论文理解 【LLM-RL】—— Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model
- 首发链接:论文理解 【LLM-RL】—— Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model
- 文章链接:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
- 发表:NIPS2025 best paper
- 领域:LLM RL
- 主页:Limit of RLVR
- 一句话总结:本文系统评估了多种 RLVR 方法对大模型推理边界的影响,发现它们主要是在基座模型已有推理路径上提高采样效率,而并未创造新的推理能力,且往往缩窄了推理覆盖范围,因此呼吁在探索策略、数据与反馈设计上发展新的 RL 范式
- 摘要:带有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)近期在提升大语言模型(LLMs)的推理表现方面取得了显著成功,尤其是在数学和编程任务上。普遍的看法是:类似于传统强化学习帮助智能体探索并学习新策略,RLVR也能让LLMs持续自我改进,从而获得超出对应基座模型能力范围的全新推理能力。本文对当前 RLVR 的真实状态进行了审慎反思:我们在多个模型族、RL 算法以及数学 / 代码 / 视觉推理基准上,系统性地探测 RLVR 训练后 LLM 的推理能力边界,并以大 k 的 pass@k 作为评价指标。虽然 RLVR 确实提升了向正确推理路径采样的效率,但我们惊讶地发现,当前训练几乎不会诱导出根本性的新的推理模式。我们观察到:在较小 k(如 k=1)时,RLVR 模型优于其基座模型;但当 k 较大时,基座模型反而获得更高的 pass@k 分数。此外,我们还发现,随着 RLVR 训练的推进,LLM 的推理能力边界往往在逐步收缩。进一步的覆盖率和困惑度分析表明,RLVR 模型生成的推理路径,其实已经包含在基座模型的采样分布之中,这暗示它们的推理能力来源于并受限于基座模型。从这个角度,将基座模型视为上界,我们的定量分析显示:六种流行的 RLVR 算法在表现上相差不大,且都远未达到充分挖掘基座模型潜力的最优状态。相对地,我们发现蒸馏可以从教师模型引入新的推理模式,真正扩展学生模型的推理能力。综合来看,我们的研究表明,当前 RLVR 方法尚未真正发挥强化学习在诱导“全新推理能力”方面的潜力。这凸显了改进 RL 范式的必要性,例如更高效的探索机制、更精心与大规模的数据策划、更细粒度的过程信号以及多轮智能体交互等方向,以解锁这一潜力
1. 背景
1.1 RLVR
