Wasserstein 距离简介
- 机器学习中我们常常要度量两个分布间的距离,常用的度量包括 KL 散度、JS 散度、总变差距离等。Wasserstein 距离又称推土机距离,是一种基于最优传输思想的度量,其从几何角度衡量一个分布“变形”为另一个分布所需的最小代价
1. Wasserstein 距离的定义
-
Wasserstein 距离:记紧空间 上的所有概率分布组成的空间为 ,设分布 ,随机变量 分布服从分布 ,设 表示随机向量 的所有联合分布,即任意联合分布 的边缘分布为 ,Wasserstein 距离定义为 -
直观来看,Wasserstein 距离就是在所有把分布变为 的联合分布(搬运方案)中,期望搬运代价的最小值
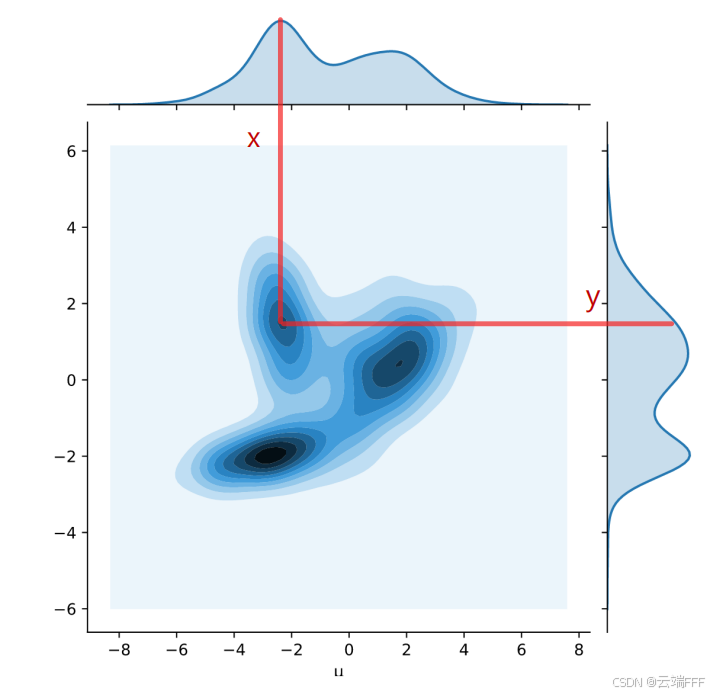
- 如图所示,任意联合分布 可以看作把分布 转换为分布 的一种方式。联合分布上任意一点 可以看作将来自 的概率质量的一部分从位置 搬运到 的位置 的方式,即图中红色线
- 积分可以理解为 “按照分配方案 把分布 搬运成分布 所需的平均搬运成本,其中从 到 的 “搬运” 代价为 ,被搬运的概率质量为
- 下确界符号 表示在所有可能的搬运方案里选出那个搬运成本最小的
- 是距离范数的指数,计算平均后还要开 次方,保证距离的量纲和原变量一致
-
下面给出一些例子
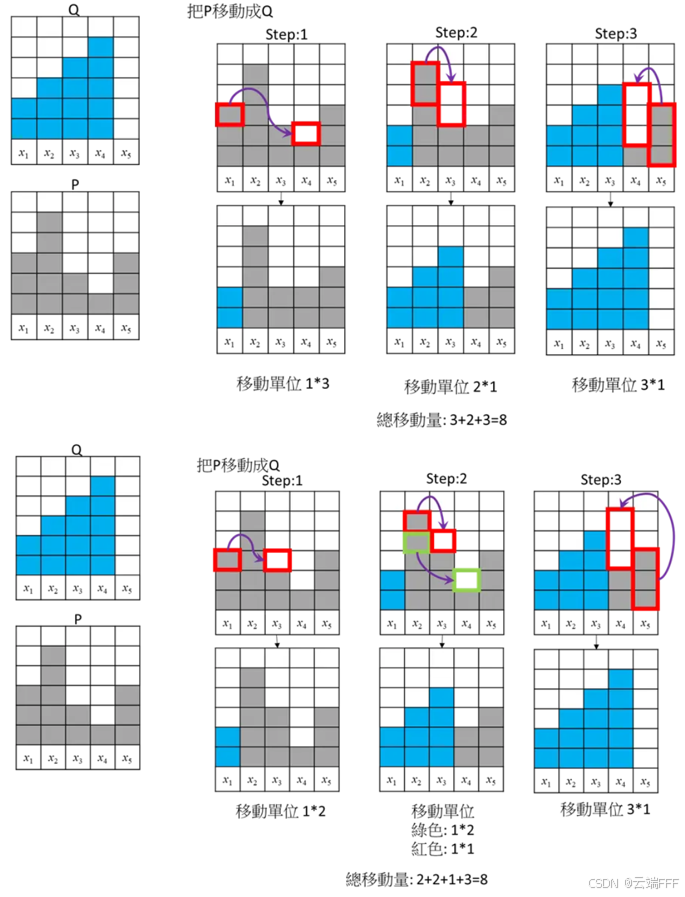
