论文理解【LLM-OR】——【Step-Opt】Training LLMs for Optimization Modeling via Iterative Data Synthesis and
- 首发链接:论文理解【LLM-OR】——【Step-Opt】Training LLMs for Optimization Modeling via Iterative Data Synthesis and
- 文章链接:Training LLMs for Optimization Modeling via Iterative Data Synthesis and Structured Validation
- 发表:EMNLP 2025 Findings
- 代码:samwu-learn/Step
- 领域:LLM OR
- 一句话总结:使用 LLM 对运筹优化问题(OR Problem)建模时,现有基于提示的方法(如 CoT/Reflexion/CoE)在复杂 OR 优化建模任务上仍不稳定,而现有微调路线(如 ORLM)受限于高质量建模数据的获取与质量控制。本文提出 Step-Opt-Instruct 数据合成框架,通过 “迭代式问题生成” 逐步提升问题复杂度/扩展覆盖,并用 “分步验证” 在生成阶段过滤错误、防止错误传播,从而构建高质量微调数据并训练得到 Step-Opt,使开源 LLM 在 NL4OPT、MAMO、IndustryOR 等基准上,尤其在困难问题上取得显著提升
- 摘要:大型语言模型(LLMs)已经革新了多个领域,但在处理运筹学(OR)的优化建模任务时仍面临重大挑战,尤其是在应对复杂问题时。本文提出 Step-Opt-Instruct,一个用于扩增现有数据集并生成面向优化建模的高质量微调数据的框架。Step-Opt-Instruct 采用迭代式问题生成来系统性地提升问题复杂度,并通过分步验证对数据进行严格核验,从而防止错误传播并确保生成数据集的质量。基于该框架,我们对开源 LLM 进行微调(包括 LLaMA-3-8B 和 Mistral-7B),从而得到 Step-Opt——一个在 NL4OPT、MAMO 和 IndustryOR 等基准上达到最先进性能的模型。大量实验表明 Step-Opt 具有更优的表现,尤其在解决复杂 OR 任务时优势显著:在困难问题上,其 micro average accuracy 提升了 17.01%。这些发现突显了将结构化验证与渐进式问题细化相结合、以推进使用 LLM 自动化决策过程的有效性
1. 背景
1.1 运筹问题建模
- 本文研究复杂运筹学问题 (OR Problem) 的自动建模与编程,以减轻对人类专家的严重依赖。具体而言,这类问题要求输入一段自然语言描述的问题(如配送货、生产规划等问题),要求模型或系统完成运筹学建模,并生成问题求解代码。近期研究常借助 LLM 丰富的领域知识完成建模,主要存在两类方法:
- 基于提示的建模prompt-based modeling:通过为 GPT-4 等大规模预训练 LLM 精心设计建模 Prompt 实现数学建模和代码生成
- 基于微调的建模fine-tuned LLM modeling agents:通过构造大规模运筹学及建模知识对 LLM 进行微调,形成专用的建模语言模型。这里的代表性方法是 ORLM,其使用通用 prompt 模板驱动 LLM 对种子问题的约束、目标、问题描述方式和建模技巧进行改写,再使用简单的启发式方法过滤明显低质量的数据(如重复描述、程序无法执行等),多轮迭代后使用构造数据集微调 LLM 进行问题建模和求解
- 本文聚焦于基于微调的方法,针对经典方法 ORLM 存在的问题进行改进
- 针对 ORLM 偏半自动化,缺乏有效错误过滤机制的问题,提出一种新的错误自动识别纠正方法
- 针对 ORLM 对所有问题使用通用 Prompt 模版,缺乏精细提示的问题,提出一种新的数据合成方法
1.2 数据增强
- 数据增强是指当领域数据不足时,通过构造合成数据集提高模型性能,是监督学习领域的一种常见做法
- ORLM 通过修改和重述扩展行业案例数据集
- ReSoCratic 采用逆向数据合成方法,从解决方案反向生成优化问题场景描述
- Evol-Instruct 针对通用 LLM 指令微调任务构造数据,从增加指令深度(通过增加约束、加深要求、具体化、增加推理步骤等方式把问题复杂化)和扩大指令广度(基于原指令生成主题/任务不同的新问题)两方面进行数据增强,提升覆盖面与多样性
- 本文方法 Step-Opt 可以看作在 Evol-Instruct 的深度/广度进化范式上,针对 OR 建模引入结构化验证与领域算子的扩展版本
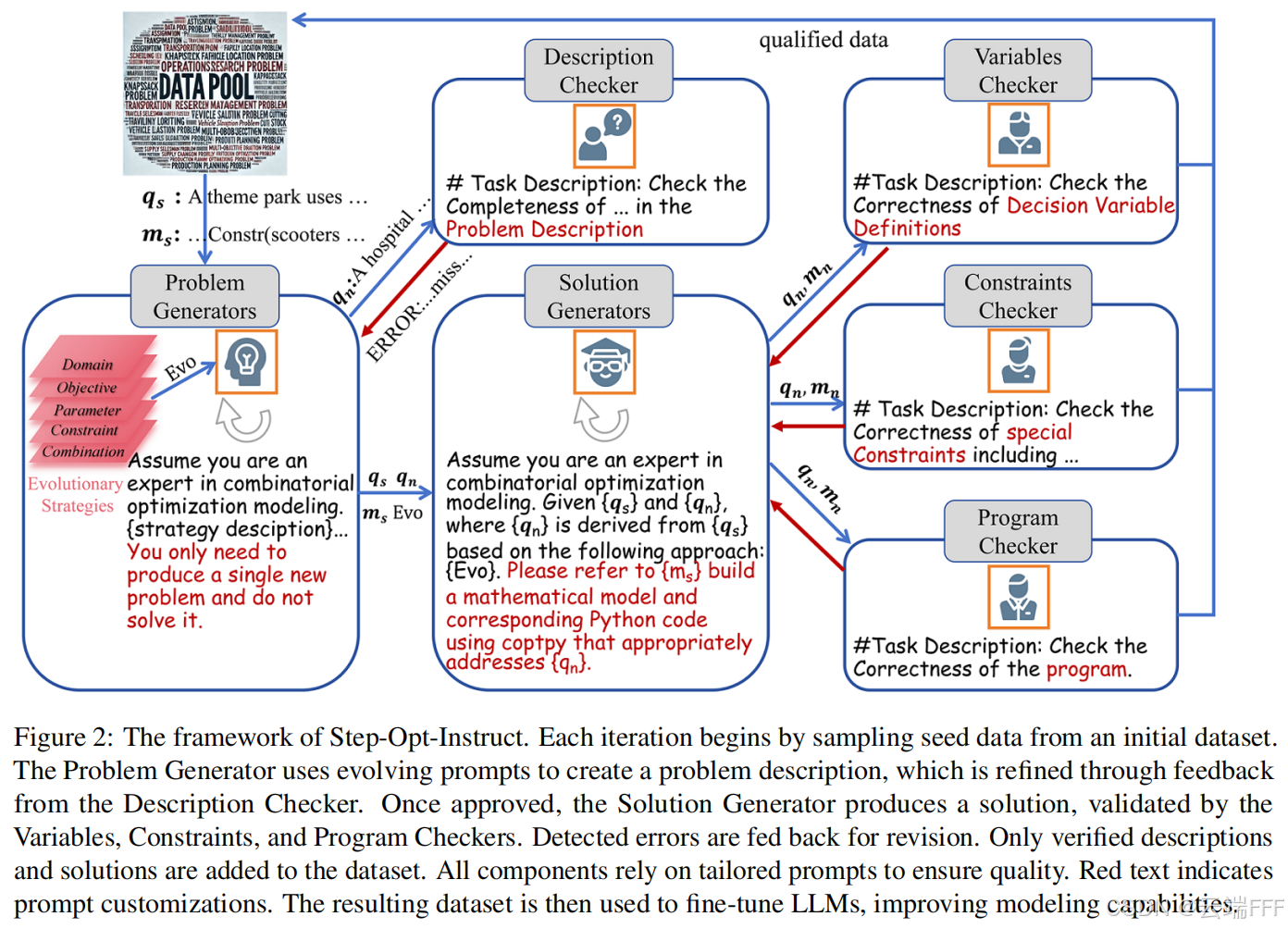
2. 本文方法
2.1 问题生成器
-
Step-Opt 设计了类似 Evol-Instruct 的问题生成机制,从增加问题复杂度和迁移问题领域两个角度扩展训练数据。具体而言,首先需要准备一组种子数据集 每个种子问题由问题描述 和对应数学建模及程序 组成,每次迭代从 随机采样一个种子数据 ,然后使用某种特定的进化方法 将其改写为新问题,形式化表示为
改写过程是使用 prompt 驱动 LLM 完成的,改写方法可以分为
复杂度进化 Complexity-Evolving与范围进化Scope-Evolving两类 -
复杂度进化:针对 OR 问题特性,通过约束修改、目标改变和参数调整三种修改方式修改已有条件或引入新元素,在保持逻辑一致性的同时逐步提高问题难度。为了避免生成的问题过于复杂,限制对约束或目标的修改最多只允许一项,参数调整最多引入一个新实体
-
约束修改:修订已有约束或添加新约束以增强问题。其核心原则是 “在保留逻辑结构的前提下,基于给定问题修改约束”,从而在复杂度增加时保持问题基本逻辑不变

