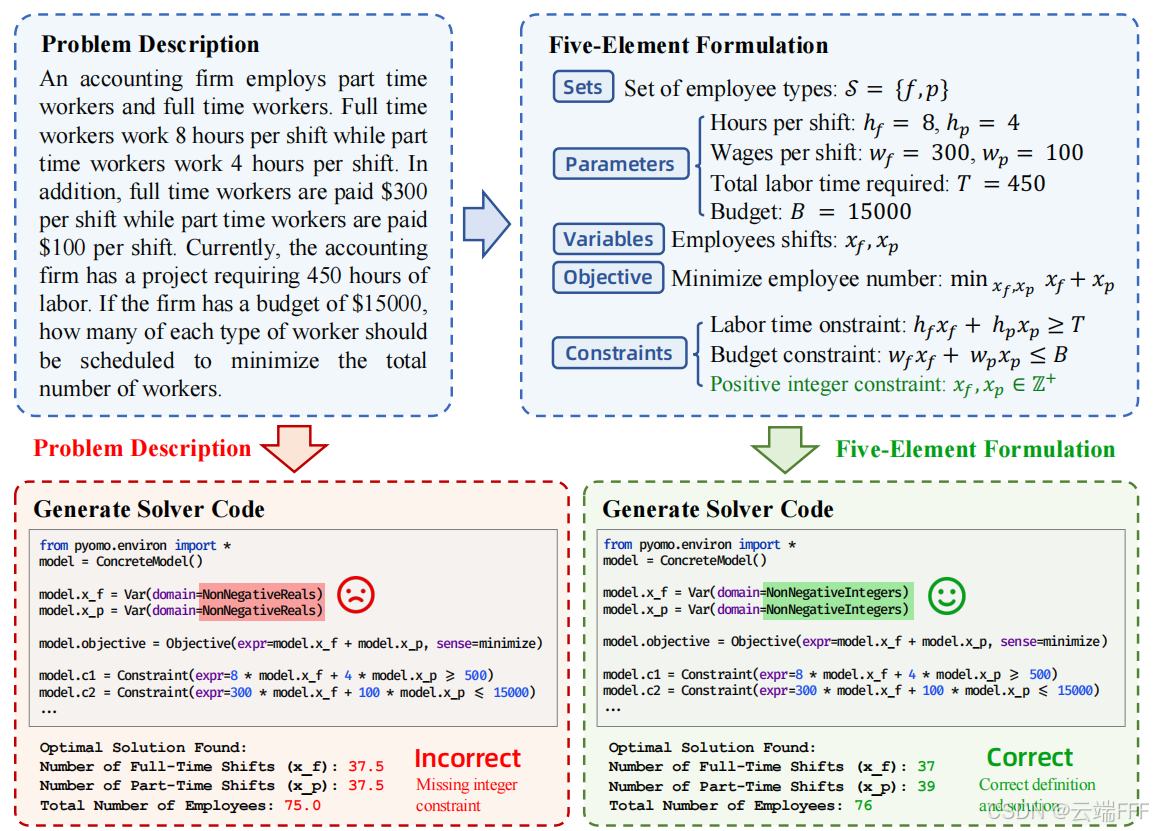
- 集合、参数提供索引与描述的细节信息,以及目标函数和约束中涉及参数的具体数值
- 变量、目标、约束分别对应决策变量 ,目标函数 与约束 ,并为每项给出简洁描述
-
使用五要素表述定义问题有以下优势
- 建模表述更精准,例如上图中 “正整数约束” 在自然语言问题描述里是隐含的,但五要素表述能够有效捕获该信息
- 通用性强:通过调整目标和约束,五要素可以定义多种类型的优化问题,包括整数规划(调整 可行域)、线性与非线性规划(调整 )、多目标优化等(调整 )
2.1.2 数据增强与标注
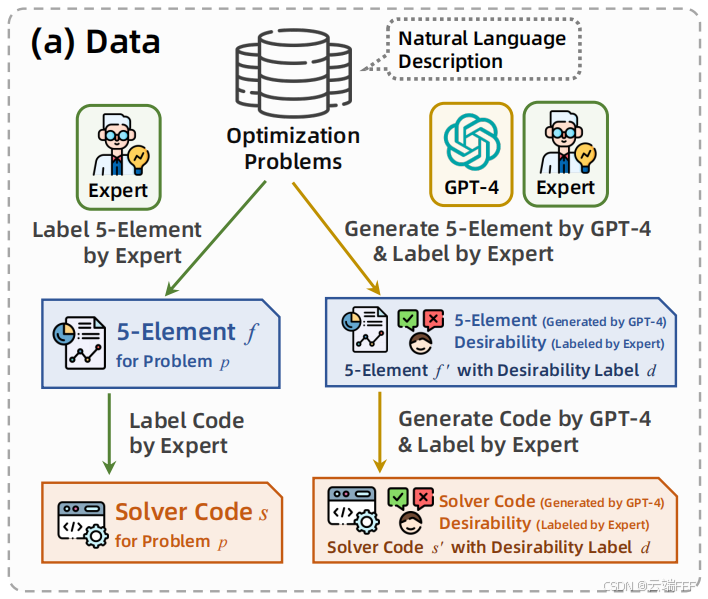
- 现有数据集大多缺少五要素表达和求解代码标签,需进行数据增强,本文数据增强与标注流程如下
-
首先收集现有 OR 任务数据集,从每个数据集中随机抽取 100 个样本作为保留测试集(尺寸小于 100 的数据集全部用于测试),其余用于数据增强
-
使用 LLM 对原始问题进行扩展,生成的问题交由人类专家进行审查,移除描述不清或解不可行的问题,以确保数据多样性与质量
本文对 1,763 个种子问题应用了 7 类不同指令,从多个角度对原问题进行扩展,例如修改约束、改变场景、改变优化类型、以及从原问题分叉生成新问题等。Prompt 模板如下
数据增强规则如下

-
如下图所示,人类专家和 GPT4 模型分别对每个问题填写五要素建模标签 和求解代码标签 。由于 GPT-4 可能产生错误,专家会对 进行验证,并给出一个可取性(desirability)标签 来指示 GPT-4 的标签是否准确(True/False)
数据合成的人力成本非常高昂,共有 12 位人类专家参与工作。该环节产出两类数据
- 完全准确的建模与代码,用于后续的多指令监督微调阶段
- 可能存在错误但已被专家验证并带有可取性标签的数据,用于后续的模型对齐过程
-
2.2 学习:多指令 SFT 与模型对齐
- LLMOPT 的模型训练包含 SFT 和基于 KTO 的人类偏好对齐两个环节,如下图所示
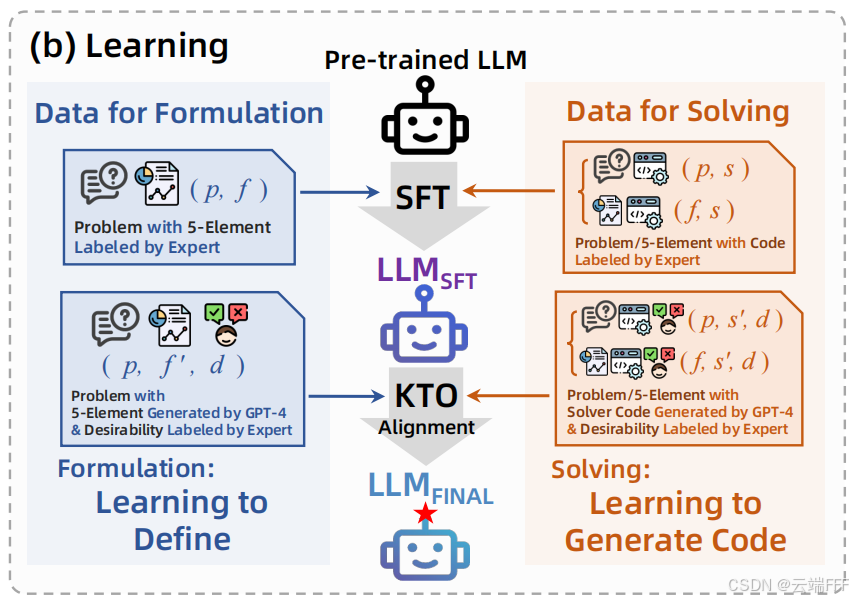
2.2.1 多指令 SFT
- 2.1.2 节人类标注得到两个数据集
- 数学建模数据集 :其中 表示将问题 套入 prompt 模板后的输入, 表示相应的五要素建模
- 求解代码数据集 :其中 为问题描述 或五要素建模 , 表示相应的求解代码,也就是说这是两种数据的混合数据集
- 监督微调阶段,直接把两类数据集混合 ,然后最大化条件概率 ,优化以下负对数似然损失
同时优化模型 “定义与求解” 两方面的能力
