论文理解【LLM-OR】——【OptiTree】Hierarchical thoughts generation with tree search for LLM optimization model
- 首发链接:论文理解【LLM-OR】——【OptiTree】Hierarchical thoughts generation with tree search for LLM optimization model
- 文章链接:Optitree: Hierarchical thoughts generation with tree search for LLM optimization modeling
- 发表:NIPS 2025
- 领域:LLM OR
- 代码:MIRALab-USTC/OptiTree
- 一句话总结:使用 LLM 对运筹优化问题(OR Problem)建模时,传统固定步骤分解在复杂数学结构下准确率低,本文提出 OptiTree:基于“子问题层级建模树”的树搜索检索,自适应地将原问题分解为一串更简单的子问题,并递归整合各子问题的高层建模思路形成全局指导,从而显著提升建模准确率
- 摘要:优化建模是运筹学(OR)领域最关键的技术环节之一。现有工作普遍利用 LLM 实现建模过程的自动化,通过 Prompt 让其将任务分解为 "变量生成"、"约束条件设定" 和 "目标函数构建" 等步骤。然而,由于 OR 问题内在高度复杂的数学结构,标准的固定步骤分解方法往往难以达到理想性能。针对这一挑战,我们提出 OptiTree:一种新颖的树搜索方法,通过自适应地将复杂问题分解为更简单的子问题来增强对复杂问题的建模能力。具体而言,我们构建了一棵建模树,基于问题的层级化分类体系与复杂度来组织广泛的 OR 问题;树中的每个节点表示一个问题类别,并包含相关的高层建模思路。给定一个待建模的问题,我们递归地搜索该树以识别一系列更简单的子问题,并通过自适应整合层级思路来合成全局建模思路。实验表明,OptiTree 相比当前 SOTA 方法显著提升了建模准确率,在具有挑战性的基准上取得了超过 10% 的提升
1. 背景
1.1 运筹问题建模
- 本文研究复杂运筹学问题 (OR Problem) 的自动建模与编程,以减轻对人类专家的严重依赖。具体而言,这类问题要求输入一段自然语言描述的问题(如配送货、生产规划等问题),要求模型或系统完成运筹学建模,并生成问题求解代码。近期研究常借助 LLM 丰富的领域知识完成建模,主要存在两类方法:
- 基于提示的建模prompt-based modeling:通过为 GPT-4o 等大规模预训练 LLM 精心设计建模 Prompt 来工作,可以引入多智能体协作流程或蒙特卡洛树搜索等技术
- 基于微调的建模fine-tuned LLM modeling agents:通过构造大规模运筹学及建模知识对 LLM 进行微调,形成专用的建模语言模型,如 ORLM
- 本文聚焦于基于提示的方法,旨在充分发挥预训练 LLM 的推理能力。LLM 推理面对的主要挑战是消除幻觉,相关工作包括问题分解(如CoT/ToT)、引入存储实例化模版的建模思路缓存(如BoT)和引入外部知识(如RAG)等。本文方法 OptiTree 为每个子问题搜索相关的建模思路,并将其动态组合以生成全局建模思路
- OptiTree 类似 BoT/RAG,通过检索并复用高层
建模思路modeling thoughts来引导生成,但这些思路不是平铺存放,而是挂在按子问题关系组织的层级建模树上 - OptiTree 类似树搜索方法,但搜索的不是变量/约束/目标等模型组件,而是在建模树上搜索与输入问题匹配的
子问题路径(最大子问题),以确定应当复用/整合哪些建模思路
- OptiTree 类似 BoT/RAG,通过检索并复用高层
1.2 动机性观察
-
作者在 IndustryOR 数据集上对传统 prompt-based 方法进行了分析,该数据集被划分为 Easy, Medium, Hard 三类难度水平;传统方法通常基于 CoT,通过顺序完成 “优化变量生成”、“约束条件设定” 和 “目标函数构建” 等分解步骤实现问题建模
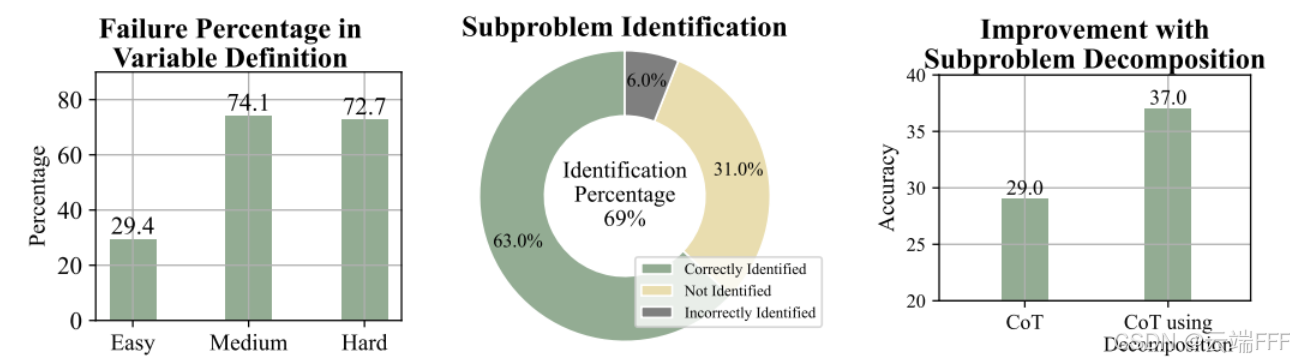
- 标准固定步骤分解方法在复杂任务上往往失效,主要问题在于无法准确识别变量:如左图所示,传统方法失败的主要原因在于变量定义错误
- 复杂问题中普遍存在子问题分解模式,且 LLM 的子问题识别准确率较高:作者先从运筹学教材中收集了 50 个标准 OR 问题及相应的真值建模。对每个来自 IndustryOR 的待建模的问题,让判断它是否包含这 50 个标准问题中的某个或某些作为子问题,若识别到子问题,则将该子问题对应的真值模型加入到用于优化建模的提示词中。如中图所示,LLM 为 69% 的问题识别出了子问题,其中超过 63% 的问题对应的子问题是正确的