大规模的带可验证奖励的强化学习RLVR是在 “有自动可验证答案” 的任务上,对已训练大模型进行大规模 RL 微调的范式。和 RLHF 使用单独训练的 Reward Mode 提供奖励不同,RLVR 的奖励是自动算出来的,比如数学题判断最终答案对不对、代码题跑单元测试是否通过等,这样就能低成本提供准确反馈形式化地讲:设有 LLM ,在 prompt 的条件下生成 token 序列 。一个确定性的验证器 返回一个二值奖励:,且当且仅当模型的最终答案完全正确时 。通常还可以额外加入一个 format reward,以鼓励模型在输出中显式地将推理过程与最终答案分开。强化学习的目标是学习一个策略,以最大化期望奖励:
RLVR 形式上是一个标准的 RL 框架:模型生成完整回答,判别器/验证器给一个 0/1 奖励(正确 / 错误),然后 PPO、GRPO、Reinforce++ 等各种 LLM-RL 算法来更新策略
- RLVR 的起点可以是基座模型也可以是 sft 模型,本文作者实验中对数学任务使用 Zero RL Training,对代码与视觉推理任务基于 sft 模型进行 RL 训练:
- 从基座模型开始:不进行任何 sft 监督微调,直接在基座模型上应用强化学习,这种设定被称为
Zero RL Training。其能最好地分析 RL 的效应,但通常只在数学问题上表现比较稳定 - 从 sft 模型开始:起始 base model 已经过预训练(有时会先做 CoT 微调)。由于 zero-RL 训练稳定性较差,在代码与视觉推理任务中,开源工作通常使用指令微调后的模型作为起点
- 从基座模型开始:不进行任何 sft 监督微调,直接在基座模型上应用强化学习,这种设定被称为
- 从 openai-o1、deepseek-r1 等 RL-based 推理模型发布以来,LLM 在数学、代码等 “有标准答案” 的推理任务上进步很快,研究人员普遍认为这是得益于 RLVR
- 在传统 RL 领域,强化学习可以通过自我博弈和探索,自己发现全新的策略,甚至超过人类
- 以此类比,RLVR 被视为一种让 LLM “持续自我进化” 的路径,社区希望 RLVR 也能让 LLM 自己发明新的推理模式(比如更系统的枚举、自反思、多轮修正等),超越原本的基座模型
1.2 度量指标
- 作者使用 Pass@k 指标作为 LLM 推理能力边界的度量。该指标原本是代码生成领域的常用评估指标,作者将其推广到所有可验证奖励任务上。具体而言:给定一道题目,从模型中采样 个输出,若其中至少有一个通过验证,则该题的 pass@k 取值为 1,否则为 0。对整个数据集取平均后的 pass@k 值就反映了测试集中模型能在次尝试内能够解决的题目的比例,从而对 LLM 的推理能力覆盖范围给出了一种严格的评估
在题目数、样本数都有限的情况下,直接计算 pass@k 的方差会很大,作者在此采用了一种低方差评估技巧:对每题 先抽 个样本、数出其中正确个数 ,再用组合公式 来得到这一题的 pass@k 概率,这样得到的 pass@k 无偏估计是