- 一维离散分布例子:假设相邻两列的距离(搬运代价)为1,图中给出的两种搬运方案代价都最小,加权移动总量为 8,除以格子数量 14(把 P,Q转换为概率分布),Wasserstein 距离为 4/7
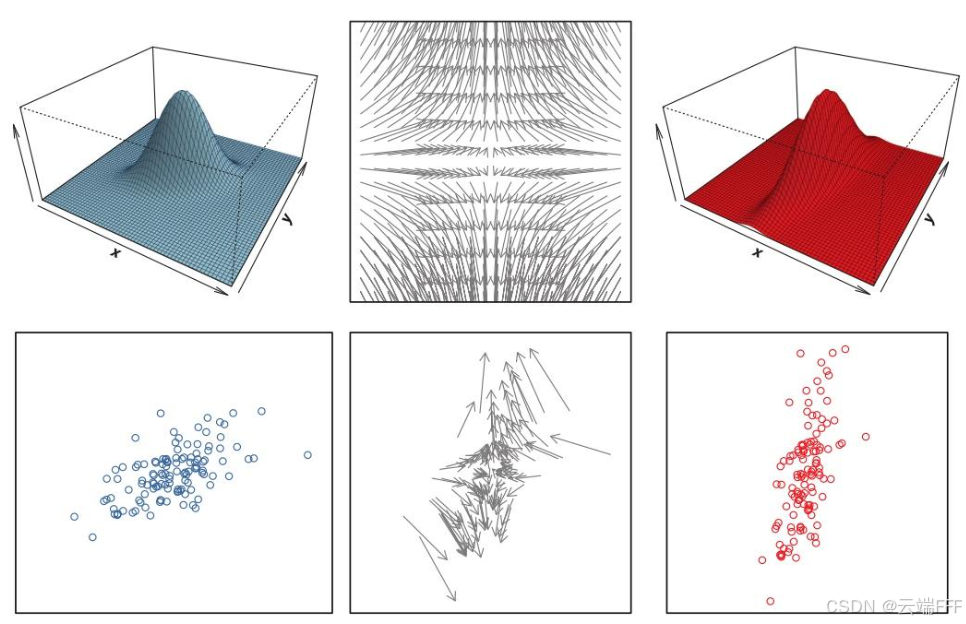
- 二维连续分布例子:按中间的灰色箭头移动每个点对应的概率密度,可以将蓝色分布转换为红色分布,Wasserstein 距离可以理解为最小化这些箭头的平均平方长度
2. Wasserstein 距离的优点
2.1 可处理支撑集不重叠的情况
-
KL 散度、JS 散度、总变差距离等分布间距离度量大都需要分布间具有重叠的支撑集,当两个分布的概率非零区域完全不重叠时,这些度量会变为固定值或无穷值,导致度量失效,难以反映实际差异
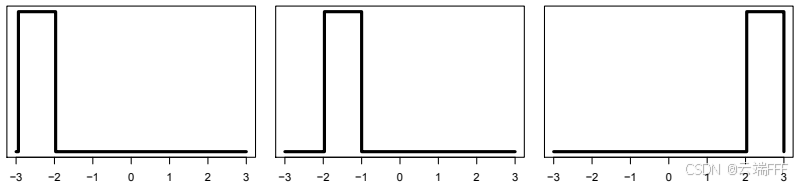
如图例所示,以上三个分布支撑集都不重叠,大部分度量会认为它们两两之间距离相同,但直观来看 距离 比 距离 更近
-
Wasserstein 距离从几何角度衡量一个分布“变形”为另一个分布所需的最小代价,因而可以有效处理支撑集(概率非0区域)不重叠的情况
2.2 Wasserstein 平均维持了原始分布的形态特征
-
给定一组分布 ,有时我们想找到一个平均分布 来代表它们。下图给出了 50 个圆形二维分布,它们的定义域都是 和 围成的单位方格内,概率在圆形支撑集上均匀分布
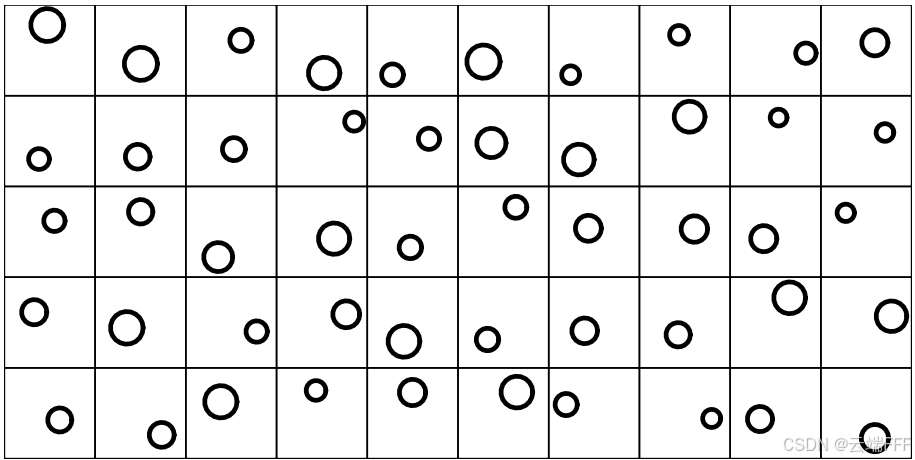