例如给定自然语言描述为 “车辆从 depot 出发服务客户;每个客户访问一次;车辆有容量限制;此外每个客户还要求在时间窗内服务、含旅行时间/服务时间等”,这是一个 VRPTW 问题,它的子问题是 cvrp 或更一般的 vrp,从标准问题中找到子问题的 ground turth 建模加入 prompt,就能提升对该问题的建模准确性
- 引入朴素的子问题分解可以提升 LLM 建模质量:对 IndustryOR 中每个问题,首先用 LLM 从 50 个标准问题中选择一个合适的子问题,若识别到相关子问题,则在建模原问题前先提供该子问题的真值模型,并在其基础上继续建模原问题。如右图所示,基于子问题的建模能降低任务复杂度,并有潜力提升性能
-
基于上述观察,作者提出利用树搜索进行子问题分解,并利用子问题建模思路增强建模过程
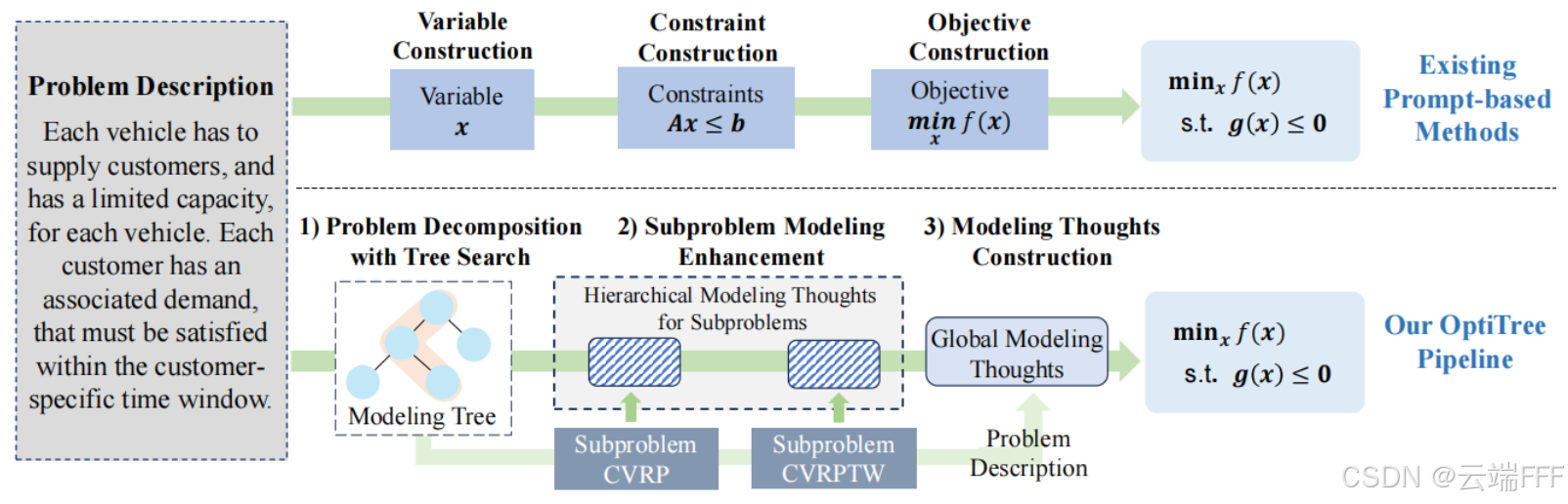
2. 本文方法
-
如下图所示,OptiTree 的核心思想包括
- 利用建模数据集构造一个层次化的树结构来组织建模知识,该结构刻画了不同问题中普遍存在的分解模式,并保存了各子问题的建模思路
- 对新问题进行建模时,使用树搜索高效检索分解子问题及其层次化建模思路,并自适应地整合这些思路,从而形成完整的全局建模思路
- 为保证可扩展性与可靠性,子问题与建模思路被动态管理,增强从建模树提炼更多分解模式与思路的能力,从而提升未见问题泛化性
2.1 子问题的定义与识别
- 作者通过问题建模定义子问题,给定一个 OR 问题 ,设其形式化表示为
其中 表示目标函数, 为决策变量, 表示第 个约束函数, 表示约束中的参数。假设决策变量可划分为两组 ,且目标与约束可分解为
若另一个 OR 问题 的优化模型具有如下形式,则称 是 的一个子问题
其中 为参数,且建模 (2) 可以视为建模(1)的一部分
直观上看,从原问题 中抽取部分决策变量 、仅与其相关的优化目标 和部分约束条件 ,就构成一个子问题
- 以上定义无法直接使用,因为实际任务中无法提前获取被建模问题的真实模型,需要仅通过自然语言描述来识别子问题。为避免 LLM 幻觉,作者通过引入
陈述思路(statement thoughts)将对比过程格式化,具体而言- 陈述思路是一组原子化的高层陈述 ,其中每个 概况一个与优化建模相关的特征或需求,它是由 LLM 根据 meta-prompt 生成的
- 若在语义上被 所包含(记为 ),则认为 是 的子问题,记为(记为 )
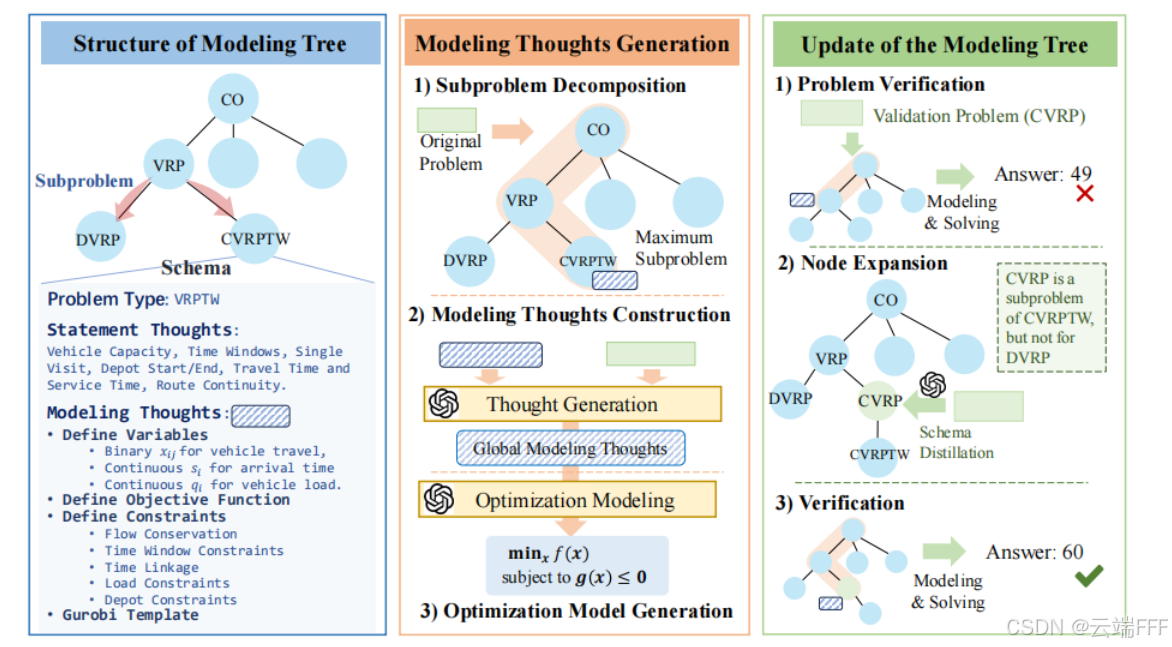
2.2 建模树
- 作者提出