这种估计方法把 “随机选哪 k 个样本” 的那部分噪声给消掉了,相当于做了一次 Rao–Blackwell 化,所以方差一定更小或相等。直观地看这一项:
- :从这 n 个样本里选 k 个的方法数
- :只从“错误的样本”里选 k 个的方法数
- :选出的 个全部错误的概率
- :这 个里至少有一个正确的的概率,即该题在 次尝试内能被解出的概率
实验中,作者使用一系列从小到大的 值来分析 RLVR 的影响,从而形成一条 pass@k 曲线。在每条 pass@k 曲线里,选取最右边最大的 当成 ,然后计算每个 值对应的 Pass@k 指标
- 随着重复求解次数 提升,模型偶然猜对答案的概率会上升,可能导致 Pass@k 指标可靠性下降,因此需要引入验证手段判断模型到底是猜对还是算对的
- 对于代码任务,编译器和预先设定的单元测试可以充当验证器,此时 pass@k 能够较为准确地反映模型是否真正解决了问题
- 对于数学任务,随着 增大,“猜对” 的问题会更加突出:模型可能给出错误的 CoT,但偶然得到正确的最终答案,为此作者对一部分模型输出进行了人工检查,以验证 CoT 的正确性
2. 实验结果
-
作为一篇实证分析类工作,本文在数学、代码生成和视觉推理三个当前主流领域中,通过大规模实验对基座模型和 RLVR 模型进行了全面评估,实验设定如下
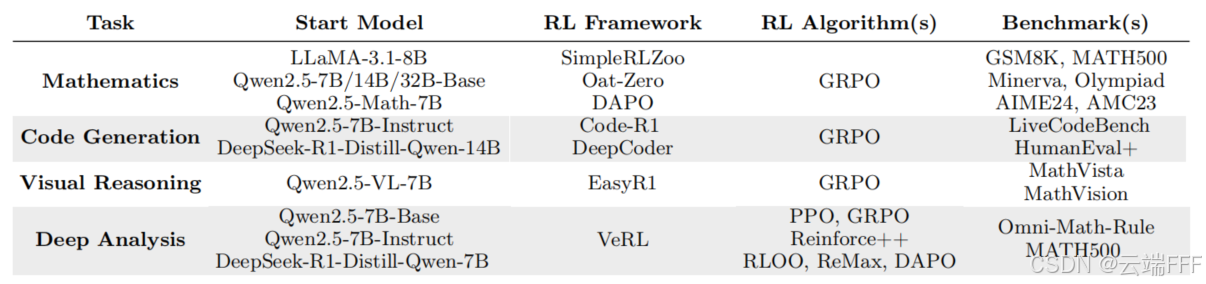
- 在评估基座模型和 RLVR 模型时,作者使用与 RLVR 训练中相同的 zero-shot 提示,或使用基准数据集提供的默认提示,以保证两类模型在设置上的一致性
基座模型评估的常见做法是在 prompt 中加入 few-shot 示例来引导输出。但为了确保对比公平且无偏,作者刻意不对基座模型使用 few-shot 提示,这种无引导情况下基座模型常给出格式不规范或无意义的回答,但在足够多的采样次数下,其仍能够生成格式正确的输出,并成功解决复杂问题
- 采样模型答案时,统一采用温度 0.6、top-p 为 0.95,并允许最多生成 16,384 个 token
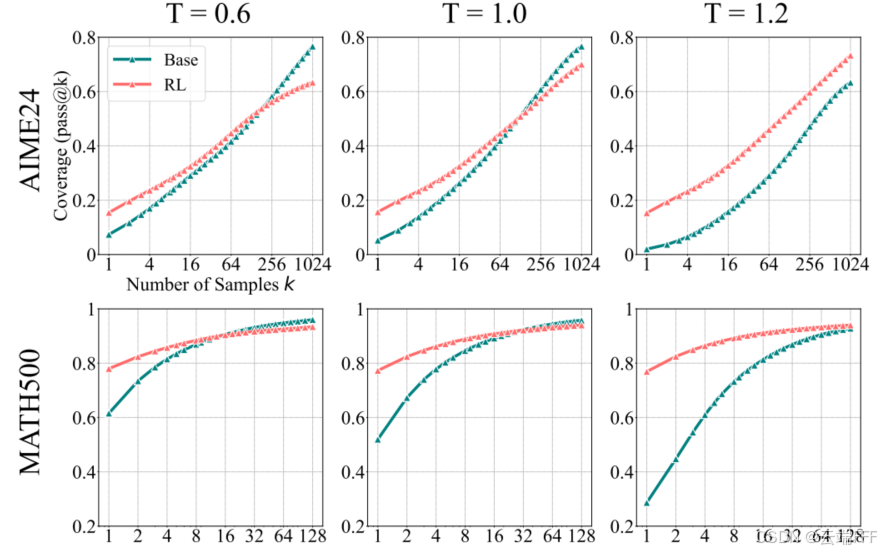
如图所示, 时,由于生成随机性增大,基座模型的性能会下降。主实验中采用 的温度参数可以让两个模型都展现出最佳推理性能
- 在评估基座模型和 RLVR 模型时,作者使用与 RLVR 训练中相同的 zero-shot 提示,或使用基准数据集提供的默认提示,以保证两类模型在设置上的一致性
2.1 数学推理
- 实验设置
- 模型给出最终答案的同时要生成完整的 CoT 推理过程