这里和之前一些工作的差异在于,传统基于微调的方法如 ORLM 和 Step-opt 往往把数学建模和求解代码构造到一起,用形如 的数集进行训练,使模型同时顺序完成数学建模和代码编写。即:
- 传统方法学习
- LLMOPT 同时学习使用不同 prompt 模板组织的 ,,
本文没有分析为何不用这类传统方式,但是可以进行一些猜测
- 作者希望单独强化模型从五要素建模这种通用表征进行代码生成的能力 。如果用 这种数据,那么最合适的 还是问题原始描述 ,那就缺失了 的通路
- 作者希望降低子问题难度,如果联合在一起生成,输出格式更难把控,也更难分析错误原因
- 作者定义的自动求解流程需要独立的 和 能力,这允许对代码错误进行独立纠错
2.2.2 模型对齐
- 为了缓解 SFT 后的模型幻觉问题(即输出看似合理,但实质不准确的建模或代码),作者引入
模型对齐model alignment训练阶段,这也是传统方法没有使用的组件。具体地,2.1.2 节所述的数据增强过程中人类专家对 GPT4 自动合成的建模和代码进行了二元可取性标记,这是一种人类偏好的体现,对齐训练就是为了使模型和人类偏好对齐,从而减弱模型幻觉,提升输出正确性标准的对齐方法是 RLHF,即先使用人类偏好排序数据 训练奖励模型,然后做 Online RL。为了降低在线 RL 成本,DPO 方法使用离线的成对偏好数据 进行监督学习训练。一种朴素的想法是把专家数据作为 ,把 LLM 数据作为 ,然后做 DPO 训练,但这并不合适,因为
- 负样本不干净,使用 LLM 生成的数据也有正确的
- 正样本有多种等价表达,可能两个完全不同的数学建模/求解代码标签都是正确的,无法排序
- 基于本文的数据标注形式,作者使用 KTO (Kahneman-Tversky Optimization) 作为对齐方法。其使用的数据格式为
其中 是指令提示, 是 GPT4 生成的模型补全内容, 是二元正确性标签
理论角度,KTO 用一个 sigmoid 形式的 “满意度分数” 把两件事揉在一起
- 这个 completion 是不是 desirable(True/False);
- 新模型 相对参考模型 偏离得有多大(用 KL 形成一个“参考点”来控制)
下面逐步来理解这一点
- 先看 KTO 在优化什么量。首先 alignment 类方法的优化目标可以转换成类似 RL 的收益最大化形式。对于 KTO 来说,可将对齐目标写成基于对数概率比的得分
这里 是参考模型(SFT 模型), 是当前模型。直观上:如果某个 completion 在 下比在 下更 “被偏好”(概率更大),那 为正(对应正奖励),反之为负。它衡量了当前模型相对参考模型 有多偏好 completion 2. 使用 KL 散度描述当前策略 和参考模型的偏离程度,定义