建模树Modeling tree用于问题分解,每个节点代表一种 OR 问题,其中存储着这类问题的模式schema,可以用来指导 LLM 完成相应 OR 问题的数学建模和求解代码生成建模思路Modeling Thoughts:复杂 OR 问题的变量定义与约束构造等涉及许多传统建模技巧,会给推理带来显著挑战。针对该问题,作者将这些建模技巧提炼为简洁、逐步的建模指南。问题****的建模思路 包含变量定义、约束构造、目标构造以及 Gurobi 代码模板等内容。和 In Context Learning 设置静态示例不同,Modeling Thoughts 更灵活,可泛化到具有相似数学结构的多种复杂问题。建模树Modeling tree:建模树根据从属关系将各类 OR 问题组织为层次化的树结构,树的上层由更简单、更基础、易建模的 OR 问题构成,而更深层则对应更复杂的变体,越靠近根节点,对应越基础和通用的 OR 问题,更容易作为复杂问题的 “公共子问题”。建模树中,子节点继承父节点的基础约束与变量,并在此基础上增加专门组件(例如 )。不同于现有 prompt-based 方法和 fine-tuned 方法将每个 OR 问题视为彼此独立,建模树将相似问题组织在同一分支上,便于高效搜索子问题模式schema:为实现建模思路的高效检索和应用,建模树节点中存储的 schema 中包含三个关键要素:- 问题类别名称
- 用于问题识别的陈述思路
- 用于指导建模过程的建模思路
2.3 建模思路的搜索与构造
- 给定待建模 OR 问题 ,OptiTree 从建模树根节点出发,先用陈述思路的语义包含关系筛掉不满足子问题条件的候选,再在当前节点的子节点中选择与最相似的子问题并递归向下搜索,从而在建模树上得到一条复杂度递增的子问题序列 ,其中 是第一层搜索到的节点, 包含了前面各个子问题的建模思路,因此称其为
最大子问题maximum subproblem。将最大子问题建模思路与 的问题描述结合构造全局建模思路 ,输入 LLM 完成 的数学建模和代码生成 - 具体搜索过程如下:
- 使用 LLM 提取 的陈述思路
- 从根节点出发,在第一树层级的所有问题 中寻找第一个子问题:
其中 为指示函数,条件为 True 取 1,否则取 。 表示由 LLM 给出的相似度分数,用于衡量两个问题之间的相似性
用于在树搜索的每个步骤中选择最佳匹配的子问题。它使用详细的提示要求 LLM 比较一系列陈述思路,并以 JSON 格式返回最相似的一个,输出结果包含为离散分数 {0,1,2},其中 2 表示高度相似。