-
目标改变:修改目标或引入新目标,但限制为 “不能仅仅调整系数”

-
参数调整:改变数值或添加元素;与上述方法一样,其共同原则是保留底层结构,并从不同角度提升问题难度

-
-
范围进化:通过将种子样本转换到不同领域,或将其与另一条样本组合生成新场景,以扩展主题覆盖与多样性
-
领域转换:将原问题的基本结构迁移到新领域,同时保留其逻辑与约束,从而提升语言与上下文多样性。为保证实际相关性,作者定义了一组参考领域列表

-
组合:将两个不同问题合并成一个新问题,新问题属于不同领域并包含新的细节;这种方式带来更大的变化。为控制复杂度,要求新问题长度与其中一个原问题相近,以保持难度可控

-
-
综上,Step-Opt 中的问题构造示意图如下,其中红色表示 “”“复杂度进化”,蓝色表示 “范围进化”

2.2 解答生成器
- 使用 2.1 节方法合成新问题 后,解答生成器利用原始问题 和进化方法信息 作为参考,为新问题生成数学建模与求解程序 ,形式化表示为
由于 LLM 可能难以处理复杂模型,作者在 meta-prompt 中加入指令:“确保格式与结构尽可能与给定的 保持一致
2.3 分步验证机制
-
使用 2.1 和 2.2 节的方法可以对种子数据集进行有效扩展,由于 OR 建模的复杂性,仍很能存在参数确实、优化目标含糊或高级技巧误用等问题,若缺乏足够的监督与纠错机制,这类问题往往会持续存在,逐步破坏数据集质量并影响模型表现,特别是在 bootstrap 迭代构造数据集时,错误数据会不断传染,导致数据质量下降
-
针对该问题,Step-Opt 使用分步验证机制在生成过程中持续检查,剔除低质量或错误数据以维持数据集完整性。该机制包含四类检查器,分别聚焦于:描述完整性、变量定义、约束实现与程序质量,具体如下
-
描述检查器 description checker:评估生成的 是否包含必要组成部分(优化目标、约束条件、参数变量和数值)。若缺失,则提供反馈并触发重新生成,直到验证通过或达到尝试次数上限。只有通过该检查后,解答生成器才会生成数学模型与程序。重新生成模板如下