基于 Wasserstein 距离计算代表这 50 个分布的平均分布,可以更好地维持原始分布的形态特征
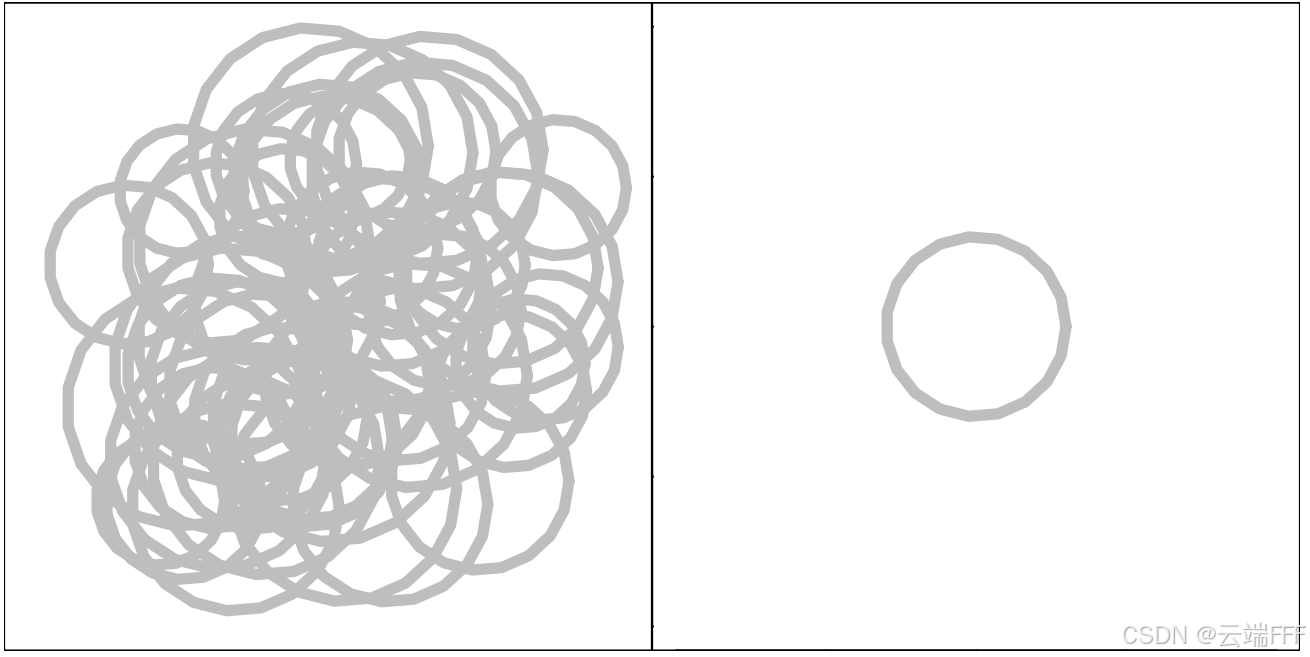
- 欧式平均(左):直接把概率平均分配到所有分布的支撑集上,对密度值取算术平均
- Wasserstein 平均(右):找一个分布,使得它到各个样本分布的 “最优搬运代价” 之和最小
- 欧式平均(左):直接把概率平均分配到所有分布的支撑集上,对密度值取算术平均
-
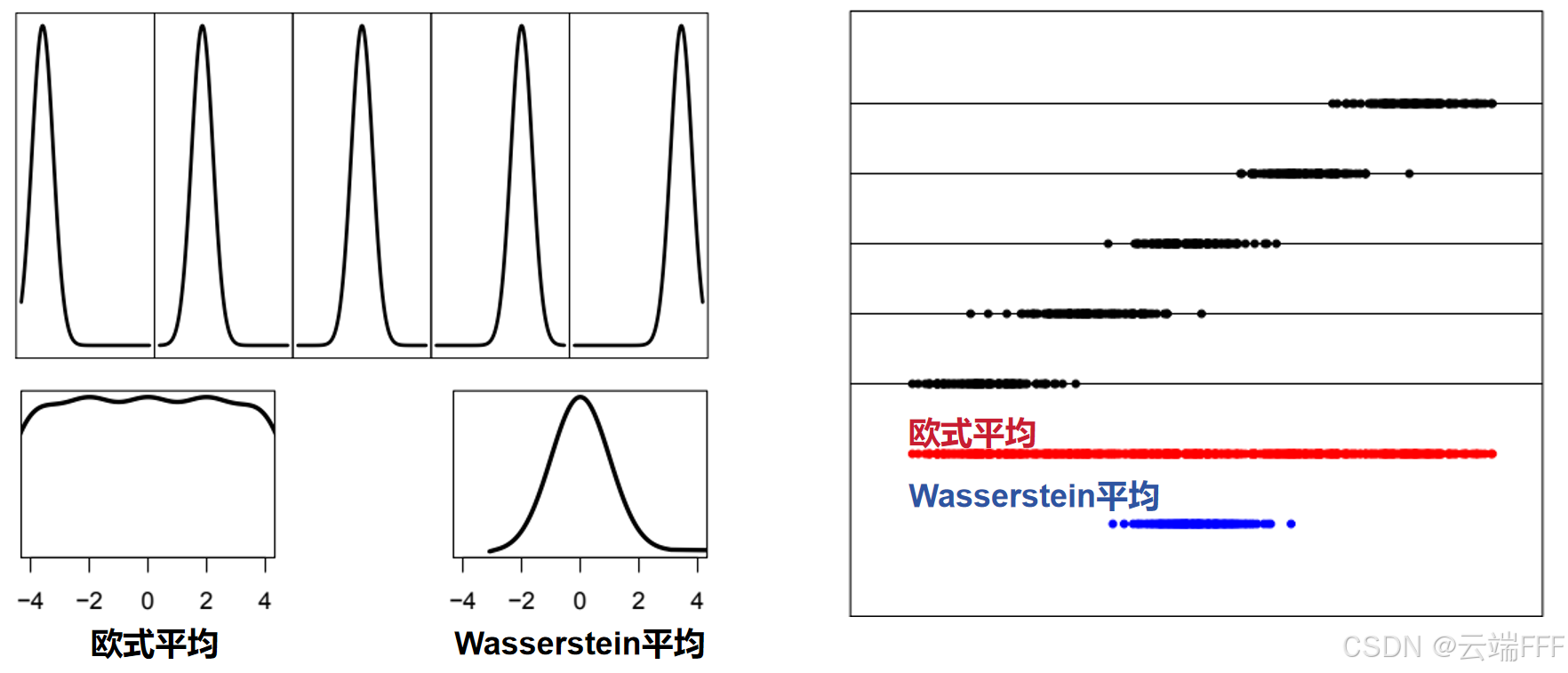
从某种程度上来说,Wasserstein 平均实际上是在进行分位数的转换和平均,以下显示了更多例子
2.3 Wasserstein 距离反映了分布的转化过程
- 使用 KL 散度等方式度量分布 间差距时,我们仅得到一个数字。使用 Wasserstein距离度量时,我们不但得到数字,还得到了一张图,展示了如何移动的概率质量来将其变形为
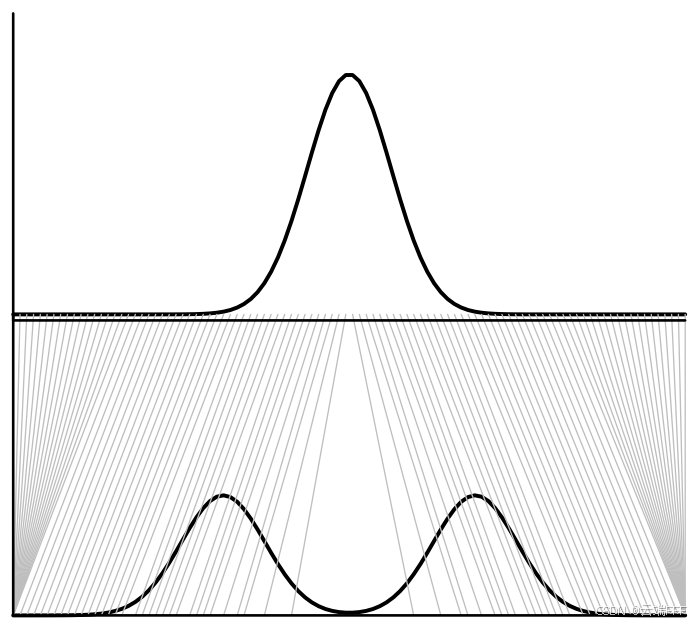
- 第一节中的二维连续例子也体现了这种能力
2.4 基于 Wasserstein 距离定义测地线可在变换过程中保存分布的形态结构
-
有时我们想看清从分布 变换为 的过程,也就是说在两个分布之间构造一个某种距离度量下的最短路径,沿着它走就能从原始分布变化为目标分布,这种路径需通过 “测地线” 进行构造