- 从选出的子问题 的所有子问题中继续搜索属于 的子问题
- 递归迭代步骤 3,直到所有子节点都不是 的子问题为止,停止搜索
- 若搜索在根节点即停止,则不提供建模思路,直接用 LLM 根据 的问题描述完成建模和代码生成
2.4 建模树的构建
- 建模树的构建:用一个包含问题描述及其对应真实数学建模的数据集来构建建模树。对于数据集中每个 OR 问题**,首先根据 2.3 节方法进行子问题树搜索,识别最大子问题 ,提取其建模思路 ,结合 问题描述蒸馏构全局建模思路 (由 LLM 根据 meta-prompt 生成),输入 LLM 完成 的数学建模和代码生成(由 LLM 根据 meta-prompt 生成),求解得到最终答案。若答案正确,表明建模树可以成功处理该类问题;否则说明出现了新的分解模式或建模思路,需要用失败问题 更新建模树,进行节点扩展**
实践中,从 ORLM 训练数据 OR-Instruct 3K 数据集从随机抽取 400 个问题构建 Modeling Tree,该数据覆盖广泛的 OR 问题
- 节点扩展:进行节点扩展时需要保持建模树的层级关系,因此 应当作为最大子问题 的子节点。首先为失败问题提炼其建模 schema 三要素,然后验证 与 子节点 间的子问题从属关系。若 ,则将 插入为 子节点,并作为 的父节点;否则,将 插入为 子节点,作为现有子节点的兄弟节点。新增节点后,重复执行分解与建模流程以验证新节点的正确性,直至问题 能够被准确建模为止
为失败问题提炼 schema 时:
- LLM 根据问题描述 + 父节点 基本类型 + 父节点陈述思路 生成该节点陈述思路 + 问题类型
- LLM 根据问题类型 + 陈述思路 + 问题描述 + 求解步骤(来自真值数据)生成该节点建模思路
2.5 LLM 使用时机小结
-
OptiTree 方法流程可以概括为两个阶段:离线建模树构造/更新阶段:用带真值的建模数据自动蒸馏并扩展树节点的 schema,使树覆盖更多问题谱系与建模技巧;在线的新问题求解阶段:在固定的建模树上做子问题树搜索,检索最大子问题的建模思路并合成全局思路,从而指导 LLM 生成最终模型与代码
-
建模树构造/更新阶段(离线,有真值数据,用于扩树)

- 提取树搜索所需的陈述思路
- 时机:对数据集样本先跑树搜索/判定
- 输入输出:问题描述
- 子问题判定 + 相似度打分(用于树搜索找最大子问题)
- 时机:逐层在子节点中选择路径,确定最大子问题
- 输入输出:候选子节点 是否子问题 + 得分 (递归得到)