它可以理解为 当前模型在平均意义下,相对参考模型 对其 “自己会生成的那些补全 有多偏好 3. 根据 “前景理论” 思想,评价一个补全 的好坏,不是看其绝对奖励值大小,而是相对参考点 的优劣。由此构造价值函数,用于评估每个样本在 “对齐目标” 下的
满意度分数可见这个价值函数就是把以上两者做差再过 sigmoid 函数压缩到 得到的一个软分数,分两种情况
- 若 ,补全 质量高, 应高于 (样本偏好>平均响应偏好)
- 若 :补全 质量低, 应低于 (样本偏好<平均响应偏好)
因此 越大(越接近1),说明这个样本在当前方向上做对了,满足对齐要求。直观上看, 可以看作 “相对参考模型,我把这个答案 的概率抬高/压低了多少倍” 的对数尺度:正值表示抬高(更偏好),负值表示压低(更排斥),绝对值越大表示改动越激进;而 是这种改动在整体分布上的平均水平,KTO 就是在用它来要求:好答案的提升要超过平均,坏答案的提升要低于平均(最好被压下去)
- 基于以上理论分析,我们基于 KTO 的满意度分析来定义其优化损失函数
其中 是权重函数
该损失鼓励模型 生成更贴合专家标注数据的 completion,从而提升问题表述与求解器生成两方面的整体优化泛化能力
2.3 自动测试:表述、求解与自我纠错
-
自动测试流程自动化了 “问题定义 + 求解器代码生成” 的完整工作流,并集成自我纠错机制以实现持续改进,流程如下:

- 基于自然语言描述,使用五要素框架对优化问题进行表述();
- 为该五要素表述生成求解器代码并执行();
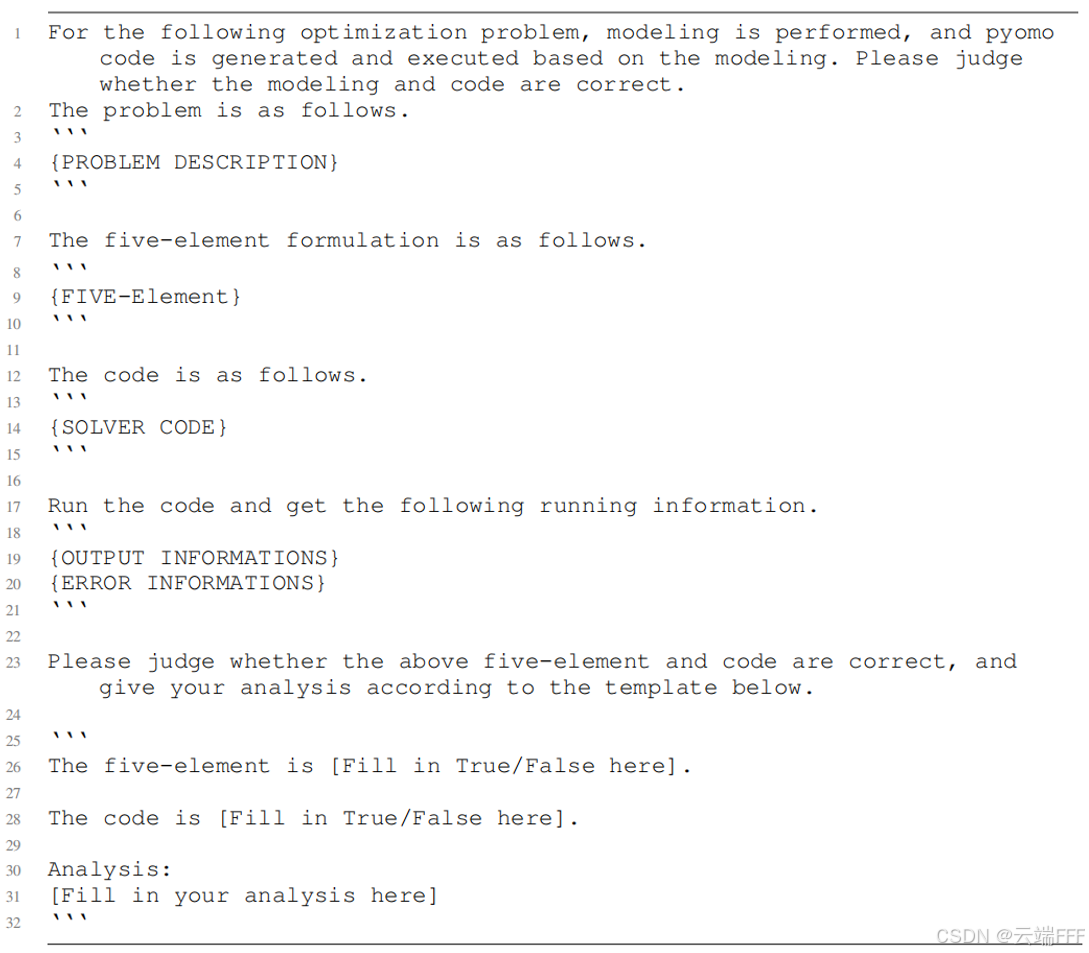
- 分析求解器运行日志(包括输出结果与错误)以判断是否需要自我纠错。这里使用 prompt 模板控制 LLM 判断是否需要进一步处理。若需要处理,模型会生成带建议的分析,并决定返回到 “问题表述步骤” 还是 “代码生成步骤”,确保优化流程更鲁棒、更自适应,提升表述与最终解的准确性,从而改进优化泛化能力
问题分析 prompt 模板如下
3. 实验
- 作者基于 Qwen1.5-14B 进行 SFT 与模型对齐训练,并在大规模数据集上与多种学习式方法与提示式方法进行比较。旨在回答以下四个关键问题:
- 学习式 vs. 提示式方法:像 LLMOPT 这样的学习式方法,相比仅依赖提示工程的 LLM有何优势?
- 优化泛化能力(准确性与通用性):与已有方法相比,LLMOPT 在多大程度上提升了优化泛化能力?
- LLMOPT 中“问题定义”的重要性:提出的 “五要素” 作为中间步骤,如何促进优化任务求解准确性提升?
- 模型对齐在 LLMOPT 中的效果:模型对齐在增强 LLM 求解优化任务准确性方面有多有效?