测地线Geodesics本质是一个从区间到中间分布集合的映射 ,满足 ,形成过程分布集合 。给定分布间距度量 ,任意两个相邻分布间距离为 ,测地线的总长度定义为路径无限细分时的相邻分布间距之和其中上确界 表示无限细分,测地线是能够使最小化的映射
-
测地线是分布空间中的 “直线”(最短),满足线性关系,在欧式空间中直接插值就能得到测地线,即令
它对应的距离度量是相应欧式空间中的距离度量,比如 或 范数。这种测地线构造方式和 2.2 节具有相同问题,不同位置的概率质量直接叠加,导致“混合”、“模糊”、“重影”,无法保持分布的形态结构和空间连续性,如下所示

-
在 Wasserstein 框架下,我们有最优传输映射
所以以 Wasserstein 度量作为距离度量的测地线,可以理解为在最优传输过程中进行插值,即
由于它不是在密度函数上插值,而是在 “概率质量的流动” 层面定义路径,每个概率质量微元沿最优方向运动,所以形状不会被混合或模糊化,如下所示
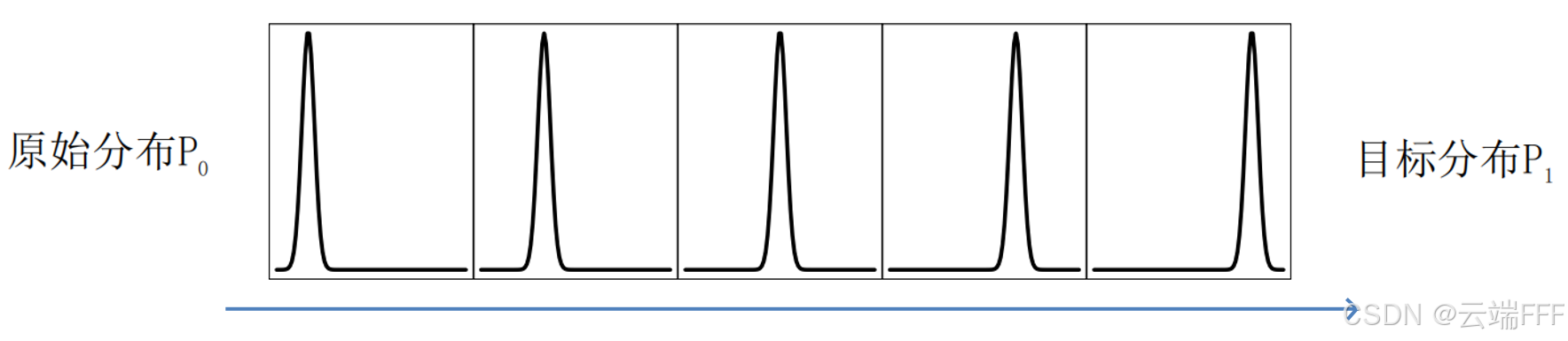
-
下面给出一个更直观的例子,把字母 J 的图像变成 V 的图像,基于 Wasserstein 距离定义测地线可在连续的变化过程中保存结构

3. 一维 Wasserstein 距离
3.1 一维 Wasserstein 距离可通过累积分布函数(CDF)计算
-
根据定义,Wasserstein 距离涉及一个下确界的优化问题