- 全局建模思路合成 + 最终建模生成(用于验证/构建流程)
- 时机:用最大子问题的建模思路 构造全局建模思路 ,生成模型并求解,用于判定“对/错”
- 输入输出:
- 全局建模思路生成: + 问题描述
- 代码生成:问题描述 + 求解器代码
- 失败样本的 schema 蒸馏(扩树时才触发)
- 时机:用现有树指导建模后求解结果与真值不一致 → 生成新节点
- 输入输出:
- 陈述思路 生成:问题描述 + 父节点 basic type + 父节点陈述思路 + 问题类型
- 建模思路 生成:问题描述 + 问题类型 + + solution step(来自真值数据)
- 插入新节点并维护层级关系(扩树时才触发)
- 时机:失败问题蒸馏 schema 后,将其作为新节点插入最大子问题 下,并与其子节点比较子问题关系以决定插入位置
- 输入输出:
- 输入:失败问题 schema + 类型 + + 子节点类型 + 子节点陈述思路
- 输出:子节点 中满足 的子节点集合(为空则插入为兄弟节点,否则插入为这些节点的父节点)
- 提取树搜索所需的陈述思路
-
新问题求解阶段(在线,无真值数据,树通常固定)

- 提取树搜索所需的陈述思路
- 时机:对新问题启动树搜索
- 输入输出:问题描述
- 子问题判定 + 相似度打分(树搜索路径)
- 时机:逐层选出子问题链并确定最大子问题
- 输入输出:候选子节点 是否子问题 + 得分 (递归得到)
- 全局建模思路合成+ 最终建模生成
- 时机:用最大子问题的建模思路 构造全局建模思路 ,生成模型并求解
- 输入输出
- 全局建模思路生成: + 问题描述
- 代码生成:问题描述 + 求解器代码
- 提取树搜索所需的陈述思路
3. 实验
3.1 实验设定
-
7 个数学建模数据集,统计表明不同数据集的子问题分布差异很大
名称 说明 NL4Opt 289 个入门级线性规划问题 MAMO EasyLP 652 个简单线性规划问题 MAMO ComplexLP 211 个复杂优化问题 ComplexOR 19 个源自教材、论文和工业环境的困难问题 IndustryOR 100个来自8个行业的真实问题,分为 Easy、Medium、Hard OptiBench 605 个问题 OptMATH 166 个困难问题 -
7 个 prompt-based 基线,4 个 fine-tuned 基线