3.1 实验设置
- 数据集与覆盖范围 论文在 6 个真实世界优化/运筹数据集上评测:NL4Opt、Mamo(EasyLP 与 ComplexLP)、IndustryOR、NLP4LP、ComplexOR。覆盖约 20 种应用场景与 7 类优化问题类型
- 训练/测试划分与训练数据来源 训练与测试严格分离。对 NL4Opt 和 Mamo(EasyLP/ComplexLP),作者将原始数据集打乱,并从每个数据集中随机抽取 100 条作为测试集,其余样本作为数据增强的种子(seed);IndustryOR 沿用其原始划分。由于 NLP4LP 与 ComplexOR 数据规模较小,这两个数据集全部用于测试,不参与训练
- 评估指标 采用三项指标评估 “优化泛化” 能力:
- 执行率(ER):生成的求解代码能无错误运行并输出结果的比例;
- 求解准确率(SA):正确求解优化问题(找到最优解)的比例;
- 平均求解次数(AST):测试阶段自纠错过程的平均执行次数,最多允许重新求解 12 次
- 对比基线
3.2 优化泛化能力分析
-
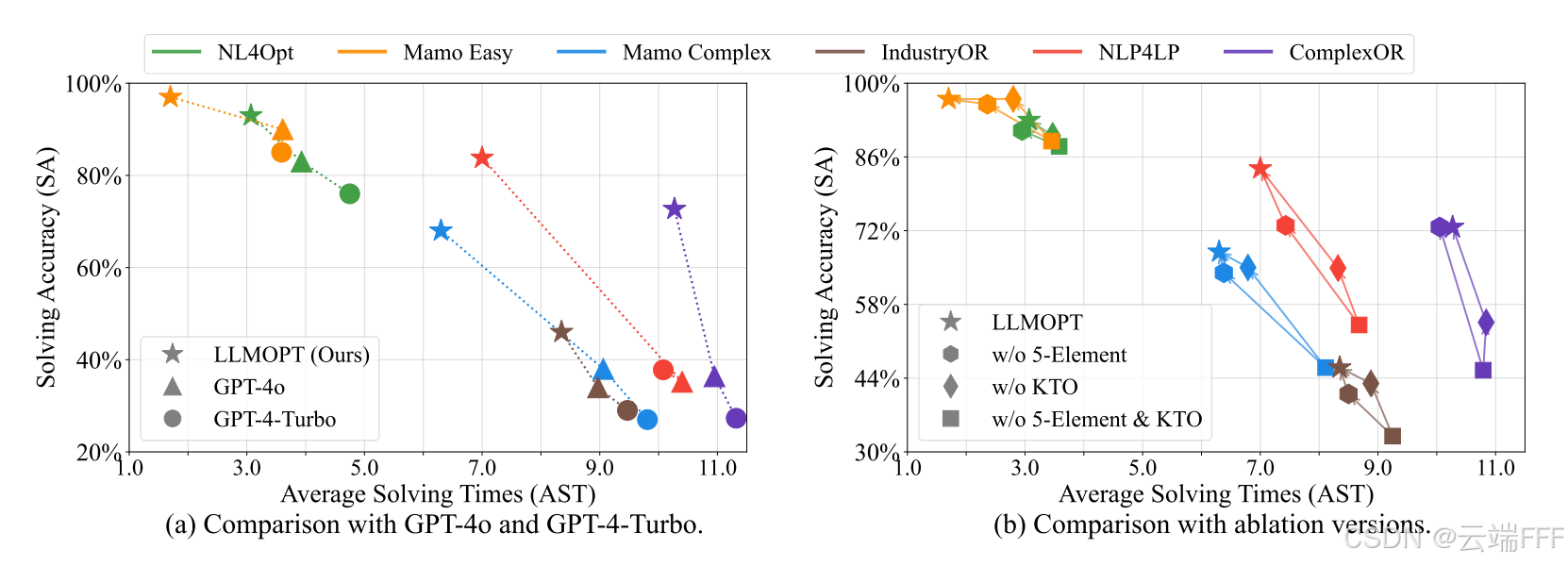
【Q1】学习式 vs. 提示式:LLMOPT 在 6 个数据集上以更少的求解次数取得更高的求解准确率,优于 GPT-4o 与 GPT-4-Turbo,体现了 Learning-based 方法的潜力