这个优化在高维很复杂,但在一维情况下有一个重大简化:最优传输映射是单调递增的,这意味着从 到 的最优传输可以如下计算
其中 表示累积分布函数(CDF), 表示分位数函数(quantile function),一维 Wasserstein 距离可以如下计算
- 每一个分位数点 对应一小块概率质量 , 分布的 分位点 和 给出了这小块质量在两个分布间的位置
- 这两个分位点的距离 代表把小块概率质量 从 搬运到 的代价
- 对 积分就得到总代价
-
因此,只要知道两个一维分布的分位数函数,就能通过积分或数值求和计算出 Wasserstein 距离。直观上看,就是从左到右比较两个分布的累积概率质量,把两个分布的质量“从左到右”单调地匹配起来
用第 1 节的一维离散例子进行说明,首先给出原始分布和目标分布
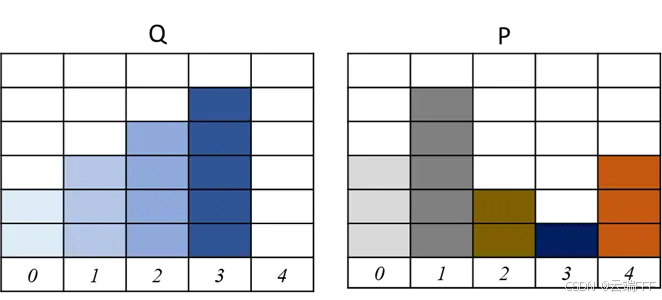
计算两个分布的 CDF
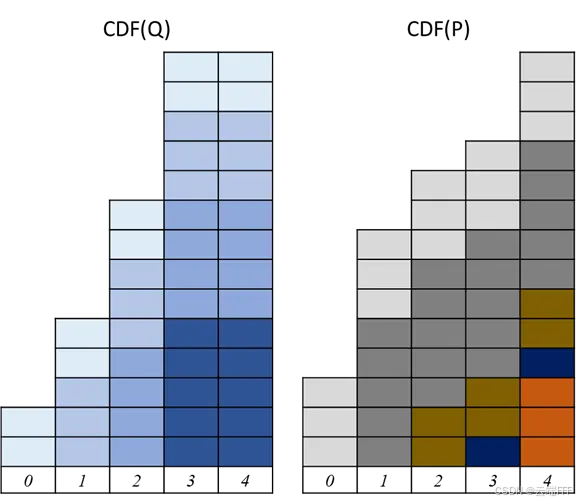
计算 Wasserstein 距离(除以总方格数 14 变为概率)
3.2 一维 Wasserstein 距离和 CRPS 损失的等价性
3.2.1 学习直方图分布
- 考虑回归问题,有时我们希望模型不仅能输出一个点回归值,还能给出分布形状。为此可以先将数值归一化到指定区间上,再将其划分为 个 bin,假设模型输出一个在区间上离散化的概率分布(直方图分布)
真实标签是一个确定性数值 ,它会落在某个 bin 中