- 所有模型在 GSM8K 和 MATH 训练集上使用 GRPO 算法进行 Zero-RL Training
- 奖励仅基于答案正确性,不包含任何与输出格式相关的奖励
- 实验结论:
- RLVR 提高了数学推理任务正确样本概率,但降低可解问题覆盖率,此结论对于 Oat-Zero 和 DAPO 等 RL 算法仍然成立
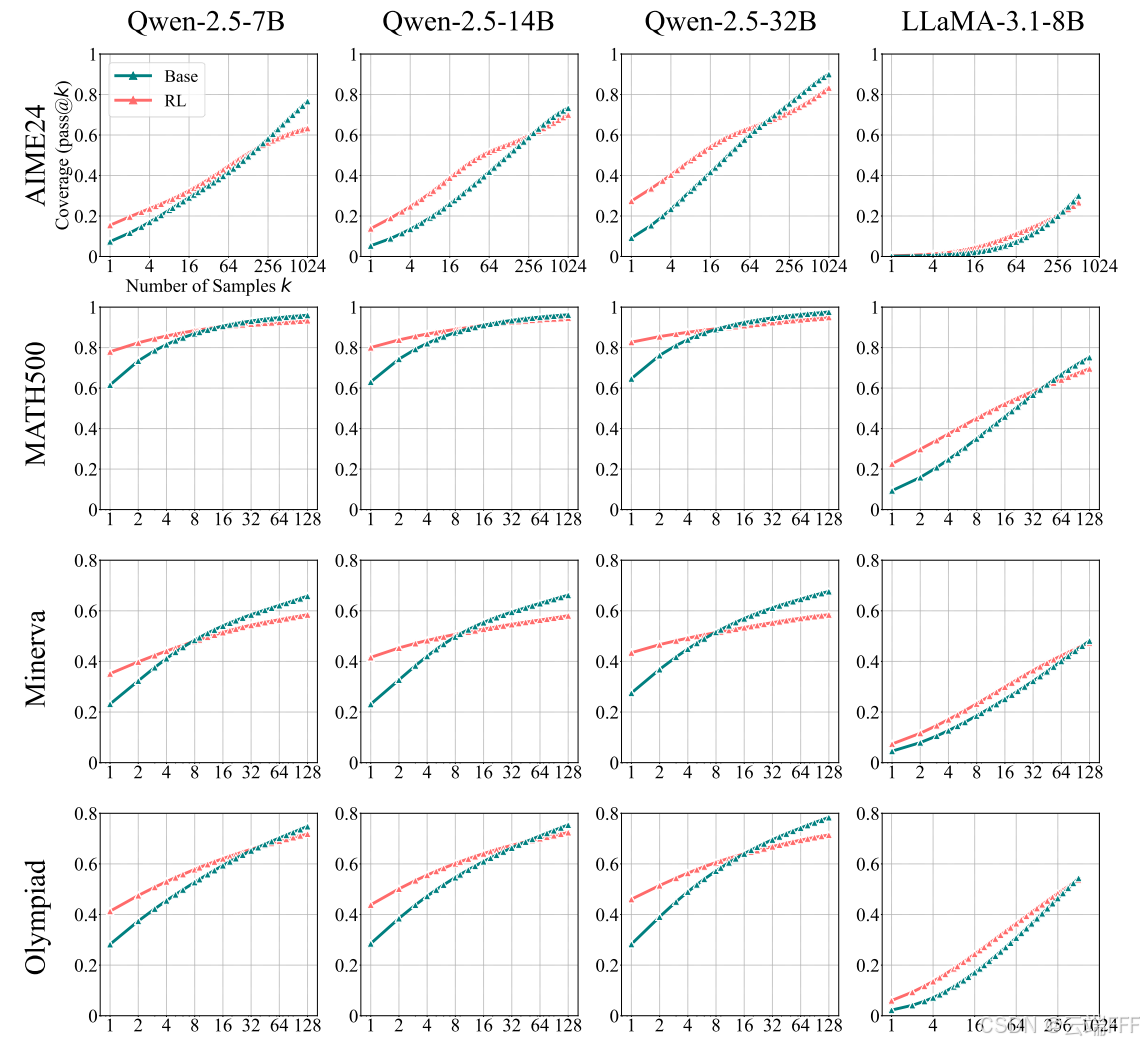
- 当 较小时,RLVR 模型优于其基座模型。这与“RL 能提升性能”的常见观察相一致,说明 RLVR 使模型在采样中显著更容易得到正确回答
- 随着 增大,基座模型会在所有基准上持续追赶并最终超过 RLVR 模型,表明基座模型具有更广的可解问题覆盖范围
- 即使针对最困难的数学问题,在多次采样的情况下基座模型也能给出正确的 CoT,并表现出反思行为,说明基座模型本身就具备较强推理能力,能通过采样获得有效的 CoT 推理路径来解决困难问题
为了排除模型猜对答案导致性能评估失真,作者对 GSM8K 和 AIME24 数据集中平均准确率在 0% 到 5% 之间的困难问题进行人工检查。考虑指标:“包含至少一个正确 CoT 的题目数量/答对总数”
- 基座模型:GSM8K 上为 24/25,AIME24 上为 5/7
- RLVR 模型:GSM8K 上为 23/25,AIME24 上为 4/6
- RLVR 提高了数学推理任务正确样本概率,但降低可解问题覆盖率,此结论对于 Oat-Zero 和 DAPO 等 RL 算法仍然成立
2.2 代码生成
- 实验设置
- 模型与基座:使用开源 RLVR 代码模型 CodeR1-Zero-Qwen2.5-7B 及其基座 Qwen2.5-7B-Instruct-1M;外加当前最强开源 RLVR 代码模型 LLM DeepCoder-14B 及其基座 DeepSeek-R1-Distill-Qwen-14B
- 训练配置:CodeR1-Zero-Qwen2.5-7B 在 12K 条 LeetCode 与 TACO 样本上进行 832 步 Zero-RL 训练,起始模型为 Qwen2.5-7B-Instruct-1M;DeepCoder-14B 是基于 DeepSeek-R1-Distill-Qwen-14B 的 RLVR 训练模型,论文直接使用其开源权重进行评测
- 测评基准:模型的响应最大长度均设为 32k。对 CodeR1-Zero 及其基座,基准包括 LiveCodeBench v5、HumanEval 和 MBPP;对 DeepCoder-14B 及其基座,由于计算成本高,仅在 LiveCodeBench v5 上测评
- CoT 质检:代码部分没有像数学那样的人工 CoT 质检段落,作者是通过 “单元测试几乎无法靠猜中” 这一点来保证 pass@k 的可信度的