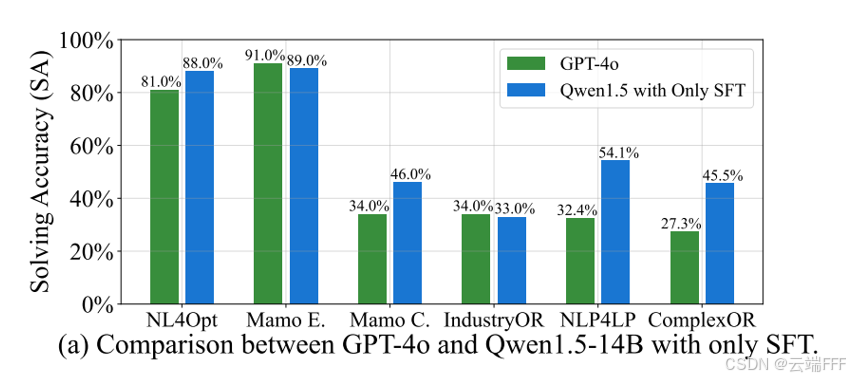
此外,在 14B 模型上,仅 SFT 即可达到 GPT-4o 的水平
-
【Q2-1】准确性:LLMOPT 在 6 个数据集上均取得 SA 的 SOTA。相较学习式方法,五要素定义与自纠错流程提升准确性,在 4 个数据集上平均提升 14.83%;对提示式方法而言,SFT 与模型对齐增强了求解能力,在 3 个数据集上平均提升 10.67%。总体上,LLMOPT 在 6 个数据集上的 SOTA 平均提升为 11.08%
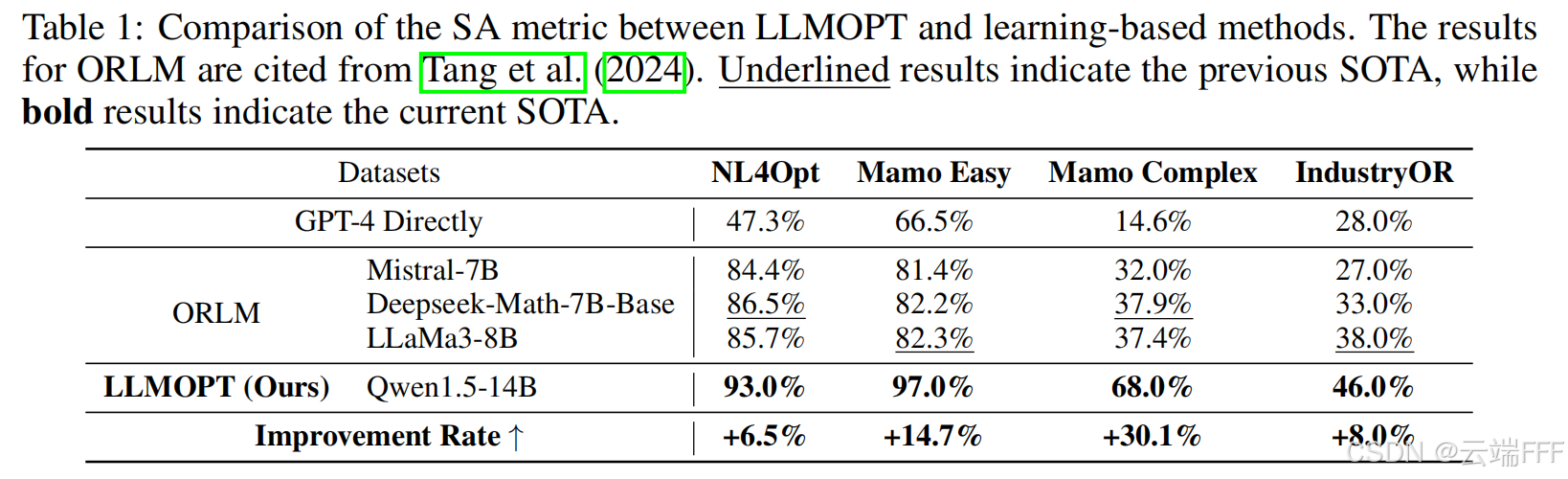
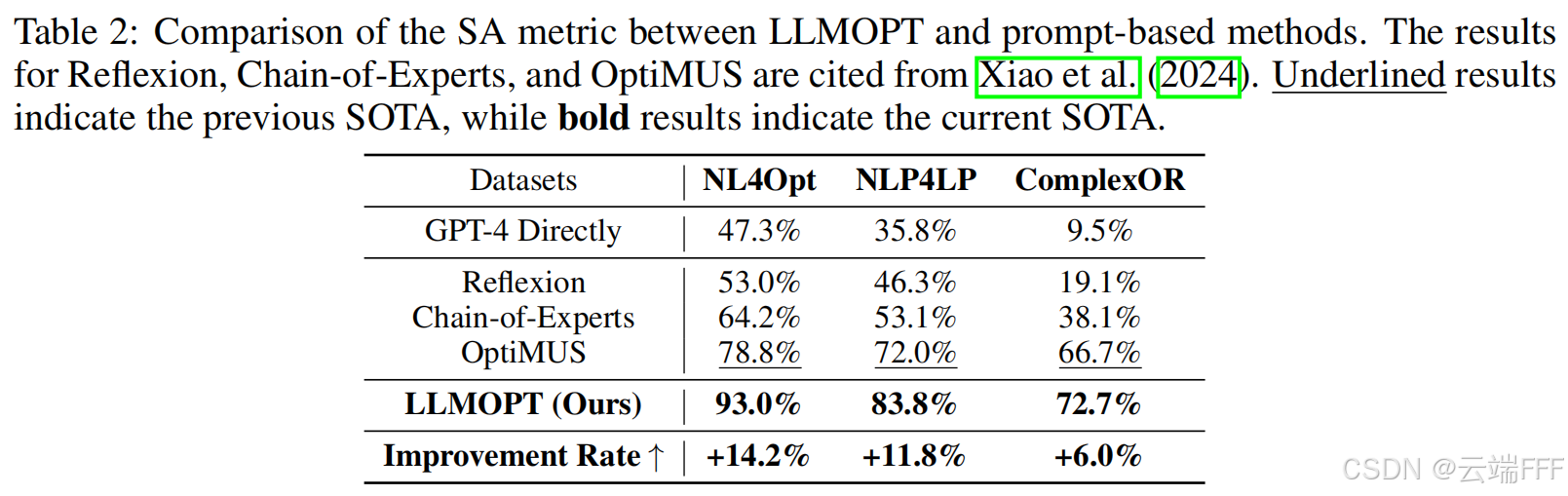
-
【Q2-2】通用性:LLMOPT 在包含多种优化问题的所有数据集上取得 SOTA,体现了其通用性。这里作者在 6 个数据集上测试,覆盖多种优化类型:线性规划、非线性规划、整数规划、混合整数规划、多目标优化、组合优化,且跨越农业、能源、医疗等 20+ 个领域
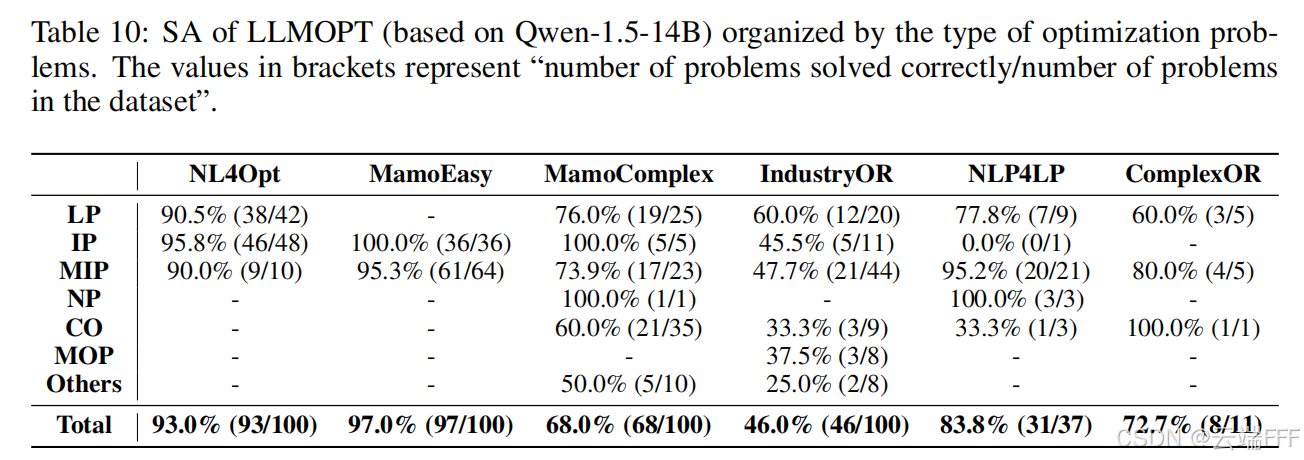
此外,尽管训练集中不包含 NLP4LP 与 ComplexOR 数据,LLMOPT 仍在它们上取得 SOTA(见 Q2-1 表 1),进一步证明通用性