名称 类型 说明 Standard prompt-based 预训练 LLM 直接输出 CoT prompt-based 将问题分解为推理步骤思维链 CoE prompt-based 多智能体建模工作流,智能体分别聚焦于问题理解、问题表述、求解代码编写与调试 OptiMUS prompt-based 一种改进的多智能体工作流,带结构化问题输入 MCTS prompt-based 使用蒙特卡洛树搜索,在不同搜索深度下依次搜索变量、约束与目标 DeepSeek-r1 prompt-based / OpenAI-o1 prompt-based / ORLM fine-tuned base LLaMA-3-8B骨干网络 Evo-Step fine-tuned base LLaMA-3-8B骨干网络,结果摘自论文 OptMATH fine-tuned base Qwen2.5-32B骨干网络,结果摘自论文 LLMOPT fine-tuned base Qwen1.5-14B骨干网络 -
指标:使用
solving accuracy求解准确率指标,即生成的优化模型所得到的最优目标值是否与真值一致 -
实现:
- 使用 OR-Instruct 数据集中随机选取的 400 个问题构建建模树;
- 使用 DeepSeek-V3 和 GPT-4o 两种 LLM
3.2 主结果
-
在 7 个数据集上,使用 DeepSeek-V3 与 GPT-4o 评估 OptiTree,并与具有竞争力的基线比较
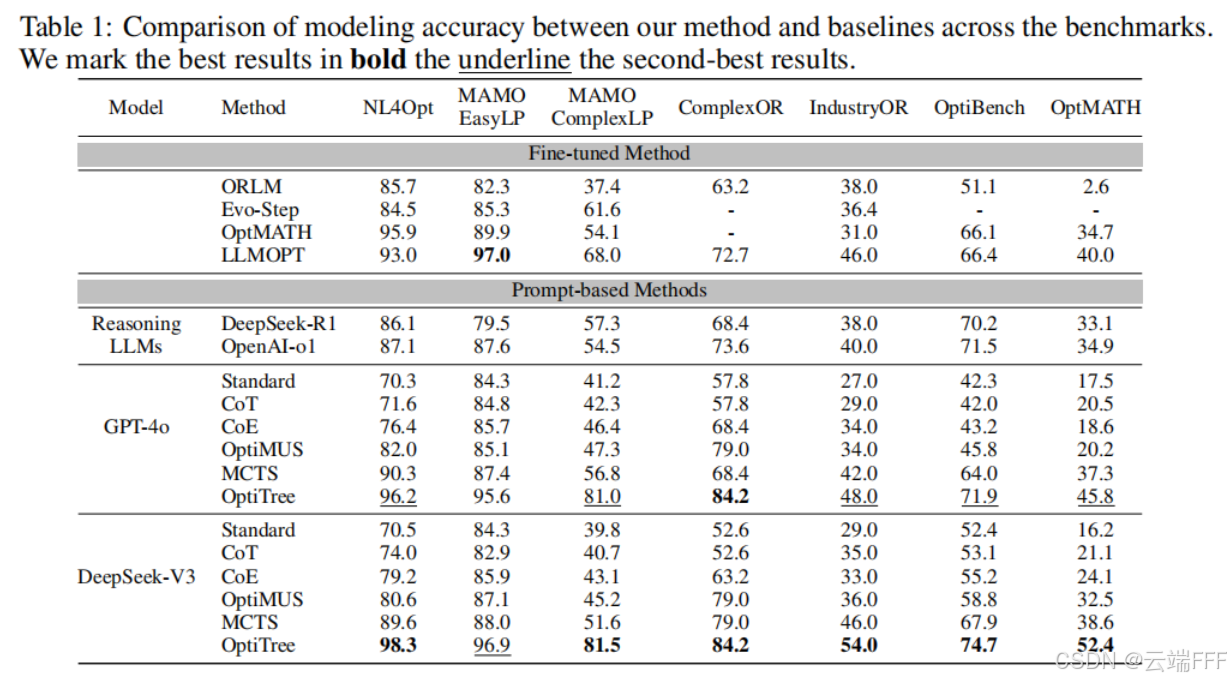
- 高准确率:OptiTree 显著优于基线方法,在 MAMO ComplexLP、ComplexOR 和 IndustryOR 等具有挑战性的数据集上取得约 10% 的提升;优于 fine-tuned based 方法和 DeepSeek-R1 等推理 LLM,
- 强泛化能力:仅使用 400 个问题构建出的 OptiTree 在简单与困难问题上都表现出强泛化能力
- 适配不同 LLM:OptiTree 稳定适配两种不同 LLM,并取得了令人印象深刻的性能。
3.3 子问题分解能力
-
下图显示了 OptiTree 的子问题分解质量
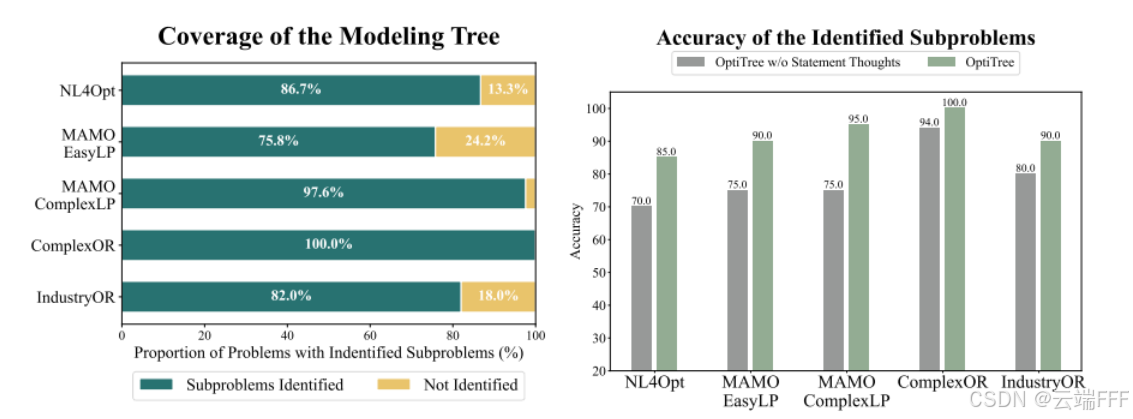
- 覆盖率(在搜索过程中能否找到子问题):左图显示 OptiTree 识别子问题的成功率均值达到 88%(不含根节点)。说明复杂多样的 OR 问题中仍存在能跨问题泛化的常见分解模式与建模技巧,建模树能够成功捕获这些模式