- 实验结论:和数学任务高度一致,RLVR 提升了小值的平均性能,但大 值时基座模型覆盖更广
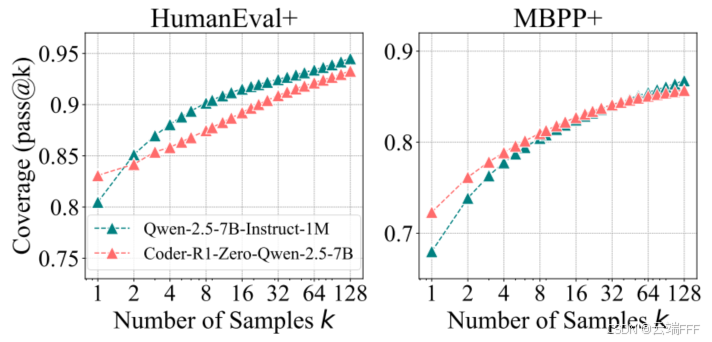
2.3 视觉推理
- 实验设置:
- 任务形式:选取带视觉上下文的数学题作为代表性视觉推理任务,模型需要同时理解图像与文本输入,完成复杂推理
- 模型与训练:使用 EasyR1 框架,在 Geometry3K 数据集上对 Qwen2.5-VL-7B 进行 RLVR 训练
- 评测基准:在 MathVista-TestMini(去除多选题后的子集)和 MathVision-TestMini(同样移除多选题)这两个视觉数学基准上评估基座与 RLVR 模型的视觉推理能力
- 实验结论:
-
和数学、代码任务高度一致,RLVR 提升了小值的平均性能,但大 值时基座模型覆盖更广
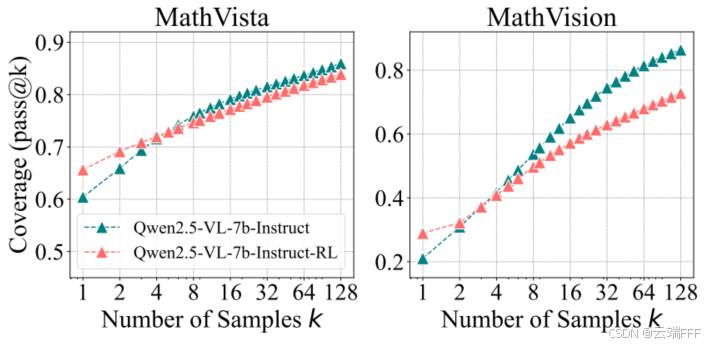
-
对于最困难的视觉推理问题,基座模型与 RLVR 模型都能在多次采样下给出至少一个正确 CoT,验证了 CoT 在视觉场景中的有效性
同样对视觉任务中“最具挑战性”的子集进行人工检查,发现对于基座模型和 RLVR 模型,在这 8 道最难题目中,都有 7 道至少包含一个正确的 CoT
-
3. 结果分析
3.1 基座模型中已存在推理路径
-
第 2 节的实验表明,基座模型相比 RLVR 模型覆盖了更宽的可解问题范围。进一步分析 RL 训练前后准确率分布和可解问题覆盖率的差异,发现 RLVR 在平均分上的提升并非源于解决了新的问题,而是来自于在原本就可由基座模型解出的那些问题上提高了采样效率
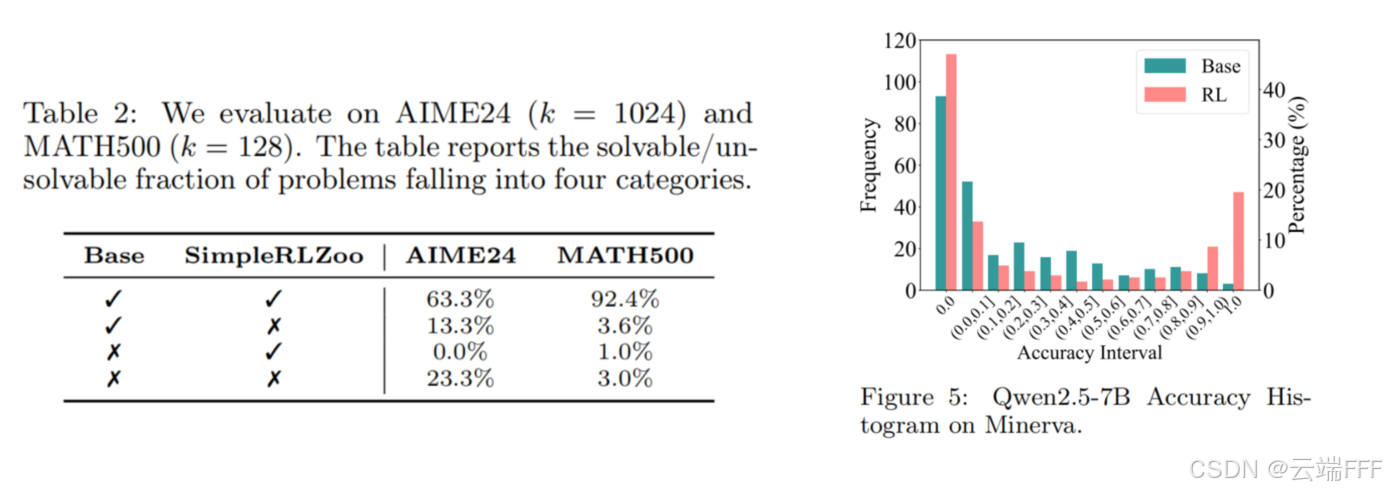
- 如图:RLVR 会提高接近 1.0 的高准确率区间的频次,并降低低准确率(例如 0.1、0.2)区间的频次
- 如图:RLVR 提升了准确率为 0 的区间频次,说明 RLVR 会带来更多 “完全解不出” 的问题
- 如表:基座模型可解而 RLVR 模型失败的问题很多;相反 RLVR 可解而基座模型失败的情况很少
-
这引出一个自然问题:RL 训练模型生成的所有推理路径,是否都已存在于其基座模型的输出分布之中。为此作者使用
困惑度perplexity这一度量进行分析给定模型 ,问题 和一个回答序列 ,
困惑度定义为该序列平均负对数似然的指数形式:它反映了在 prompt 条件下,模型对给定回答 的预测能力。困惑度越低模型生成该回答的可能性越高
作者从 AIME24 中随机抽取两个问题,分别使用 Qwen2.5-7B-Base 和 SimpleRL-Qwen2.5-7B-Base,为每个问题各生成 16 个回答,分别记为 ,同时让 OpenAI-o1 生成 8 个回答记为 ,分析基座模型和 RLVR 模型对不同回答的困惑度