3.3 消融实验
-
【Q3】问题定义的重要性:五要素问题定义能提升 6 个数据集上的 SA。但该定义有时会降低 ER:没有五要素时,LLM 可能“过度简化”问题,从而生成无错误但不准确的代码;相反,使用五要素能保证生成更正确的代码,以略微降低 ER 为代价提升 SA
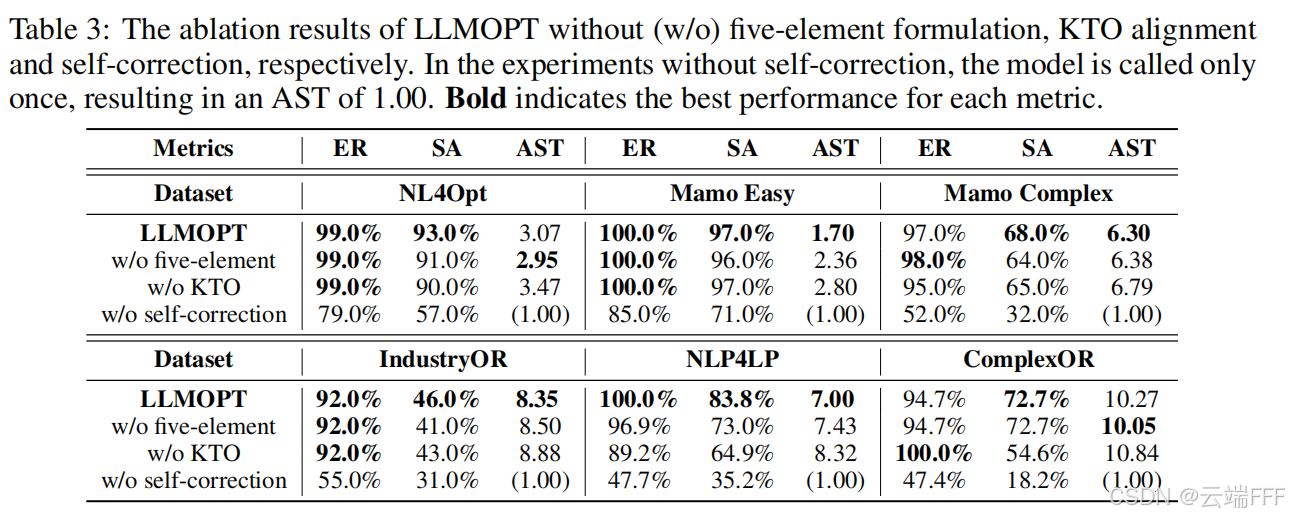
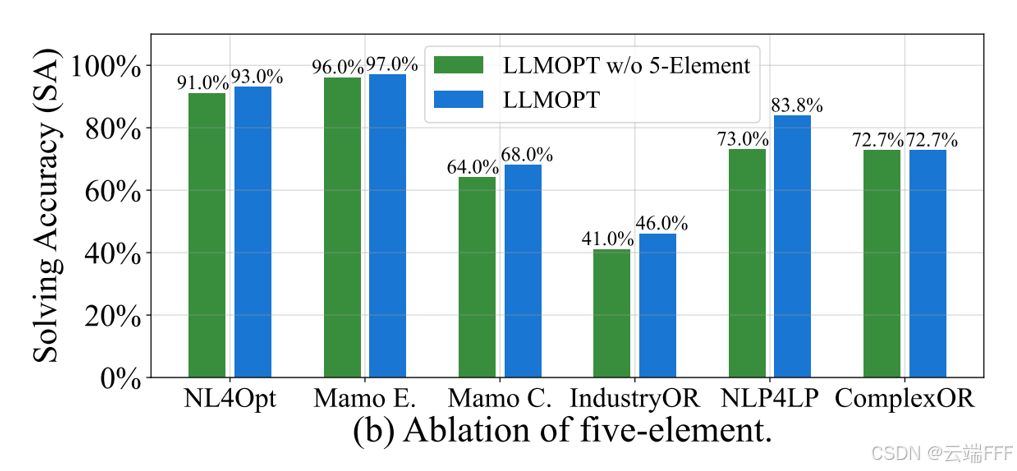
-
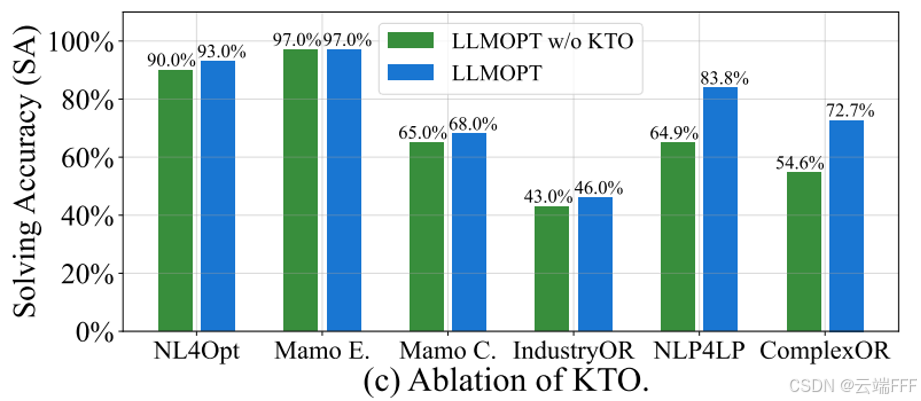
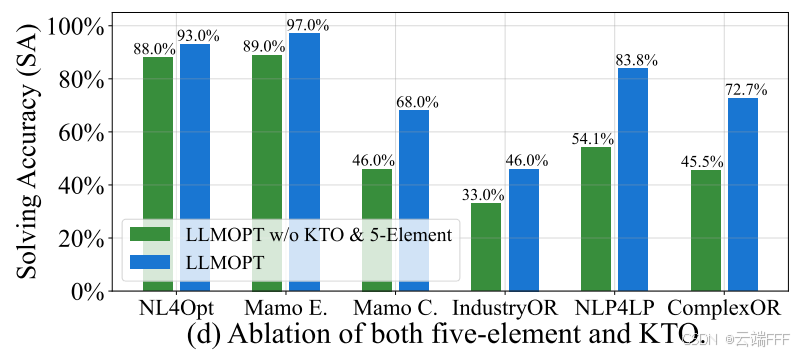
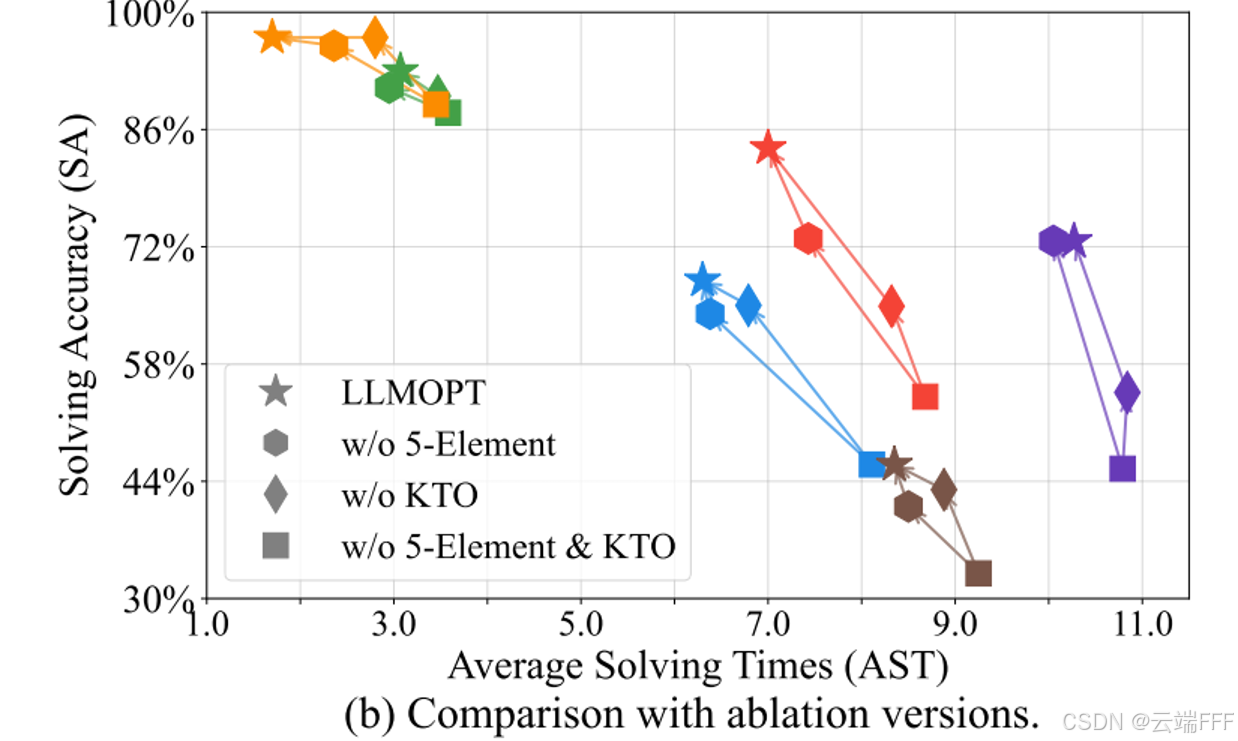
【Q4】模型对齐的有效性:对齐通常提升 LLM 在特定任务上的效率与效果。KTO 对齐不仅显著提升 SA,也在 6 个数据集上降低 AST
3.4 讨论
-
更大的基础模型:如图所示,使用 72B 的基础模型可以进一步提升 SA 和 ER,但训练/部署成本高
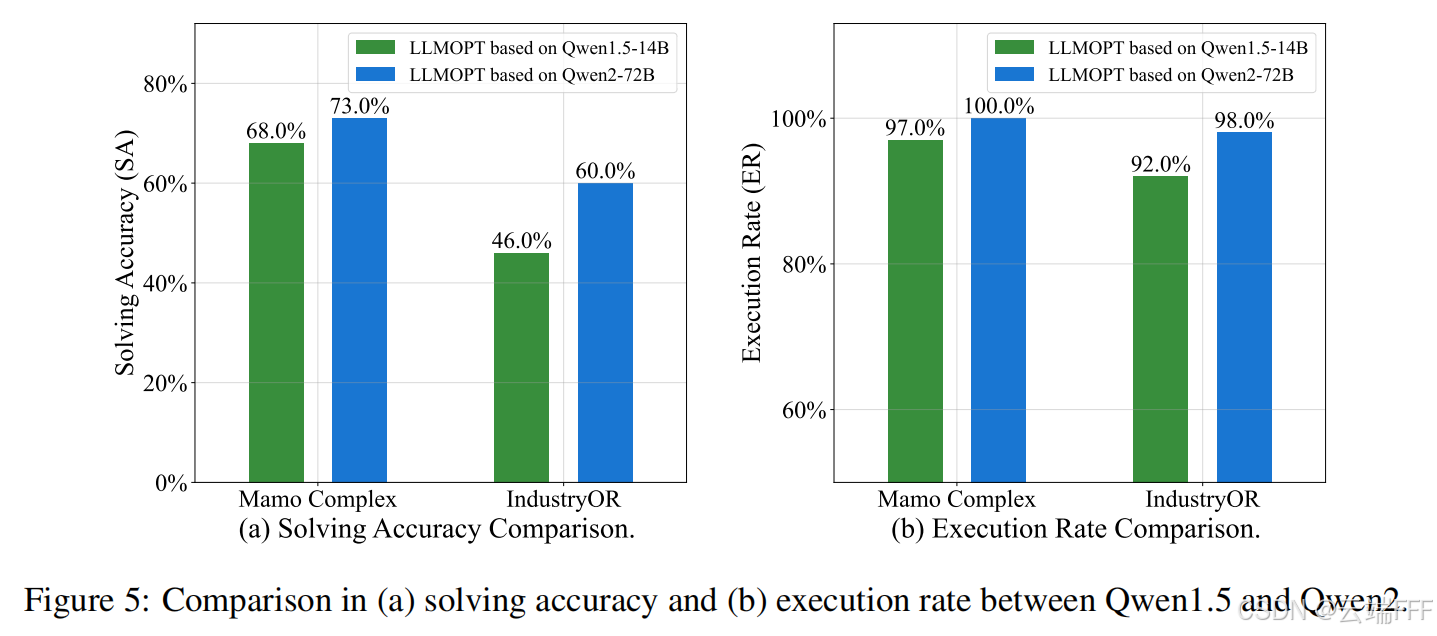
-