-
变量检查器 variables checker:在交叉参考 与 的基础上,提供分步指令,并给出覆盖常见类型的示例,使其能够核验变量定义是否正确
这个模板论文没给,在源码中是有的,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32#Task Description: Check the Correctness of Decision Variable Definitions
##Solution Description: To check the definitions of decision variables in a "## Mathematical Model:" for a combinatorial optimization problem, follow this structured approach:
**Important: The checks must be based on the problem description and common sense. No assumptions or conjectures should be made. The conclusions must be justified by the problem description or common sense.**
###Step 1: Extract Decision Variable Definitions
1. In the "## Mathematical Model:" Find definitions under "### Decision Variables".
2. In the "## Python Code Solution Using coptpy:" Identify definitions where "model.addVar" is used.
###Step 2: Confirm Consistency with Problem Description
1. Ensure each variable's type and bounds align with the problem's actual meaning.
###Step 3: Confirm Variable Types and Bounds
Note: The examples provided below are not exhaustive. Specific examples should be analyzed based on their actual meaning in the context of the problem.
1. **Integer Variables (Bounds > 0): Examples of integer variables include the number of people (human resource), quantity(production quantity, the number of items produced, inventory quantity), event count, service count, product count, dose count, delivery count, number of vehicle trips, number of selections, number of machines, number of shifts, number of tasks, number of projects, number of batches, number of visits, number of orders, number of repairs, number of maintenance activities, number of inspections, number of tests, number of installations, number of calls, number of meetings, number of training sessions.**
2. **Binary Variables (0 or 1): Examples of binary variables include attendance, binary choices, facility opening decisions, allocation decisions.**
3. **Continuous Variables: Examples of continuous variables include length (like kilometre、metre、decimetre、centimetre、millimetre、micron, etc.), area (square meters, hectares, square kilometers, etc.), distance ( meter, kilometer, mile, centimeter, millimeter, micrometer, nanometer, inch, foot, yard, nautical mile, light-year.), time (second, minute, hour etc), amount of money, weight (e.g., gram, kilogram, ton), volume (e.g., liter, cubic meter), temperature (e.g., degree Celsius, degree Fahrenheit), speed (e.g., meters per second, kilometers per hour), energy (e.g., joules, kilowatt-hours), power (e.g., watts, kilowatts), pressure (e.g., pascals, bar), flow rate (e.g., liters per second, cubic meters per hour), concentration (e.g., molarity, parts per million).**
4. **Continuous Variables with Range: Examples of variables with range include proportions or percentages (0 to 1).**
###Step 4: Check the Python Code Solution Using coptpy
1. For integer variables: Ensure vtype=COPT.INTEGER.
2. For continuous variables: Ensure vtype=COPT.CONTINUOUS.
3. For binary variables: Ensure vtype=COPT.BINARY.
### Output Format:
**If there are no errors, output: "There are no errors found."
If there are errors, output the specific errors with the format "ERROR:" and how to fix them.**
Please check for any errors in the decision variable definitions based on the steps above. Make sure to especially reference the examples listed in '###Step 4'. Use #Examples as reference (Note that for ease of description, we will use the parts unrelated to decision variables as replace in #Examples). **Do not repeat the prompt, only provide the errors and fixes if any, or confirm there are no errors.**
**Input**:
{problem_with_completion}
#Example1:
{example1_input}
{example1_output}
#Example2:
{example2_input}
{example2_output} -
约束检查器 constraint checker:确保约束被正确建模并与问题描述一致。这里会使用一个标准检查流程是:先识别约束,再验证其与问题内容一致性,类似变量验证。特别地,约束检查器会将 Big-M 方法、K-way 选择约束 等高级技术作为专门检查项给予特别关注;其他高级技术也可按此方式纳入检查

-
程序检查器 program checker:抽取并执行程序,捕获输出或错误
-
-
以上所有检查步骤中,描述检查器在 2.1 节所述问题生成后即进行检查和重新生成,仅在通过检查时利用 2.2 节所述的解答生成器生成解。然后用变量检查器、约束检查器和程序检查器进行检查,查出的错误也反馈给 2.2 节描述的解答生成器重新生成解,直到通过所有检查或达到最大纠正次数为止。整体错误纠正流程如下图所示
解答生成器纠错 prompt 模版如下