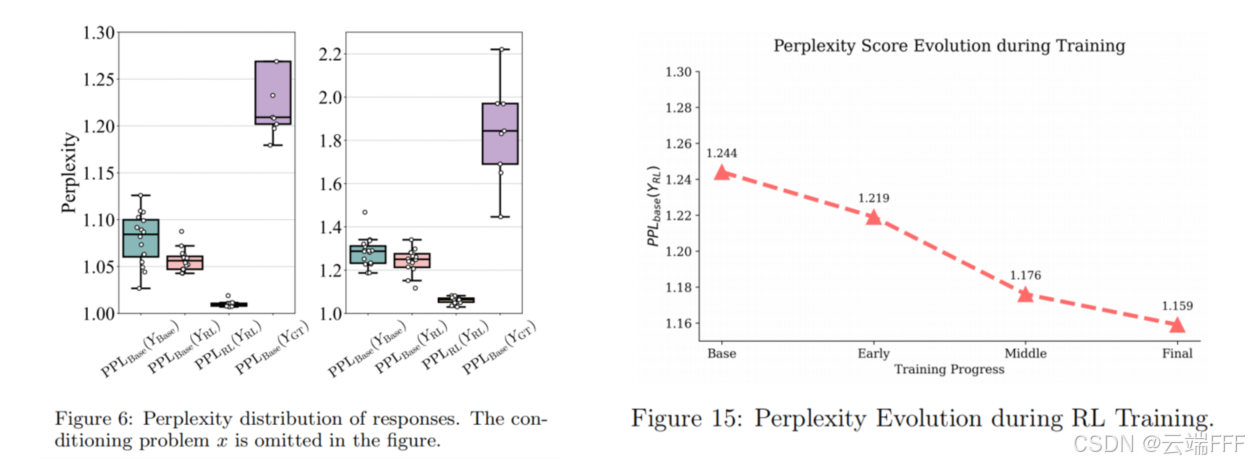
- 如左图所示,两个问题 的分布均与 分布中较低区间高度吻合,这表明 RL 训练模型的回答很大概率也是基座模型能够生成的
- 如右图所示, 会随着 RL 训练推进而逐渐降低,表明 RLVR 主要是在基座模型原有先验分布内“锐化”分布,而不是扩展到其之外
-
综上,RLVR 并未引入从根本上全新的推理能力,RL 后模型推理能力仍受制于基座模型能力上限
- RLVR 模型可解的题目也能被基座模型解出,平均分数的提升来自于在这些 “原本可解问题” 上的更高采样效率,而不是学习去解决新的问题
- RLVR 模型的推理覆盖范围往往相比其基座模型更窄
- RLVR 模型所利用的推理路径已经存在于基座模型的采样分布之中
3.2 蒸馏能扩展推理边界
- RL 之外,从更强的推理模型进行蒸馏也能提升小规模基座模型的推理能力。这一过程类似于 post-training 阶段的
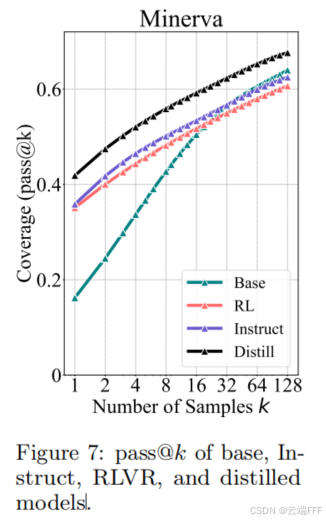
instruction-following fine-tuning:其训练数据不再是短的指令–回复对,而是由教师模型生成的长 CoT 推理轨迹 - 作者发现:从根本上受制于基座模型推理能力上限的 RL 不同,蒸馏可以从更强的教师模型中引入新的推理模式,从而超越基座模型的推理边界
考虑模型 DeepSeek-R1-Distill-Qwen-7B,它是将 DeepSeek-R1 蒸馏到 Qwen2.5-Math-7B 上得到的。作者将其与基座模型 Qwen2.5-Math-7B 及其 RL 训练版本 Qwen2.5-Math-7B-Oat-Zero 进行比较,并额外加入 Qwen2.5-Math-7B-Instruct 作为基线。注意到蒸馏模型的 pass@k 曲线在整个范围内都持续且显著地高于基座模型
3.3 不同 RL 算法的影响
- 根据实验,RL 的主要作用在于提升采样效率而非扩展模型的推理能力。作者提出
采样效率差距Sampling Efficiency Gap来量化对采样效率的提升,记作采样效率差距定义为 RLVR 模型 pass@1 与 基座模型 pass@k 之差(评估中取 )
- 作者在 了多种主流 RL 算法,发现各类现有 RL 方法在采样效率方面仍远未达到最优,要逼近上界可能需要全新的 RL 算法,甚至完全不同的范式
所有 RL 算法都在 VeRL 框架中重新实现以便公平比较,并且全部移除了 KL 约束。为评估 RLVR 在域内与域外的泛化表现,作者将 Omni-MATH 的可验证子集 Omni-MATH-Rule 拆分为训练集(2,000 个样本)和域内测试集(821 个样本),并使用 MATH500 作为域外基准