- 解决这个问题的一个直观思路是将其看作分类问题,为 落入的 bin 构造 one-hot 标签,再用交叉熵损失优化。这种方式虽然能进行学习,但由于 CE loss 缺少数值敏感性,预测偏一格和偏十格损失一样大,最后学出的分布形状往往不平滑
3.2.2 CRPS 损失
- 使用
CRPS(Continuous Ranked Probability Score)损失训练直方图分布使用了回归思想,该损失可以度量预测分布与真实 CDF 的整体差距,设模型预测分布为 ,CDF 为 ,真实标签为 ,定义如下- 是模型预测真实标签 的概率
- 是样本对应的真实 CDF(阶跃函数)
- 用二者之差的平方在全域上的积分衡量预测分布与真实点分布的差距
- CRPS 的离散版本直接适用于优化直方图分布,这也是实现中最常用的版本。这里我们假设数值区间离散为 个有序的 bin:,模型预测 CDF 记为 。设真实值 落在第 个 bin 中,真实 CDF 为 ,离散 CRPS 定义为
3.2.3 CRPS 和 Wasserstein 距离
- 从 Wasserstein 距离角度分析训练任务,对于每个训练样本,模型预测分布 ,对应CDF 和对应的分位数函数为 ,真实分布 是由样本决定的在 处取概率为 1 的狄利克雷函数,其 CDF 和对应的分位数函数为
带入 Wasserstein 距离定义有()
从直觉上看,真实分布 的所有概率质量都堆在一点上,要把预测分布的质量 “搬运” 到这一点,成本就是预测值到的绝对距离的期望