和推理模型(OpenAI o1)的比较:作者从 Mamo Complex 数据集中抽取了 10 个简单问题与 10 个复杂问题进行实验。单次调用下,o1 模型成功生成代码并解决了 7 个简单问题与 5 个复杂问题。这些结果表明,o1 模型在求解优化问题方面相较 GPT-4 系列模型更准确。然而,由于其缺乏开放访问、缺少详细技术规格与训练数据描述,以及使用限制与高成本,采用 LLMOPT 对开源大模型进行微调,在真实工业场景中实现更好的优化泛化能力是一种更具成本效益的解决方案
-
LLM 的 “跷跷板问题”(Seesaw Issue):提升模型在专门任务上的性能与其在多样任务上的泛化之间存在权衡,即某一方面的收益往往会导致另一方面的损失。为评估增强 LLM 定义与求解优化问题的能力是否会影响其在其他任务上的表现,作者比较了模型在微调前后、10 个通用任务上的性能,包括:数学、代码、分类、信息抽取、开放式问答、封闭式问答、文本生成、头脑风暴、改写与摘要
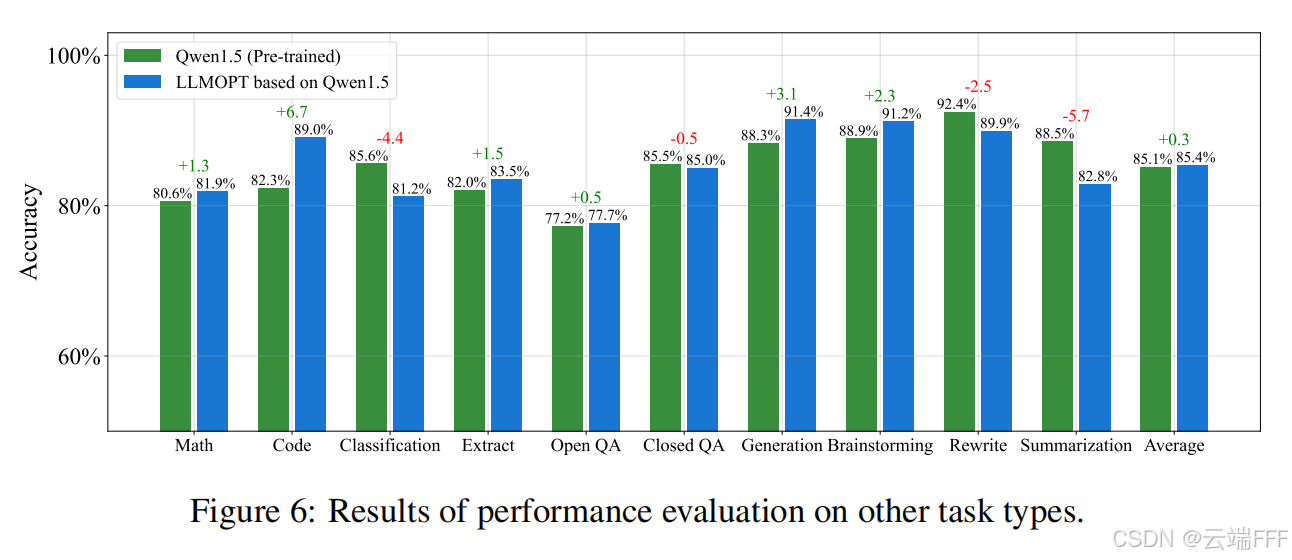
-
关于高质量训练数据:LLM-OR 领域,以自然语言描述的优化问题数据相对稀缺。IndustryOR 数据集中部分数据的最优解标注存在错误;而 NL4Opt 数据集不提供最优解标注,仅提供实体标签。尽管本文采用提示工程进行数据增强,专家标注仍然是一个耗时且劳动密集的过程。未来,如何高效地收集、合成与生成更加多样且标注良好的高质量数据,仍是该研究方向中不可忽视的问题。此外,对于大规模问题,数据通常存储在特定数据库或文件中,而非从自然语言描述中提取;如何理解这些数据结构仍是一个需要进一步探索的新课题