-
Step-Opt 与 Chain-of-Experts(CoE)等多智能体框架的区别在于
- CoE 使用相互独立的 “专家”,每个专家解决一个完整子任务(例如,一个专家创建整个模型)
- Step-Opt 采用更细粒度、集成式的系统。检查器验证解答中的特定组成部分——例如变量或约束——而不是整项任务。这种组件级验证不仅更精确,而且在计算成本与 token 使用量方面显著更高效,使其特别适用于迭代式数据生成
3. 实验
3.1 实验设定
- 数据集与清洗:作者在简单与复杂两类基准上评测:NL4OPT、MAMO EasyLP、MAMO ComplexLP、IndustryOR,并说明对答案/标注进行了必要的人工修订
- NL4OPT:共 1,101 个简单 LP,其中 289 用于评测 ;作者修正了 16 个不准确实例
- MAMO:含 EasyLP(652 个简单 LP)与 ComplexLP(211 个复杂 LP),都配有最优解;作者修正了 78 个不准确实例
- IndustryOR:100 个复杂 OR 问题;因缺少关键信息或数值不准确,作者进行了 50 处修正,并移除了 23 个不满足建模标准的实例
- Baselines方法
- tag-BART(NL4Opt 竞赛冠军模型)
- Prompt 方法:Standard / CoT / Reflexion
- 多智能体提示:Chain-of-Experts (CoE)
- 微调模型:ORLM(从 ORLM-LLaMA-3-8B ckpt 开始,用 OR-Instruct-Data-3K 数据进行微调;该 3K 数据也用于消融)
- 评测设置与指标
- 所有方法评测时 temperature=0;微调模型在 zero-shot 下用 greedy decoding,取 top-1 completion 作为解,确保对比公平
- 推理最大生成长度 2,048 tokens
- 指标:用生成程序输出 与真值 的相对误差阈值判等:
其中 防止除零;满足则认为等价
- 训练数据构造与微调:从 260 个例子出发,进行 8,400 次迭代,用 GPT-4-turbo-0409 得到 4,464 个例子;随后用 LLaMA-Factory + Alpaca 模板 + LoRA 微调 LLaMA-3-8B 与 Mistral-7B(输入为固定 prompt+问题描述,输出为数学模型+程序)
3.2 实验结果
-
在 NL4OPT、MAMO EasyLP、MAMO ComplexLP、IndustryOR 上的准确率,以及 micro/macro 平均(其中 tag-BART 的结果为引用原论文)结果如下图所示
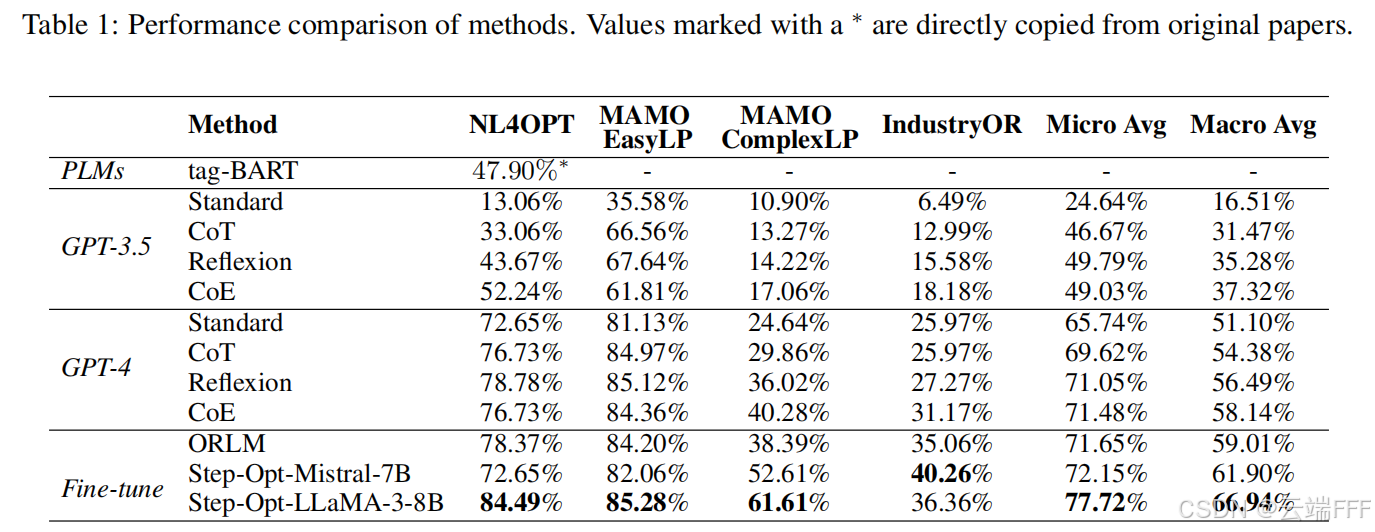
- Step-Opt-LLaMA-3-8B 在所有基准上达到最佳
- 微调模型(ORLM、Step-Opt)整体上平均优于纯 prompt 工程方法;但在简单数据集(NL4OPT、EasyLP)差距较小,而在复杂数据集上优势更明显
- 论文指出:复杂问题描述更“繁琐”,且需要更高级建模技巧,因此 Step-Opt 模型在复杂任务上体现出更强的处理能力
3.3 消融实验
3.3.1 不同进化方法的贡献
-
针对 2.1 节提出的 5 种数据扩展方法进行消融实验
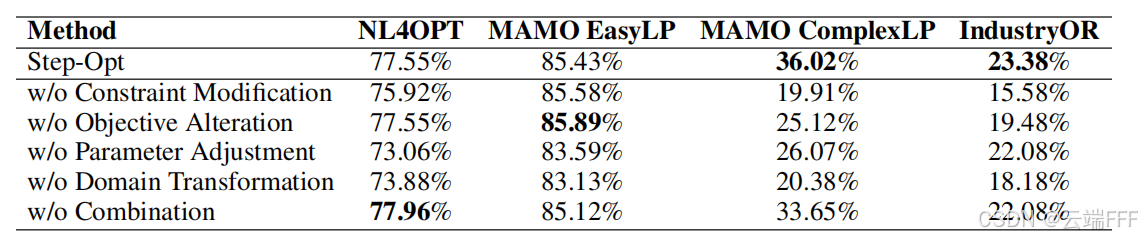
- domain transformation 对所有数据集有显著影响,显示其关键性
- parameter adjustment 更影响简单集
- constraint modification 与 objective alteration 对复杂集影响更大,特别是 constraint modification 会引入更多约束、提升难度,从而帮助模型学习复杂条件
-
此外作者统计了不同生成方式的 “ 通过验证样本数”:发现组合最难、易失败;参数调整与领域变换相对更容易通过验证
- constraint modification 1,716;
- objective alteration 1,242;
- parameter adjustment 2,123;
- domain transformation 2,077;
- combination 455
3.3.2 训练样本是否包含 “数学模型”
- 每条训练样本的解 都包含 “数学模型 + 对应 COPT 程序”,虽然最终求解依赖程序,但移除数学模型会导致性能显著下降;为排除 token 数差异影响,控制总 token 数为 4.73M,仍然是 “包含数学模型” 的数据更好
Step-Opt 的数学建模是 “给人看的公式/说明体裁”,latex 格式存储,形如
1
2
3
4
5
6
7
8
9## Mathematical Model:
...(自然语言说明)
### Decision Variables:
- \(x_i\) ...(LaTeX/符号)
### Objective Function:
- Minimize ... \(Z = ...\)
### Constraints:
...
## Python Code Solution Using coptpy: - 作者认为数学模型是一种 “结构化推理桥梁”,类似 CoT,能帮助从问题描述过渡到代码解