- 为分析 CRPS loss,要引用一个关于CDF差平方的积分恒等式 Gneiting, T., & Raftery, A. E. (2007).
把 带入,
注意到 CRPS loss 和 距离只差了一个 ,这一项可以看作对模型分布自身的内部散度的度量,直觉上
- 衡量模型分布质量与目标单点分布的总体偏移量
- CRPS 不希望模型只通过 “拉宽分布” 来掩盖误差(这会增加不确定性但降低平均偏移),减去 在鼓励模型接近 分布的同时保持集中(sharpness)
- 综上,当真实分布非常锐利或为点分布时(比如对数学计算结果进行回归),CRPS 和 Wasserstein 距离等价;当真实分布 有方差时,CRPS 比 Wasserstein 更 “保守”
3.2.4 小结
- 针对直方图分布学习,对比 CE loss 和 CRPS loss
CE CRPS 基本思想 最大化真 bin 的概率(分类思维) 度量预测分布与真实 CDF 的整体差距(回归思维) 标签形式 one-hot 向量 阶跃 CDF 损失形态 距离度量 KL散度(非对称) 一维Wasserstein距离的变体(对称且连续) 数值敏感性 不敏感,预测偏一格和偏十格损失一样大 敏感,预测离得越远惩罚越大 输出解释 “分类概率” “概率预测的累积分布” - 注意到 CRPS 的一个重大优势是其具备数值敏感性,因此在 LLM 数值回归论文 NTL 中得到应用