4. 总结
- 本文提出了 LLMOPT 框架,相较于传统方法,主要有以下特点
- 定义了通用的优化问题五要素表述作为数学建模形式。作者认为这种通用表达可以避免 LLM 过度简化问题,有效提取潜在约束。
- 相比而言,其他方法往往使用优化器中间文件或直接使用求解代码作为数学建模形式,我觉得其实也能起到类似的效果,所以对于基于学习的方法,该项优势可能不明显
- 对于基于提示的方法,这种方式可以看作某种提示聚焦,应该能提升性能
- 另外,通过引入五要素表述作为原始描述和求解代码之间的中间层,可以实现分层的错误纠正,这一点感觉是有用的
- 缺点在于构造数学建模标签人工成本高昂
- 引入 KTO 进一步实现人类偏好对齐,这个确实在早期的 Learning-based 类方法中没有,这一点我觉得还是合理的,因为 LLM-OR 这个任务相当困难,很难把 SFT 做到极致,而在数据质量低的情况下幻觉更容易产生,这时引入偏好对齐确实能有效提升性能。不过这个思路也可以进一步发展,因为 OR 问题的求解正确性是可以验证的,所以直接上 RL 或许更有效,参考 SIRL
- 定义了通用的优化问题五要素表述作为数学建模形式。作者认为这种通用表达可以避免 LLM 过度简化问题,有效提取潜在约束。