- 可靠性(得到的子问题是否与原问题正确匹配):从每个数据集随机抽取 20 个可识别至少一个子问题的问题,人工检查子问题是否合适且相关。右图显示,当仅依靠问题描述而非建模思路识别子问题时,识别准确率大幅下降
-
下图显示了 OptiTree 的时间开销,其中 Tree search 代表搜索建模树找到合适子问题的耗时,Modeling 表示结合 完成建模的耗时,Inference 表示求解问题总时间
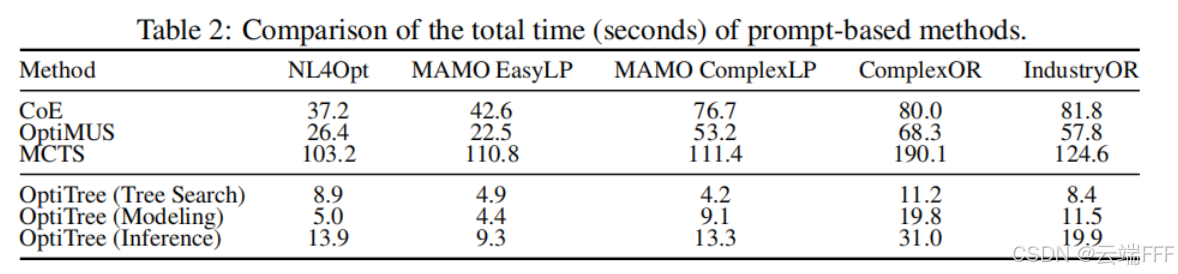
- 对 OptiTree 而言,时间成本包括 “一次性的建树成本 + 推理时间”
- OptiTree 的推理时间在基线中最短,说明层级化子问题树约束了每一步的搜索空间尺寸,且其不存在多 Agent 系统的无效调用时间成本
- OptiTree 跨基准的一次性时间成本小于 3 小时
3.4 消融研究
-
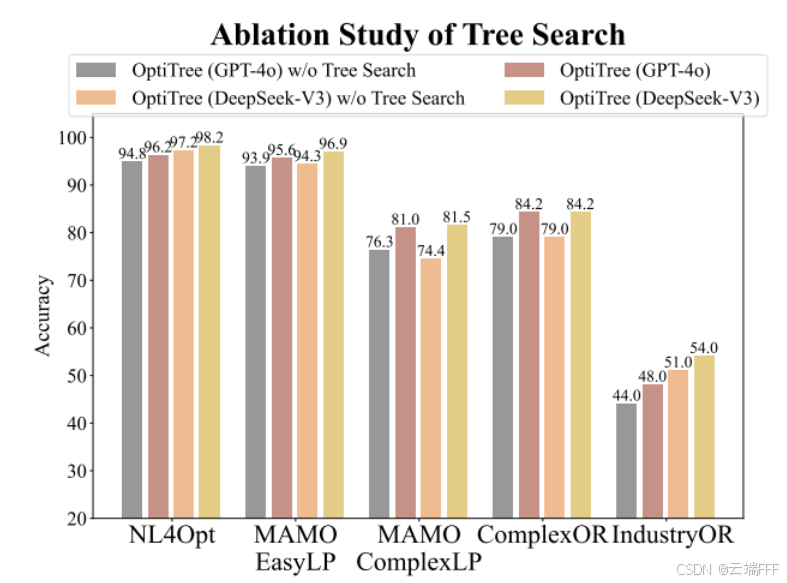
树搜索是关键组件:去掉树结构/树搜索(OptiTree w/o Tree Search)会明显降低建模准确率,说明树搜索能有效缩小搜索空间并减少幻觉
-
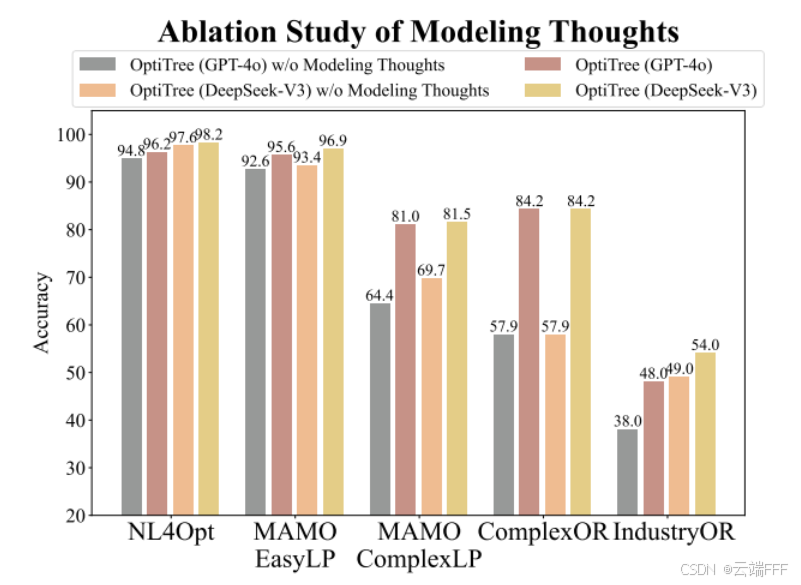
建模思路至关重要:不使用建模思路(OptiTree w/o Modeling Thoughts)性能显著下降,且在更难数据集上降幅更大
-
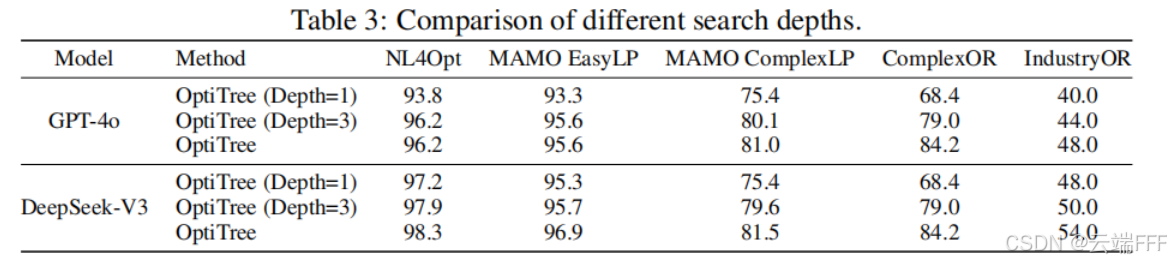
更深的搜索通常更好:限制搜索深度会降低效果;深度越大越容易找到更合适的子问题分解,从而提升性能
-
描述思路提升子问题匹配与整体性能:移除 statement thoughts 会显著掉点,并导致子问题匹配准确率下降,说明其能提供更清晰的信息表示、降低幻觉

4. 总结
- 本文提出的 OptiTree 是一种 prompt-based 优化建模方法,其通过动态更新建模树来存储子问题的分解模式与建模思路,并采用树搜索算法在每一步识别合适的子问题。实验结果表明,OptiTree 在多个具有挑战性的建模数据集上持续优于基线方法
- OptiTree “把 OR 建模知识组织成可搜索的层级结构,并用检索到的高层建模思路来约束 LLM”,
- 优势:结构化、可扩展、符合直觉、增益显著
- 短板:关键判别仍是 LLM 软判断,需要能力较强的 LLM、树构建依赖带真值建模的高质量数据、当目标问题不在树覆盖范围、或外接 Pretrained-LLM 质量变化时,方法可能退化甚至引入噪声