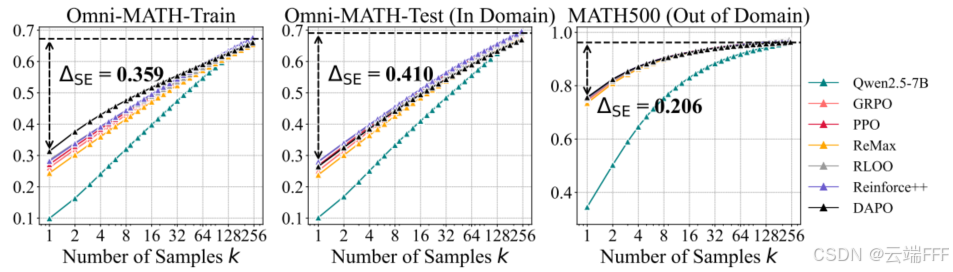
- 不同 RL 算法的 pass@1 和 pass@256 都仅有小幅差异,并不本质
- 始终高于40%,说明采样效率都很低
3.4 RL 训练本身的影响
-
渐近效应:随着 RL 训练的推进,训练集上的 pass@1 持续提升但 pass@256 会逐步下降,表明推理边界在不断收缩
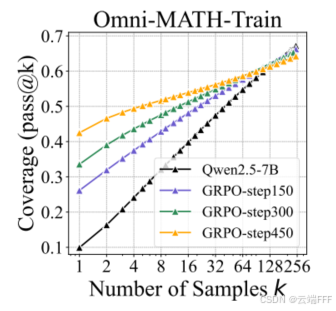
-
Rollout 数量 的影响:提升每个 prompt 生成的回答数量 ,可以扩大 RL 探索强度从而优化 pass@k,但 RL 模型最终仍会被基座模型超越
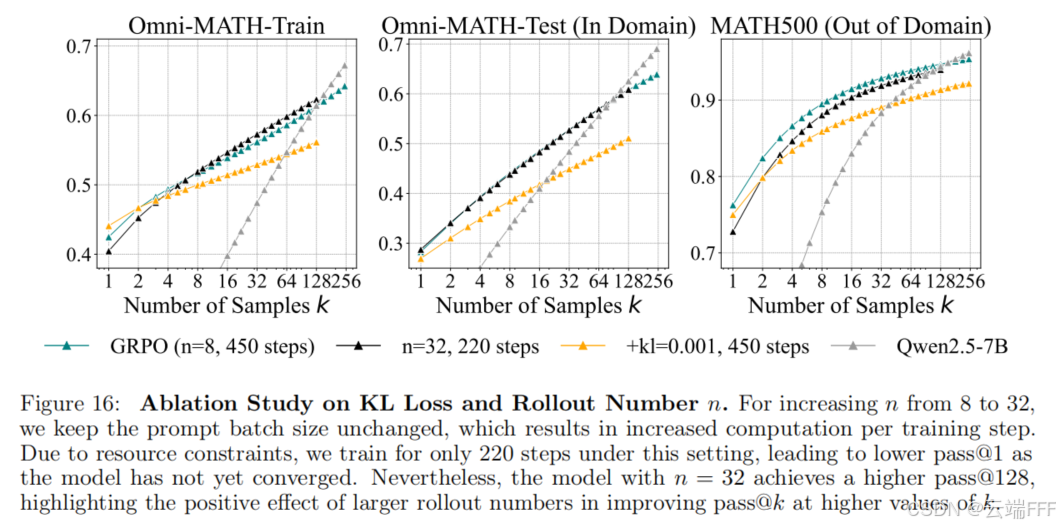
-
KL 损失的影响:一些 RL 方法会添加 KL loss 以控制 RL 模型和基座模型的偏移。发现引入 0.001 的 KL 正则项后模型在 pass@1 上与不带 KL 的 GRPO 相近,但 pass@128 明显更低
3.5 熵的影响
- 现有研究已经发现:随着 RL 训练进行,模型输出的熵通常会降低,导致输出多样性减少并使推理边界收缩。为考察这一因素,作者提高 RLVR 训练模型的生成温度,使其输出熵与基座模型在 时相匹配,发现熵的降低确实促成了推理边界的收缩,但单靠这一因素并不足以完全解释边界缩小的现象
RLVR 模型在更高温度下的 pass@k 略有提升,但在各个 pass@k 上仍然不及基座模型
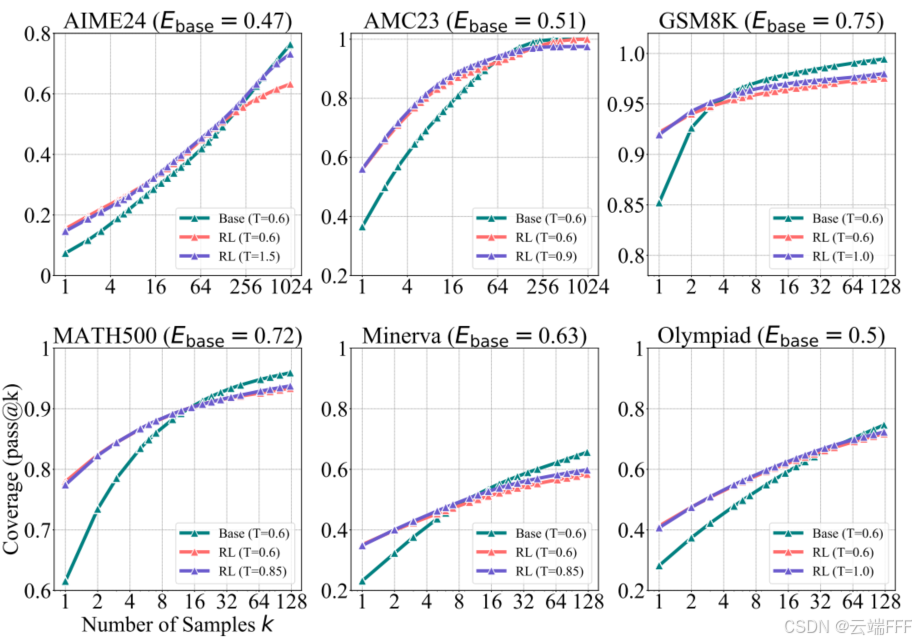
3.6 模型规模扩展的影响
-
模型规模扩展在当代大模型能力中起着核心作用。作者考察了模型规模增大时,上述结论是否仍然成立
-
由于多数大规模模型参数并未开源,作者使用 Magistral-Medium-2506 API 进行了一组初步实验。该模型以 Mistral-Medium-3-2505 作为起始模型,采用纯 RL 训练。Magistral-Medium 的表现与 DeepSeek-R1 相近,推理能力接近当前前沿水平。实验表明:即便对于当前能力很强、接近前沿的推理模型,结论依然成立
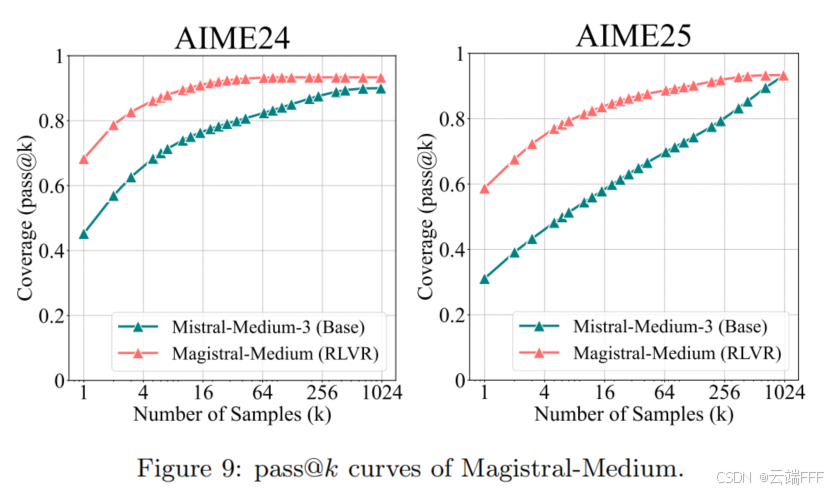
-
未来一个关键问题是:当有更多算力(例如预训练规模预算)专门投入 RL 训练时,这一趋势是否仍将持续
4. 总结与讨论
4.1 实验结论
- 基于数学推理、代码生成、视觉推理三类任务上,对多种 LLM-RL 算法的广泛实验,本文结论如下
- 当前 RLVR 模型的推理覆盖范围往往比其基座模型更窄,RLVR 训练并没有扩展,反而是缩小了可解问题上的推理范围
- 当前 RLVR 模型生成的推理路径已经存在于其基座模型中,RLVR 并未引入根本性的新的推理能力