3.3.3 数据集对比
-
对比了使用 OR-Instruct(ORLM 的数据)和使用 Step-Opt-Instruct 数据集微调 LLM 的效果,都取 3,000 条样本训练 LLaMA-3-8B

如图所示,除 MAMO EasyLP 外,Step-Opt 在其余数据集与 micro/macro 平均上优于 ORLM,且在复杂集(ComplexLP、IndustryOR)增益更明显
4. 总结
- 本文提出 Step-Opt-Instruct 框架属于一种 OR 垂直领域的数据增广方法,“把数据合成 + 结构化验证” 工程化落到 OR 建模任务上:核心贡献在于把“渐进式生成(进化)” 与 “分步检查器(含反馈重写)” 组合成一个能自动产出可用于微调的数据流水线,并在复杂 OR 基准上取得明显提升
- 本文优点包括
- 对错误纠正这个痛点处理得比较系统,较好地缓解了 ORLM 的痛点问题
- 数据生成策略可控,深度/广度进化被 OR 化为可操作算子
- 做了一个很实用的消融:训练样本里同时输出“数学模型 + 代码”,去掉数学模型会掉点;并把数学模型类比成一种结构化推理桥梁(类似 CoT),帮助从描述过渡到代码
- 本文缺点包括
- 创新有限,更多是把已有套路在 OR 建模上做任务化/工程化落地。数据生成部分基本就是把 Evol-Instruct 方法迁移到 OR 任务;错误纠正部分也比较直白,感觉都是比较常规的思路
- 验证机制的覆盖面有限,很难覆盖 OR 中 “种类繁多的建模技巧”
- 数据生成成本与筛除率较高:为 instance generation 做了 64K queries、179M tokens;8,400 次生成只留下 4,464 个样本,约 46.86% 被丢弃,平均每次迭代 7.66 次查询(其中描述生成/验证 3.14、solution 生成/验证 4.52)。如果换更复杂基准或更复杂技巧,成本可能进一步上升