- 当前各类 RLVR 算法之间的表现相似,距离最优状态仍有较大差距。具体而言,当前 RLVR 方法虽然提高了采样效率,但距离 “充分利用基座模型潜力” 的最优状态仍然相去甚远
- RLVR 与蒸馏在本质上是不同的。RLVR 通过更高效地采样高奖励输出来提升推理得分,但并没有引出新的推理能力,相比之下,蒸馏可以从更强的教师模型中迁移新的推理模式,蒸馏模型往往展现出超出基座模型的、更为扩展的推理范围
4.2 讨论分析
- 传统强化学习在控制任务上能够持续提升策略表现,而且没有显式的性能上界。作者认为这是两个关键差异导致的
- LLM 的动作空间相对于围棋或 Atari 游戏是指数级更大的,现有 RL 算法并不是为处理如此庞大的动作空间而设计的,如果从零开始训练,几乎不可能有效探索到奖励信号
- LLM-RLVR 从一个带有有用先验的预训练基座模型出发,这种预训练先验会引导 LLM 生成合理的响应,使策略能够获得正向的奖励反馈
- 然而,在 LLM 巨大的动作空间中,先验是一把“双刃剑”,由于响应采样是由预训练先验所引导,策略可能难以探索到超出该先验所提供的新推理模式
- 大多数通过朴素的逐 token 采样探索生成的响应,都被限制在基座模型的先验之内
- 任何偏离该先验的采样都极有可能产生无效或无意义的输出,从而带来负的结果奖励
- 从这一视角看,从一个 “蒸馏后的模型” 出发来训练 RL 模型,在一定程度上可能是一个有益的折中方案,因为蒸馏能够注入更优的先验
4.3 未来工作
- 综上,巨大动作空间中低效的探索机制和对二元结果奖励的依赖,可能是当前 RLVR 设置中所观察到局限性的根源。要从根本上解决这些挑战,若干方向值得进一步探索
- 高层抽象下的高效探索策略:促进发现超越先验的推理模式,及未见的知识结构
- 通过课程式数据扩展规模:课程学习首先从简单的子问题中获取 meta-skills,再逐步转向困难任务,这可能以层次化方式压缩探索空间,使 RLVR 能够获得有意义的奖励信号。近期的一些工作观察到了这类方法work的迹象,但要真正发挥潜力,仍然需要一个更为精心设计、大规模的数据–RL 迭代流水线,以确保对 meta-skills 的充分覆盖,及简单任务和困难任务之间恰当的层次关系的合理构建
- 过程奖励与细粒度信用分配:与纯粹的二元结果奖励相比,引入中间信号来引导推理轨迹,可能显著提升探索效率,并将探索过程引向更有前景的解题路径
- Agentic RL(具身 / 代理式 RL):当前的 RLVR 推理主要局限于单轮响应,然而有研究表明基于反馈的多轮迭代改进对于高质量推理至关重要。此外,现有方法同样缺乏主动获取新信息的能力,比如使用搜索工具或开展实验。一个多轮的 agentic RL 范式——具备与环境更加丰富的交互反馈——可能允许模型生成新的经验并从中学习